International Journal of Scientific & Engineering Research Volume 2, Issue 11, November-2011 1
ISSN 2229-5518
Layer Based Intrusion Detection System for
Network Security (LBIDS)
Bonepalli Uppalaiah, Nadipally Vamsi Krishna, Renigunta Rajendher
Abstract—In this paper we present a general framework for an Intrusion Detection System which we call as the Layer Based Intrusion Detection System (LBIDS). We base our framework on the fact that any network needs to ensure the confidentiality, integrity and availability of data and/or services which can be compromised only sequentially one after the other, i.e. availability followed by authentication and authorization and finally leading to loss of confidentiality and integrity. Our framework examines different attributes at different layers to effectively identify any breach of security at every layer. This would have the advantage of reducing the computation and increasing the detection accuracy. This is attributed to the fact that once an anomaly is detected at a layer, it saves the computation required by subsequent layer(s) by simply blocking it at the point of identification. Detection accuracy can be increased as the features that are selected to be evaluated to make any decision at a particular layer are optimized to detect that particular attack category.
Index Terms— Network Security; Intrusion Detection; Layered Approach.
—————————— ——————————
1 INTRODUCTION
OW-a-days the current state of network is vulnerable; they are prone to increasing number of attacks. These attacks are seldom previously seen and being different
they are very hard to detect before subsequent is damage is
done [11]. Thus securing a network from unwanted malicious traffic is of prime concern. A computer network is more than a group of connected nodes. On one hand it needs to provide continuous services, such as e-mail, to a number of users, while on the other it stores huge amount of data which is of vital significance.
Intrusion Detection techniques employed to detect attacks are now not new. However Intrusion Detection until recently has been employed for perimeter security and detecting attacks which were targeted towards denial of service or a resource. Recently, there has been increasing concern over safeguarding the vast amount of data stored in a network from malicious modifications and disclosure to unauthorized individuals. The nature of data stored in a network may range from personal information including identity related details, medical history, bank account and credit card details etc. to a company’s offi- cial details and management plans. Any misuse of this critical data stored in the repositories might lead to drastic conse- quences. Thus, a network must ensure security of both, the services it provides and the large amount of data that it stores. Hence it is the confidentiality, integrity and availability (CIA) of service and data that needs to be ensured to ensure com- plete network security.
Intrusion Detection Systems (IDS) are based on two concepts; matching of the previously seen and hence known anomalous patterns from an internal database of signatures or building profiles based on normal data and detecting deviations from the expected behavior. The first approach is called as Misuse Detection and leads us towards Signature based IDS while the second is called as Anomaly Detection and leads us to Beha- vior based IDS may have the ability to detect new unseen at-
tacks but have the problem of low detection accuracy [9], [10]. Based on the mode of deployment the Intrusion Detection Sys- tems are classified as Network based, Host based and Applica- tion based. Network based systems make a decision by ana- lyzing the network logs and packet headers from the incoming and outgoing packet since they are deployed at the periphery of the network. Though they are easy to manage and give a centralized control, they have to work with limited informa- tion and are further constrained in case of encryption and network address translation. Host based systems monitor’s individual systems and uses system logs extensively to make any decision. However, they are platform dependent and needs to be monitored at each node separately where they are deployed.
[6]Provides further comparison of the Network based IDS and Host based IDS. In order to bridge the gap between the detec- tion capabilities of a Network based IDS (NIDS) and a Host based IDS (HIDS), use of both NIDS and HIDS is recommend- ed in practical situations. Further, Application based IDS uses application logs as their data sources and can provide maxi- mum security. Since all the modes of deployment of IDS differ in their input they have different detection capabilities. Final- ly, the Distributed Intrusion Detection Systems (DIDS) are also possible which can be of two types. They are either a coopera- tive approach between the HIDS, NIDS and a central server where the central server makes any decision on the informa- tion provided by the cooperating IDS or are a group of standa- lone separate IDS alerting neighbors when one IDS discovers any attack, hence sharing the knowledge of attack within the entire network. Both the approaches in the DIDS suffer from some problems. The first type of DIDS have the problem that the central server is a single point that makes any decision for every cooperating system and hence it has lot of data to be processed and is very difficult to be online. While, in the second type of DIDS discussed above, each system (NIDS or HIDS) is a separate identity and simply tells its neighbor that
IJSER © 2011
http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 11, November-2011 2
ISSN 2229-5518
it discovered an attack. It is well known that to secure a net- work, we should use a combination of NIDS, HIDS or a DIDS, but the question that we are addressing here is; can we have a single system that is strong enough to analyze all the relevant data as well as minimize the amount of computation required and still is highly accurate in terms of detection accuracy.
2 MOTIVATION FOR OUR FRAMEWORK
Current systems consider availability, privacy (or confidential- ity) and integrity in isolation of each other. However, we be- lieve that all the three are related and hence cannot be treated as separate problems. Based on this we introduce the concept of LBIDS, which is not a group of IDS cooperating together as in case of a Distributed IDS, but is a self contained single sys- tem which tries to identify the anomalies by a series of tests in succession. This would have the advantage of reducing the computation and increasing the detection accuracy. This is attributed to the fact that once an anomaly is detected at a layer, it saves the computation required by subsequent layer(s) by simply blocking it at the point of identification. Detection accuracy can be increased as the features that are selected to be evaluated to make any decision at a particular layer are optimized to detect that particular category. Hence on one hand, this gives us the flexibility to include a large number of features and, on the other; it helps to divide these features into few groups or layers so that different features can be used at different layers. Further we have a single feature that is signif- icant for detection in more than one layer. Since we address the three basic security features together, our framework can address any type of attack category including the unknown or undiscovered attacks. Such a system is essentially based on anomaly detection and is an Application based IDS. This is because it is only at the application level, when any semantic information can be obtained from any packet. However, since our system is progressive in nature, it can also be used as a Network or Host based IDS.
3 RELATED WORK
Large amount of work has been done in the area of intrusion detection and a number of techniques including data mining approaches, clustering, naïve Bayesian networks, hidden mar- kov models, decision trees, artificial neural networks, support vector machines, genetic algorithm, agent based approaches and many others have been described in order to detect intru- sion. We describe these techniques here particularly with re- gards to the data they analyze before they label any event as intrusion.
Data mining based approaches for Intrusion Detection are based on building classifiers based on discovering relevant patterns of program and user behavior. Association rules and frequent episodes are used to learn the record patterns that describe user behavior. Data mining approaches can deal with symbolic data and the features can be defined in the from packet and connection details. Thus, mining of features can be
defined in the from packet and connection details. Thus, min- ing of features is limited to entry level of the packet and also requires the number of attributes to be large and the records are sparsely populated, otherwise they tend to produce very large number of rules which increases the complexity. Cluster- ing of data has been applied extensively for intrusion detec- tion using various clustering methods including k-means, fuzzy c-means and many others. However, one of the draw- backs of clustering techniques is that it is based on calculating the distance between the observations and hence the attributes of the observations must be numeric. Symbolic attributes can- not be used for clustering which results in inaccuracy.
In Bayesian network is used to remove the threshold and combine the results of individual models to reach a final re- sult. However, they tend to be attack specific and build a deci- sion network based on specific features of each attack. Thus, the size of the Bayesian network increases rapidly as the num- ber of features considered increases and the type of attacks modeled increases. Hidden Markov models have also been used in intrusion detection. The use of hidden Markov models for modeling the normal sequence of system calls of a privi- leged process, which can then be used to detect anomalous traces of sequence calls. However, modeling the system calls alone may not always provide accurate classification as in such cases various connection level features are ignored. Fur- ther, hidden Markov models are generative models and fail to model long range dependency between the observations. De- cision trees [9] have also been used for intrusion detection. The problem with the decision trees is to select the best attribute for each decision node during the construction of the tree. One such criterion is to use the gain ratio in C4.5.
The decision trees suffer from similar problems as the Baye- sian networks. The decision trees tend to grow in size and complexity as the number of attributes increases. Decision trees can be easily used for building the misuse detection sys- tems, but, it is very difficult to construct anomaly detection system using decision trees. [10], discusses the use of Artificial Neural Networks intrusion detection. The neural networks can work effectively with noisy data but they require large amount of data during training and it is often hard to select the best possible neural network architecture. Support vector machines (SVM) which maps real valued input feature vector to higher dimensional feature space through non-linear map- ping have been used for detecting intrusions. The SVM’s pro- vide real time detection capability and can deal with large di- mensionality of data. However, they are used effectively for binary class classification only. Along with these, other tech- niques for detecting intrusion includes the use of generic algo- rithms and agent based approach including autonomous agents for intrusion detection [2] and probabilistic agent based approach for intrusion detection [3] which are generally aimed at a distributed intrusion detection system.
The 1999 KDD intrusion detection data set, which is a version of the 1998 DARPA intrusion detection data set prepared and
IJSER © 2011
http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 11, November-2011 3
ISSN 2229-5518
managed by the MIT Lincoln lab, and the system call data set collected at the University of New Mexico have been widely used to report various experimental results on intrusion detec- tion. The DARPA data set presents data as a collection of records where each record presents a summary of connection or sequence of packets between a specific source and target IP address at certain well defined times [4], while the system call data is the traces of system calls generated by certain selected routines such as send mail where each trace is just a sequence of system call and its corresponding process id [5].
All the above mentioned techniques for detecting intrusions are primarily targeted at ensuring availability. There are me- thods [7], [8], which are meant to ensure confidentiality and integrity of the data stored in databases. They use the database logs either to build the normal user profiles [8], or to extract signatures for detecting known attacks.
However, to ensure that a network is secure, we need to pro- vide confidentiality and integrity along with availability. As we discuss in the next section, our framework aims at provid- ing all the three (confidentiality, integrity and availability) together in a single system.
4 PROPOSED FRAMEWORK
Either the current systems suffer from a number of drawbacks in terms of detection capability and accuracy or they are high- ly specific to addressing a single issue in security. Hence, with the current setup entire network security is far from reachable. We propose a framework for intrusion detection detection which we call as the LBIDS.
To ensure complete network security i.e. to provide confiden- tiality, integrity and availability (CIA), we need a system which is both specific in detecting attacks targeted individual- ly at the CIA by selecting only a small set of features which are significant to detection for a particular category, as well as is capable to correlate the results to ensure complete network security. The system not only needs to perform this task with high accuracy but also needs to do it at a stage as early as possible as it reduces the effect of the attack and also reduces the computation required by the system.
Our system is based on the fact that attacks targeted at confi- dentiality, integrity and availability can be detected indivi- dually by selecting different attributes for each of the three. Further, the complexity of the system or the number of fea- tures that are significant for detecting attacks for any higher layer may be more than its previous layer as the higher layer can also involve features which are present in the previous layer. For example, in detecting a DoS attack, i.e. in ensuring availability, we might not be interested in the finding out which file was accessed, while this becomes significant when we want to ensure data integrity and privacy. Further, when ensuring data privacy and integrity, we are not only interested in finding which file was accessed but we also need to take
care of the user permissions and access pattern of any user or group. Hence, since the very nature of the CIA is different we need to evaluate different set of features to effectively discover attacks at different layers. Further, it seems very logical that a file cannot be modified unless it is available. We also believe that availability, confidentiality and integrity can be compro- mised only sequentially, though it is not necessary for one to be a prerequisite for the other, i.e. confidentiality can be at- tacked even though there is no attack on availability. Thus, before a file is read or written, we make sure that it is free from a DoS attack or attack on confidentiality.
In order to label an event as normal or as an attack the current intrusion detection systems either reduce the number of fea- tures considered to make any decision, thus compromising the detection capability of the system, or make use of many such features making the system very complex and non- incremental, i.e. making the system respond to whatever in- formation is available at the current instant, and thus avoiding any decision making only at the last stage, we propose a layered intrusion detection system. Hence, we split our system into a number of sequential overlapping layers, which we dis- cuss next, where each layer evaluates certain specific features which are significant for detecting attacks targeted at that par- ticular layer. Since, we have divided our system into a number of layers. Each layer can result in detecting attacks with high accuracy as it considers all the features necessary for detection at that layer and at the same time it requires minimum effort as the overall detection is divided between numbers of layers. Further, each next layer in the system uses a set of features which is a combination of some selected features from the previous layer, though it leads to redundancy but is required to link the adjacent layers, and other unique features which are significant to that particular layer.
4.1 Description of Layers
We propose a three layer system to ensure complete security viz. availability, integrity and confidentiality, each layer cor- responding to one aspect of security. The layers are sequential and overlapping i.e. layer one followed by layer two followed by layer three, where each layer has some unique features and some features from its previous layers. This ensures that each layer is stand alone and is able to effectively block the type of intrusion which it is meant to block. Sharing of some features from previous layers is necessary to ensure that the layers are linked together. This is important because as we move to any higher layer, various semantic features needs to be related to the non-semantic features such as connection features to en- sure better detection capabilities.
In our proposed framework, the first layer or the connection establishment layer corresponds to the packet level features such as source and destination IP address, number of connec- tions to the host, source and destination port number, user ID etc. and is optimized to detect attacks exploiting the availabili- ty aspect such as DoS attacks, probes, etc. the second layer which is the privacy layer ensures data confidentiality and
IJSER © 2011
http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 11, November-2011 4
ISSN 2229-5518
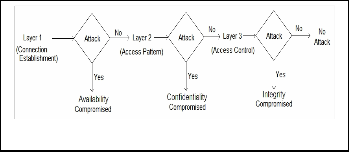
refers to features such as files accessed, data retrieved etc. the third layer or access control layer ensures integrity of data and is more concerned with the file modifications, user privileges etc. and is also the last layer in our proposed architecture of network security. It is worth mentioning that the access pat- tern or the privacy layer itself requires some packet level fea- tures used in the first layer and so does the access control layer. We present this layered architecture in Figure 1.
Fig. 1. Layered Approach.
4.2 Comparison of Our Framework
We propose our framework with other current network secu- rity frameworks. The task of network security has been mainly con fined to the availability aspect, but there are systems that have been implemented to ensure confidentiality, integrity and availability. However, they treat the three security aspects individually and thus results in separate systems for each. In contrast, we consider the three aspects as highly related and propose a single unified framework. Also, the current frame- works, such as the common intrusion detection framework architecture, club a number of standalone intrusion detection systems which requires all the standalone systems to under- stand common language and semantics to interoperate. Our framework on the other hand is based on three layers, each of which is modeled to ensure availability, confidentiality and integrity sequentially. Our framework is based on ensuring what needs to be preserved rather than protecting from differ- ent and unknown kind of attacks.
Our framework has the advantage that it is not specific to any
particular type or group of attack as we address the three basic features of security viz. confidentiality, integrity and availabil- ity and bind them together in a single system rather than creating different system for ensuring each security aspect. As already discussed our proposed framework is less computa- tional expensive and is incremental to the amount of data that is analyzed, thus, making the approach online, feasible and highly flexible. Further, since the system makes a series of de- cisions by grouping various layer specific features together our system can be customized for any specific application and can also be used as a standalone Network or Host based sys- tem. Additionally, we can make use of any of the available technique, as discussed in section 3, for building an effective intrusion detection system. Our framework essentially pro- vides a method that can help to reduce the complexity of the system by simply dividing the task into a sequence of tasks based on the three basic security concepts.
5 CONCLUSIONS
In this paper we proposed a simple yet practical layered ap- proach to intrusion be computation. We discussed that such a system would less computational intensive and more accurate. We are currently evaluating different layers individually and as part of our future work. We believe in prevention over cure. As cure may or may not be achieved.
ACKNOWLEDGMENT
We thank International Journal of Scientific and Engineering Research (IJSER). Also we thanks to Holy Mary Institute of Technology and Science (HITS COE), India, A.P, Hyderabad for finding and supporting this research.
REFERENCE
[1] http://www.cerias.purdue.edu/research/aafid/.autonomo us agents for intrusion detection. Online article (Last assessed: July 12
2006)
[2] http://www.cse.sc.edu/research/isl/agentIDS.shtml, probabilistic agent based approach for intrusion detection. Online article (Last assessed: July 06 2006)
[3] http://kdd.ics.uci.edu//databases/kddcup99/kddcup99,html. KDD Cup 1999 Data (Last assessed: July 02 2006)
[4] http://www.cs.unm.edu/~immsec/systemcalls.htm. Computer
Immune Systems: (Last assessed: July 02 2006)
[5] http://www.windowssecurity.com/articles/HidsvsNidsPart1.html.
Online article (Last assessed: July 02 2006)
[6] Y.Zhong, Z.Zhu, and X.L. Qin. A clustering method based on data queries and its application database intrusion. In proceedings of the fourth International Conference on Machine Learning and Cybemetics, IEEE Press, vol. (4), 2005, pages 2096-2101.
[7] Y.Hu and B.Panda. A datamining approach for database intrusion detection. In Proceedings of the 2004 ACM symposium on Applied Computing, ACM press, pages 711-716.
[8] D. Denning.vAn intrusion-detection model. IEEE Transactions on Software Engineering, vol. (SE-13), no. (2), 1987, pages 222-232. [12] Y. Du, H. Wang, and Y. Pang. A hiddenmarkov models-based anomaly intrusion detection method. In fifth World Congress on Intelligent Control and Automation, 2004, (WCICA’04), IEEE Press, vol. (5), 2004, pages 4348-4351.
[9] K. Ghosh. Learning program behavior profiles fD.S. Coming and O.G. Staadt, "Veloor intrusion detection. In Proceedings of the 1st USENIX Workshop on Intrusion Detection and Network Monitoring,
1999 pages 51-62.
[10] K. K. Gupta, B. Nath, K. Rao, and A. Kazi. Attacking confidentiality: An agent based approach. In Proceedings of IEEE International Conference on Intelligence and Security Informatics, Lecture Notes in Computer Science, Springer Verlag, vol. (3975), 2006, pages 285-
296.[2].
AUTHOR PROFILE

B. Uppalaiah received Master of Technology (Software En-
IJSER © 2011
http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 11, November-2011 5
ISSN 2229-5518
gineering) from Aurora’s Technological and Research Institute (ATRI) Hyderabad in 2010. His research interests include Network Security , Information Security and Data Mining. And he is currently working as an Assistant Professor, de- partment of Computer Science in Holy Mary Institute of Tech- nology and Science (HITS COE), India, PH-8143859839. Email : bnp.uppalaiah@gmail.com
N. Vamsi Krishna


R. Rajendher received Master of Technology in Mechanical Systems Dynamics and Control from IIT Kharagpur. And he is currently working as an Assistant Professor in Holy Mary In- stitute of Technology and Science (HITS COE), India, Email : rajendher.raj@gmail.com
IJSER © 2011
http://www.ijser.org