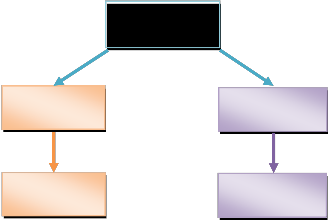
There are two types of compression techniques exist. Their classification can be described below in Figure 1.0
International Journal of Scientific & Engineering Research, Volume 4, Issueŝ, Ju¢ 2013
ISSN 2229-5518
1575
—————————— ——————————
With the steady increase in database volume, the transaction overhead is also increased. Since, it becomes almost mandato- ry to manage the data in an organized and an efficient way. The Data Warehouse technique enables us to store static data in an organized way, as data once committed cannot be edited or deleted, which is always fruitful for decision support and relieves us from daily transaction overhead [6]. It is very con- venient to store compressed data in data warehouse to save disk storage [1]. Other reasons for storing data in compressed way are:
Reduced query execution time as static data is stored
in data warehouse.
Reduced CPU overhead as it needs to search data in less space.
Reduced data redundancy.
There are four levels at which compression can be performed on Data warehouse [3] - File level compression, Page level compression, Record level compression and Attribute level
attributes [16] however, variable length coding always per- form well over fixed length coding [3]. Our compression tech- nique uses variable length coding which will be applied on Relational Database that includes both lossless and lossy com- pression. Lossless Compression for three data types (string, integer and float) and lossy compression on image attribute is done in a relation.
There are two types of compression techniques exist. Their classification can be described below in Figure 1.0
Compression
Techniques
compression. All defined compression levels have their own merits and demerits. In terms of compression ratio, File level and Page level compression are better however, for query processing, they do not perform well, as entire file or page has to be compressed and decompressed which gives more over- head on CPU unnecessarily, hence performance degrades. On
Lossless
Compression
Lossy
Compression
the other hand, Record level compression and Attribute level
compression perform well but, does not give good compres-
sion ratio in comparison to the first two types [3].
We propose the technique for compression at attribute level.
Existing techniques emphasized on fixed length coding on all
————————————————
Mohd. Fraz is currently pursuing M.Tech. in Invertis University, India, Email: mfaraz83@gmail.com
Ajay Indian is working as a Head- Deptt. of Computer Applications, Inver- tis University, India. Email: ajay.i@invertis.org
Hina Saxena is currently pursuing M.Tech. in Invertis University, India, Email: poojabhatnagar18@gmail.om
Saurabh Verma is currently pursuing M.Tech. in Invertis University, India, Email: shahzada29saurabh@gmail.com
Huffman Coding JPEG Coding
Lossless compression is one in which there is no loss of infor- mation when data is decompressed to its original form how- ever in lossy compression, there is a loss of some information when decompressed [17].
2.1 Huffman Coding [1]
Huffman Encoding Algorithm is a variable length coding
which uses the probability distribution of the alphabets of the
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue ŝ, Ju¢2013
ISSN 2229-5518
1576
source to develop the codeword for symbols. The frequency distribution of all the characters of the source is calculated in order to calculate the probability distribution. According to the probabilities, the codeword are assigned. Shorter code- word for higher probabilities and longer codeword for smaller probabilities are assigned. For this task, a binary tree is created using the symbols as leaves according to their probabilities and paths of those are taken as the codeword. Two families of Huffman Encoding have been proposed: Static Huffman Algo-
3.1.1 Compressing numeric attributes [8]
A page may have both numeric and non-numeric attributes. To compress numeric attributes a technique was developed in which a column containing integers were scanned to find out the lowest and highest integer value. Thus, all the values lying
rithms and
Adaptive Huffman Algorithms. Static Huffman
in between these two values are assigned the bits starting from
Algorithms calculate the frequencies first and then generate a common tree for both the compression and decompression processes [1]. Details of this tree should be saved or trans- ferred with the compressed file. The Adaptive Huffman algo- rithms develop the tree while calculating the frequencies and there will be two trees in both the processes. In this approach, a tree is generated with the flag symbol in the beginning and is updated as the next symbol is read.
2.2 JPEG Coding [10, 13]
A lossy approach, JPEG coding (Figure 1.1) is a well known
and popular standard for compression of still images. The source image is divided into 8×8 blocks and each block is
transformed using DCT (Discrete Cosine Transform). The data compression is achieved via quantization followed by variable length coding (VLC). The quantization step size for each of the
64 DC coefficients is specified in a quantization table, which remains the same for all blocks in the image. In JPEG, the de- gree of compression is determined by a quantization scale fac- tor.
0. For example: - if a column on a page has 20 as minimum
value and 24 as maximum then a range is defined. This range
will be consisting of only 5 values and we can specify a given
value in this range by using only 3 bits i.e. 20 as 000, 21 as 001,
22 as 010, 23 as 011 and 24 as 100. This minima and maxima
provide a frame of reference in which all the values lie.
3.1.2 Compressing non-numeric attributes [8]
The same technique could be used for compression of non-
numeric attributes which have low cardinality or one can say which have high redundancy in values of an attributes like
gender, state or country. A high compression ratio can be achieved in such type of attributes. For example: - Gender attribute contains only two values for all the records. There- fore, only two bits are used to define its values 0 for male and
1 for female. Similarly, state and country are other attributes which have a very limited range of values.
The main objective of this technique is to allow the reduction of the space occupied by dimension tables with high number of rows, reducing the total space occupied by the data ware-
En- cod-
010011
De- cod-
house and leading to a consequent gains on performance[12]. It is aimed to compress two different types of database attributes:-
Ill Text attributes with low cardinality (known as categories).
Ill Attributes of free text: comments or notes (known as descrip-
tions).
Origina l Image
Reduce correlation of pixels
Quanti
-zation
Entropy Encodin g
65536.
Increasing the quantization scale factor leads to coarser quan- tization, this gives higher compression and lower image quali- ty. The DC coefficients of all blocks are coded separately, us- ing a predictive scheme. JPEG is very efficient coding method but the performance of block-based DCT scheme degrades at very high compression ratio.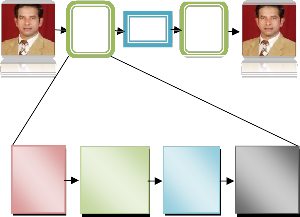
A Description is a text attribute that is mainly used for visua- lization. For example: description attribute is the comment attribute, which is frequently found in dimension tables. This type of attributes has the particularity of having a low access frequency and it is only necessary to decode it when the final result is being constructed.
3.2.1 Categories Coding [12]
Categories coding is done through the following steps:
1. The values of the attribute are analyzed and its frequency is
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue ŝ, Ju¢-2013
ISSN 2229-5518
1577
calculated.
2. The table of codes is build based on the frequency: the most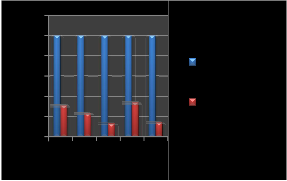
frequent values are encoded with a one byte code; the least
frequent values are coded using a two bytes code. In principle, two bytes are enough, but a third byte could be used if
needed.
3. The codes table and necessary metadata is written to the
database.
4. The attribute is updated, replacing the original value by
corresponding codes (the compressed values).
3.2.2 Descriptions Coding [12]
It is very similar to the categories coding with the major dif-
ference that in this case the value in the attribute is not re-
garded as a single value, but as a set of values (an ASCII
string). Any text compression algorithm can be used to per- form this type of compression.
In this paper, Huffman coding has been applied on three data types (string, integer and float), which is lossless by nature and JPEG coding is applied on image attribute, which is a los- sy algorithm. Huffman coding is a variable length coding which gives better compression ratio in comparison to the previous techniques.
4.1 How to compress text, integer and string attributes
A variable length coding has been used i.e. Huffman coding. It
120
100
80
60
40
20
0
1 2 3 4 5
Original
Attribute Size
Compressed
Attribute Size
is a lossless algorithm which goes through all the alpha-
bets/numbers of an attribute and finds its frequency in it. Af- terwards it generates the tree and assigns binary codeword for that attribute. More the frequency of an element, less the code size it gets. In the same way all the attributes are encoded.
4.2 How to compress image attribute
JPEG technique has been used to compress the image attribute. Once the correlation between pixels is reduced, we
can take advantage of the statistical characteristics and the variable length coding theory to reduce the storage quantity.
The database table is created and Huffman and JPEG coding techniques have been applied to evaluate the result. Several tables can be created and can be compressed using the pro- posed technique. We have created a table named “DbEmp”.
At last, it is concluded that an effective compression technique has been proposed that performs appropriate compression on Data warehouse. Compression at attribute-level is done for four types of data types. This compression technique can be applied to multi-databases. One can see the status of the table being compressed. The obtained results show that an overall Compression ratio of 22.84% is achieved, which is the best ratio ever achieved, and Gain in performance (saving in space) has increased to 77.16%. In the proposed work, we have con- sidered only four data types but there are so many other data types like Boolean, short int, long int etc which can be com- pressed. Moreover, the compression of primary key and for-
This table contains string, integers, float
and image type
eign key is also a main area for research as it contains all the
attributes. Other fields can also be included like email id, ad-
dress, mobile number etc. which can be compressed by consi-
dering them as string type.
After applying compression techniques on the table, the below
unique values.
result shows the Original Attribute Size and Compressed Attribute Size with the help of graph in Figure 1.2. Compres- sion Ratio and Gain in performance are shown with the help of Table 1.0.
[1]
[2]
[3]
D. Huffman “A method for the construction of minimum-
redundancy codes” Proc. IRE, 40(9):1098-1101, September 1952.W. J.Ziv and A. Lempel “A universal algorithm for sequential data com- pression” in IEEE transactions in information theory, vol. 3, No. 3, pp.
337-343, 1977.
Debra A. Lelewer and Daniel S. Hirschberg “Data Compression”,
1987.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue ŝ, Ju¢-2013
ISSN 2229-5518
1578
[4] G.Graefe and L.Shapiro “Data compression and database perfor- mance” In ACM/IEEE-CS Symp. On Applied computing pages 22 -27, April 1991.
[5] Mark A. Roth and Scott J. Van Horn “Database compression” SIG- MOD RECORD, Vol. 22, No. 3, September 1993.
[6] G. Ray, J. R. Haritsa, and S. Seshadri. “Database compression: A per- formance enhancement tool” International Conference on Management of Data, pages 0, 1995.
[7] W. Kim ”Modern Database Systems”, ACM Press, New York, 1995.
[8] Jonathan Goldstein, Raghu Ramakrishnan and Uri Shaft “Compress- ing relations and indexes“ in IEEE computer society, Washington, USA, 1998.
[9] Till Westmann, Donald Kossmann “Implementation and perfor- mance of compressed database” in Reihe Informatik, March 1998.
[10] Gregory K. Wallace “The JPEG still picture compression standard” in
IEEE, December 1999.
[11] S. Chaudhuri and U. Dyal, “An overview of Data warehousing and
OLAP Technology”, ACM SIGMOD record, vol 21, No.1.
[12] Jorge Vieira, Jorge Bernardino and Henrique Madeira “Efficient compression of text attributes of data warehouse dimensions”, 2005.
[13] Wei-Yi Wei “An Introduction to image compression”, 2008.
[14] Amy Turske McNee “The Evolutionary Data Warehouse-An Object- Oriented Approach”, 2008.
[15] Akanksha Baid and Swetha Krishnan”Binary Encoded Attribute-
Pairing Technique for Database Compression” 2008.
[16] Meenakshi Sharma and Sonia Dora ”Efficient Approach for Com- pression in Data Warehouse” IJCA (0975-8887) Volume 53 – No.9, September 2012.
[17] Mark Nelson and Jean-loup Gailly ”The Data Compression Book”
2nd Edition.
IJSER © 2013 http://www.ijser.org