detected by applying sobel operator on the image.
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 283
ISSN 2229-5518
ABSTRACT - Text embedded in natural scene images contain large amount of useful information. Extracting text from natural scene images is a well known problem in image processing area. Data which appear as text in natural scene images may differ from each other in its size, style, font, orientation, contrast, background which makes it an extremely challenging task to extract the information with higher accuracy. Many methods have been suggested in the past but the problem is still the challenging one. This paper presents an approach to extract the text in scene images with higher precision rate and recall rate.
KEYWORDS: Text, Images, Data, Extract, ICDAR 2003
1. INTRODUCTION
Today, most of the useful information is available into the text which is present into the natural images. For eg. Name of the brand embedded into clothes, text written on the nameplates, signboards etc. Extracting the text from these images is still a difficult task. There should be some mechanism to extract the text from natural images. Recent studies show some methods to extract text from images but the approach didn’t worked fine for characters which are small in size. In this paper we have presented an approach which will extract the small sized characters and the approach works well with the text which is present into the noisy images also. Data from ICDAR dataset 2003 is being tested.
2. PREVIOUS WORK
[1] Kim K.C, Byun, H.R ., Song Y.W, Chi, S.Y, Kim, K.K, Chung Y.K presented method that extracts text regions in natural scene images using low- level image features and that verifies the extracted regions through a high-level text stroke feature. Then the two level features are combined hierarchically. The low-level features are color continuity, gray-level variation and color variance. [2] Shivananda V Seeri, Ranjana B Battur, Basavaraj S Sannakashappanavar presented a method to extract characters from natural scene images. Algorithm works well with the medium sized characters. [3] Xiaoqing Liu et al. proposed “Multiscale edge based text extraction from
complex images”, method
which automatically detects and extracts
text present in the complex images using the multi
scale edge information. This method is robust with respect to the font size, color, orientation and alignment and has good performance of character extraction. [4] Nobuo Ezaki and Marius Bulacu, Lambert Schomaker presented a text extraction method for blind persons. [5] Xu-Cheng Yin, Xuwang Yin, Kaizhu Huang, Hong-Wei Hao presented robust text detection in natural scene images. A fast and effective pruning algorithm is designed to extract Maximally Stable Extremal Regions (MSERs) as character candidates using the strategy of minimizing regularized variations.[6] Yang, presented the problem of recognizing and translating automatic signatures.
3. PROPOSED METHOD
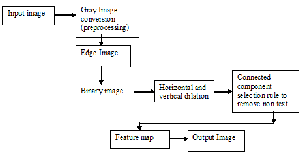
Text extraction method which is being used in our algorithm is edge based method and reverses edge based method. Our method presents an approach which will extract the characters from noisy images and it will extract the small sized characters also. Method is based upon Converting RGB Image into HSI Plane and removing noise if there is any.
3.1 Extracting Characters from Edge Image
In this method edges are detected using sobel operator on each edge. Image after detection is binarized using Otsu’s Binarization and then the dilation and extraction of connected component is done. The method works well with the characters which are small in size
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 284
ISSN 2229-5518
detected by applying sobel operator on the image.
RGB IMAGE
![]()
Image being converted into HSI
Figure 1
3.2 Extracting Characters from Reverse Edge
Image is reversed before dilation and extraction of connected components.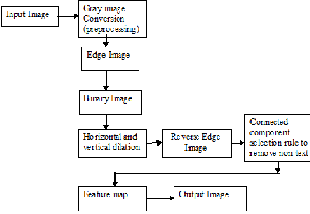
Figure 2
3.3 Combined Approach
OR operation is applied into the image obtained from edge image and reverse edge to remove the noise from the image
Input image is converted into RGB image. Corresponding RGB image is converted into HSI image. The conversion is done using MATLAB operation which takes the RGB image as an input and returns the HSI image. Edges of the image are
Image after edge detection
![]()
Image after edge detection
Image obtained after edge detection is binarized using Otsu’s Binarization and thresholding method.
Binary Image
![]()
Horizontal and Vertical dilations are done to extract the connected components from edge image.
Image after dilation
![]()
Reverse Edge Image
![]()
After extracting connected from edge image and reverse edge image, OR operation is applied on both the method
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 285
ISSN 2229-5518
to remove the noise from the characters and final image is obtained after removing the noise and precision and recall rate are calculated.
Final Image
![]()
Final Image
We have conducted the following test and after conducting the test, precision and recall rate were calculated.
Test 1
![]()
![]()
![]()
RGB IMAGE Image after edge detection Binary Image
4. CONNECTED-COMPONENT SELECTION RULES
![]()
Image after dilation
![]()
Edge Detected Image
![]()
Reverse Edge Image
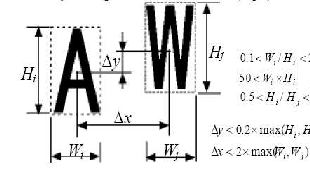
It can be noticed that, up to now, the proposed methods are very general in nature and not specific to text detection. At this point simple rules are used to filter out the false detections. We impose constraints on the aspect ratio and area size to decrease the number of non-character candidates. In Fig. 3, Wi and Hi are the width and height of an extracted area; Δx and Δy are the distances between the centers of gravity of each area. Aspect ratio is computed as width / height. Following rules are used to further eliminate from all the detected connected components which do not actually correspond to text characters.
Final Image
![]()
Test2
RGB IMAGE Image after edge detection Binary Image Image after dilation
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Edge Detected Image Reverse Edge Image Final Image
Test 3
RGB IMAGE Image after edge detection Binary Image
![]()
![]()
![]()
Image after dilation Edge Detected Image Reverse Edge Image
![]()
![]()
![]()
Final Image
![]()
Test4
RGB IMAGE Image after edge detection Binary Image Image after dilation Edge Detected Image Reverse Edge Image
![]()
![]()
![]()
![]()
![]()
![]()
Final Image
![]()
Test5
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 286
ISSN 2229-5518
RGB IMAGE Image after edge detection Binary Image
![]()
![]()
![]()
Image after dilation Edge Detected Image Reverse Edge Image
![]()
![]()
![]()
Final Image
![]()
Test 6
RGB IMAGE Image after edge detection Binary Image
![]()
![]()
![]()
Image after dilation Edge Detected Image Reverse Edge Image
![]()
![]()
![]()
![]()
Test | Precision Rate | Recall Rate |
Test 1 | 100 | 100 |
Test 2 | 98.0769 | 98.0769 |
Test 3 | 100 | 100 |
Test 4 | 100 | 100 |
Test 5 | 100 | 100 |
Test 6 | 98.1818 | 98.0769 |
Overall Precision Rate | 99.38 | |
Overall recall Rate | 99.34 |
Method which is proposed into the paper is compared with the existing text extraction
Algorithms and the following results were obtained.
Method | Precision Rate ( % ) | Recall Rate ( % ) |
Proposed Algorithm | 99.38 | 99.34 |
Shivanand S. Seeri | 98.46 | 97.83 |
Samarabandu | 91.8 | 96.6 |
J. Gllavata | 83.9 | 88.7 |
Wang | 89.8 | 92.1 |
K.C. Kim | 63.7 | 82.8 |
J. Yang | 84.90 | 90.0 |
After Comparing with the other methods, proposed method is better than the existing one and it extracts small sized characters with higher accuracy.
1. Kim K.C, Byun, H.R ., Song Y.W, Chi, S.Y, Kim, K.K, Chung Y.K, “ Scene Text extraction in natural scene images using hierarchical feature combining and verification”
Pattern Recognition, 2004. ICPR 2004.
Proceedings of the 17th International
Conference on page 679-682 Volume:2
2. Shivananda V Seeri, Ranjana B Battur, Basavaraj S Sannakashappanavar “ Text Extraction from Natural Scene Images”, International Journal of Advanced Research in Electronics and Communication Engineering, Volume 1
October 2012
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 287
ISSN 2229-5518
3. Xiaoqing Liu and Jagath Samarabandu,
“Multiscale edge-based Text extraction from
Complex
images,” IEEE, 2006
4. Nobuo Ezaki, Marius Bulacu, Lambert Schomaker, Text Detection from Natural Scene images : Towards a System for Visually impaired Persons, Proc. of 17th Int. Conf. on Pattern Recognition (ICPR
2004), IEEE Computer Society, 2004, pp.
683-686, vol. II,
23-26 August, Cambridge, UK
5. Xu-Cheng Yin, Xuwang Yin, Kaizhu Huang, Hong-Wei Hao , “ Robust Text Detection in Natural Scene Images” IEEE Explore June 2013
6. J. Yang, J. Gao, Y. Zhang, X. Chen and A.
Waibel, “An Automatic Sign Recognition
and Translation System”, Proceedings of
the Workshop on Perceptive User
Interfaces (PUI'01), 2001, pp. 1-8.
7. A.K Jain “ Fundamentals of Digital Image Processing” Englewood Cliff, NJ: Prentice Hall, 1989, Ch 9
8. R.C. Gonzalez, “ Digital Image Processing Using MATLAB”
9. N. Otsu, “A Threshold Selection Method from Gray- Level Histogram”, IEEE Trans. Systems, Man and Cybernetics, Vol. 9, 1979, pp. 62-69
10. S.M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, and R. Young, “ICDAR 2003
Robust Reading Competitions”, Proc.of the
ICDAR, 2003, pp. 682-687
IJSER © 2013 http://www.ijser.org