Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 1, January -2012 1
ISS N 2229-5518
Method of Speech Signal Compression in
Speaker Identification Systems
Raimy Abdourahmane, Konate Karim, Bykov Nikolaï Maximovitch
Abstract— In this paper w e present a technique of eff icacy improvement of speech signal compression algorithm w ithout individual f eatures speech production loss. The compression in this case means to delete, from the digital signal, those quantization steps that can be predicted. We
propose to decrease the number of those quantization steps using a modif ied linear predication algorithm w ith variable order. That allow s to decrease compression time and save computer resource.
Inde x Terms— speech signal compression, quantization steps, linear predication algorithm, computer resource.
—————————— ——————————
1 INTRODUCTION
HE task of efficient r epr esentation of speech signal is one of the vital tasks in speaker identification pr oblems. For example, an automatic speaker r ecognition system is installed on a LAN or WAN server , which author izes a ter- minal to access the networ k according to the voice of the sub- scr iber. Ther e ar e two ways of pr ocessing information in this
case:
1) get the identity featur es of the speaker fr om the
speech signal on the subscr ib er ’s terminal and tr ansfer them to
the server for a decision r egar ding the possibility of admission;
2) compr ess the speech signal, w ithout loosing the
information about the speaker ’s identity, in the form of a passwor d wav-file, and transfer it acr oss the networ k to the server , wher e the identification pr ocedur e is carr ied out .
One of t he advantages of the fir st appr oach is the r eduction of the transmission time over the networ k. Its main drawbacks ar e that it r educes the confidentiality the speaker identification pr ocedur es, and ther e is a need to install on the terminals a system for a pr imary analysis and description of the speaker signals featur es. Thus, the second appr oach is mor e effective for information pr ocessing r egarding the number of computations that ar e r equir ed for the compr es- sion, and the use of ASP-technologies for the selection of informative featur es and for decision-making.
Analysis of known works
Accor ding to the w ell known methods of signal compr ession and given the statistical character istics of the speech signal, the parameters of the analog-to-digital converter s (ADC) ar e ch o- sen according to the r ules pr esented in [1, 2]: the discr etization fr equency is determined by the upper limit fr equency of the signal, the quantification r ange – by the dispersion, the quan- tification step - by the signal to noise r atio and the r equir ed pr ecision. Since the speech signal is not stationary, the par am e-
ter s of the ADC ar e chosen appr oximately using the most catastr ophic situation, w hich is rar ely encounter ed. As a r e- sult, the inher ent r edundancy of the speech signal is com- pleted by the r edundancy of the discr ete transformation. As a r esult a new pr oblem arises: eliminating the ADC’s r edundan- cy. In the numerous var iants of pulse modulation and adap-
tive coding, which ar e used today to eliminate encoding r e- dundancy, the sample rate r emains constant and equals the Nyquist fr equency, and r edundancy is eliminated by analyz- ing the values of neighbor ing signal samples.
The aim of the research
The aim of the r esear ch is to incr ease the efficiency of the algo- r ithm of speech signal compr ession without loosing the infor-
mation related to the personnal peculiar ities of the speaker , by r emoving those samples that can be pr edicted.
2 THEORETI CAL FOUNDATIONS OF T HE PROP OS ED MET HOD
In this w or k we pr opose to r educe the number of signal sam- ples by using the modified method of variable or der linear pr ediction. The peculiar ity of the pr oposed method consists in a two step pr ocessing of the speech signal, w hich allows r e- ducing the time that is necessary for wav-file compr ession. The pr ocess is carried out in two steps:
1.Pr eliminary compr ession;
2. Final compr ession.
At the first stage the w av-file is pr ocessed using an or iginal
technique, which consists in appr oximating the speech signal using a polyline, w ith the possibility to establish the degr ee of its deviation fr om the or iginal signal. At the second stage the wav-file ar eas which w er e not affected dur ing the initial compr ession pr ocedur e ar e appr oximated using a polynomial, whose or der is determined accor ding to the accuracy that is r equir ed to r estor e the speech signal fr om the archive file.
Since the speech signal is a continuous function S (t) , w hose
spectrum is limited by the upper fr equency F, it is defined by the succession of his samples , whose time interval is calcu- lated using the following formula:
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h Vo lume 3, Issue 1 , January -2012 2
ISSN 2229-5518
1
![]()
Tk t .
2F
1; (t t j
where
0; (t t
) 0,
) 0.
Thus the signal
S (t) can be described as follows: j
Appr oximation err or is determined by the
S (t) S (ti ) i (t) S (i t) i (t) ,
r emainder term of inter polation formula. In this case, the seg-
i
i
ment of line in the within the time interval [ t j , t j 1 ] is defined by the expr ession:
where
(t) sin 2F (t i t)
is the sample function
S (t) S (t )
(t t ) S (t
j 1
) S (t )
![]()
,
![]()
i 2F (t i t)
t j 1
t j
and i assumes discr ete value
and the r emaining member of functions expansion at the same interval w ill be:
(t)
1; t i t,
R(t) S (t) (t t
)(t t ),
0; t k t, k i.
![]()
2! j
j 1
For a limited dur ation of the speech signal the number of the signal samples N is defined by the expr ession:
wher e S (t) - the second der ivative of a given function w ithin
the interval.
If it is known that R(t) and S (t) ar e maximal, then
N 2F.
![]()
![]()
![]()
S (t)
max
t j 1 t j
![]()
t
Taking to account the quazzi stationarity of the signal and also
R(t)
max 2!
![]()
.
![]()
![]()
the non critical state of the data collection systems to real time of processing, a method of reduction of the encoding redun- dancy of the speech signal using the ADC has been developed.
Letting Smax R(t) , w e get the formula for the sampling interval
![]()
8 S
Minimization of the error of restored signal consist in the
t *
t j 1 t j
max .
finding those fixed values of the argument t0 , t1 , t 2 ,, t n
S (t)
max
that ensure convergence of broken plot from the vertices S0 , S1 , S 2 ,, Sn towards the function S (t) so that for the entire range of argument changing the absolute error does not
exceed permissible values.
The function S (t) in these points can be presented as follows:
S (t1 ) S0 k1 (t t0 ) for t0 t t1 ,
S (t2 ) S0 k1 (t t0 ) k2 (t t1 ) for t1 t t 2 ,
Asking the upper fr equency of signal bandw idth is
defined w e can determine the deviation of r eal signal value fr om pr edicted. Based on the above, an algor ithm to impl e- ment the pr ocedur e for pr e-compr ession of voice information was cr eated. It includes following steps:
1. Set level of allowable absolute err or of the r ecovery signal ;
2. Set the minimum size M of buffer compr ession;
3. For the curr ent point the coefficient of pr ediction is
determined;
S (t3 ) S0 k1 (t t0 ) k2 (t t1 ) k3 (t t2 ) ,
4. If a deviation of the coefficient
k , w e
for t 2 t t3 ,
wher e k i can be defined as follows :
incorporate curr ent sample in compr ession buffer ,
incr easing the value m of buffer counter by 1 and go
to Item 3, if the inequality is not fulfilled, then check the buffer counter m : if m M then set m 0 and
k tg
S1 S 0 ,
go to to Item 3; if
field;
m M then compr ession is full
![]()
1 1 t
![]()
![]()
k S2 S1 S1 S0 ,
5. If end of w av-file not found, then go to Item 3.
Linear pr ediction used for the r ealization of the
pr ocess of the second step of compr ession [3,4] .The signal
t2 t1
t1 t0
S (t) is pr esented in a digital for m S n ,
n 1,2,, N , wher e
![]()
![]()
![]()
k S3 S2 S2 S1 S1 S0 ,
N is number of signal samples, which is obtained by
t3 t2
t2 t1
t1 t0
sampling it at a cer tain fr equency F. This signal
S n ,
In gener al:
n 1,2,, N ,can be pr esented as a linear combination of
S (t ) S 0
n
k
j 0
j 1
(t t
) sign(t t
),
pr eceding values of the signal and some influence u n
p
Sn ak Snk G un
k 1
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h Vo lume 3, Issue 1 , January -2012 3
ISSN 2229-5518
wher e G is the amplification coefficient and p is the or der of pr ediction.
Then, know ing the values of signal S n , the pr oblem r educes
to sear ching the coefficients ak
and G . Concer ning the est i-
mate, w e w ill use the least squar e method assuming the signal
S n as deterministic.
The values~of signal S n w ill be expr essed thr ough his estimating values S n by the following formula :
~ p
Sn ak Snk .
k 1
Then the pr edicion err or can be descr ibed as follows:
p
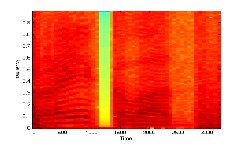
Fig 2 : The spectr ogram of wave-file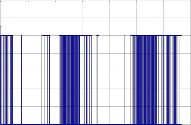
1.4
e S ~ S
ak Snk .
1
1.2
1
k
Using the least squar e method, the parameter s ak
ar e selected
0.8
so as to minimize the average or the sum of squar es of the
pr ediction err or. In or der to find the coefficients ak , let us use the matr ix method [5,7] called as Darbin method.
Calculation of the coefficients of linear pr ediction and the
pr ediction err or is per formed by the follow ing algor ithm: of
coefficients of linear pr ediction and pr ediction error is:
1. The segmentation of the speech signal at stationary
intervals;
2. For separated intervals, a system of linear equations is formed that is solved by matr ix method or by Darbin method using the auto-corr elation function (method is selected by user );
3. The pr ediction err or is calculated.
Elaborated algor ithms have been r ealized in MATLAB envir onment. The softwar e allowed to r ealize the pr ocess of the speech signal compr ession with the help of pr oposed m e- thod, w as elaborated. As an example, the compr ession of the wav-files (PCM format, F= 8 kHz) w hich contains the entry wor d "Priklad" of size 6.54 kbit, was conducted.
Fig 1 : Wav-file for the Ukrainian wor d « PRIKLAD » Finally the wor king of the pr ogr am gives us the spec-
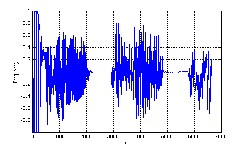
tr ogram of Fig 2 and the image of intensity of the pr evious
compr ession in the step (Fig3).
0.6
0.4
0.2
0
0 1000 2000 3000 4000 5000 6000 7000
Time
Fig 3: Image of intensity of the pr evious compr ession
As shown in fig.3 , at the step 1 of pr evious compr es- sion near 53% of wav-file was tr eated.
Ar eas of the or iginal wav-file, which is not subj ected
to pr ocessing at the stage of the pr evious compr ession (zer o level at the Figur e 3) ar e ar chived at the final stage of compr ession, which consist fr om the splitting into fixed inter- vals (256 samples dur ation 20 ms) and calculation for each of them the linear pr ediction coefficients (using linear pr ediction or der 8).
Size of the obtained ar chive file in format .mat has dimensions of 3.51 kbit, the compr ession ratio is 54%.
To illustrate the efficiency of the developed method
the study was conducted, in which the compar ison of the of ar chive file sizes fr om various softwar e pr oducts was con- ducted. Sour ce files of speech signal wer e stor ed in the wav- format. Compr ession of the sour ce file was fulfilled by WinZip
8.0 archiver, by conver gence to formats mp3, w ma, and by the
developed softwar e. The r esults of the experiments ar e shown
in Table 1.
Listed in Table 1 r esults shows that the developed software has fulfilled the compr ession mor e effectively than WinZip 8.0 archiver and wma codec.
The experiment was implemented w ith the purpose of
displaying the advantages and the drawbacks of using of the pr evious compr ession procedur e.
As the evaluation cr iter ia wer e the size of the or iginal
mat-file and the time taken to pr ocess linguistic mater ial. The exper imental r esults shown in Table 2.
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h Vo lume 3, Issue 1 , January -2012 4
ISSN 2229-5518
Table 1 - Compar ison of the efficiency of signal compr ession methods
Linguistic material | Size of files, compressed by different methods | ||||
Linguistic material | |||||
Linguistic material | File size in format .wav, Kbit | File size in format .zip, Kbit | File size in format .mp3, Kbit | File size in format .wma, Kbit | File size in format .mat, kb |
Numbers 1-10 | 78,20 | 34,10 | 27,40 | 28,10 | 30,54 |
report | 5,72 | 3,78 | 3,12 | 3,31 | 3,19 |
experiment | 12,00 | 7,42 | 5,28 | 5,40 | 5,52 |
priklad | 6,54 | 4,77 | 3,51 | 3,44 | 3,51 |
VNTU | 33,90 | 21,00 | 17,20 | 17,30 | 17,39 |
Table 2 - S tudying o f the p revious co mpr ession proced ure efficiency
The table 2 shows that using of pr evious compr ession pr oc e- dur e allows to incr ease the speed of of speech signal pr ocessing by 25-35% w ith an incr ease in the output file size by about 10%. Thus, it is advisable to put in software the choice of compr ession mode.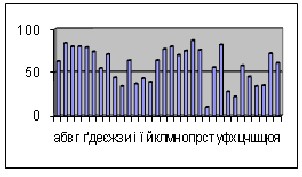
Tables 1 and 2 show that the efficiency of the compr ession pr ocess depends on the speech mater ial, which allows to de- fine the sensitivity of sounds until the pr ocess of compr ession. The r esults ar e illustrated in fig.4
Fig.4: Diagramm of compr ession of the sounds of Ukr ainian alphabet
As w e can see on the chart of fig.4 , the most sensitive sounds ar e observed by means of high louding sounds ( the compr ession coefficient varies fr om 50 to 80%) wher eas the least sensitive ar e the consonants whose compr ession coeffi- cient var ies fr om 10 to 40
The th eor etical and experi men tal r esults o btained in the research allowed developin g a method o f the speech signal compression using o f linear p rediction . An alg o- rithm and so ftwar e for this method realization using MATL AB has been elabo rated .
In the stu dy we have o btained:
1. Size of co mpr essed by the d eveloped method
files cor responds to size of fil es in for mats mp3, wma, o b- tained by c onverting the o riginal wav -file, and exceed their quality;
2. Using of previous c omp ression pr ocedur e allows to increase the speed o f speech signal proc essing by 25 -35% with an increase in the output file size by about 10%.
3. The study o f sounds that corr espond to the Ukrainian alphabet showed that the most sensitive to co m- pression of the p revi ous procedu res were the sounds that correspond to vow els and voiced consonants (50 -80% com- pression ratio), the l east sensitive - consonants (10-40% compr ession ratio).
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h Vo lume 3, Issue 1 , January -2012 5
ISSN 2229-5518
REFERENCES
[1] Rabiner L.R. : Digital Speech Signal
Signal Pr ocessing, Moscou, 1981.
[2] Makhoil J: Linear pr ediction //TIIER T.63,
1975
[3] Korotaev G.A.: Analysis and speech
synthesis signal using linear pr ediction method // Zar ubejnaya electr onika , 1980, n°3, pp:23 – 34.
[4] Bar ochin S.N. : spectr um analysis and
pr oblema of r eduction description speech
signals //spectr um analysis of sounds.
Moscow, 1969 – pp:13 – 30.
[5] Mar kel J.D. , Gr ay A.X. Linear pr edication
of speech signal: Moscow , radio and Sviaz
, 1980 , 248p.
[6] Kyzmin I.V., Kedrus V.A. Basis of the
infor mation theory and coding. Kiev, visha
shcola,1986 -238p.
Raimy Abdour ahmane, Konate Karim, Laboratory of Telecom- munication and Network, Department of Mathematics and Comput- er Sciences, Faculty of Sciences and Techniques, Univers ity Cheikh Anta Diop of Dakar, Dakar, Senegal, ar aimy16@yahoo.fr , kko- nat e911@yahoo.fr
Bykov Nikolai Maximovitch, PhD, Pr ofessor , Department of Computer Control Systems, Vinnitsa National Technical University, Vinnitsa, Ukraine, nkby kov@mail.r u
IJSER © 2012