International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 186
ISSN 2229-5518
Comparative Study On Hyperspectral Remote
Sensing Images Classification Approaches
1R.Priya 2Dr.M.Senthil Murugan
Index terms - Remote Sensing (RS), Maximum Likelihood Classifier (MLC), Digital Orthophoto Quadrangle (DOQ), Iterative Self-Organizing Data
Analysis (ISODATA), Digital Number (DN).
—————————— ——————————
from the external factors such as an atmospheric condition
to the internal factors like sensor noise, sensor transfer
Hyperspectral imaging is concerned with the
measurement, analysis, and interpretation of spectra acquired from a given scene (or specific object) at a short, medium or long distance by an airborne or satellite sensor [1]. The information contained in hyperspectral images allows the characterization, identification, and classification of the land-covers with improved accuracy and robustness. However, several critical problems should be considered in the classification of hyperspectral data, among which: (i) the high number of spectral channels, (ii) the spatial variability of the spectral signature, (iii) the high cost of true sample labeling, and (iv) the quality of data. In particular, the high number of spectral channels and low number of labeled training samples create the problem of the curse of dimensionality [2] and, as a consequence, result in the risk of over fitting the training data. There are many factors affecting the hyperspectral data quality, ranging
————————————————
• 1Assistant Professor (SG), Department of Computer Applications,
characteristics, and material spectrum. For a specific object or material, the noise-dominated bands will certainly deteriorate the discrimination capability, and hence degrade the classification performance. On the other hand, the spectral difference among materials also varies across bands [3]. Classification is a challenging but important task for hyperspectral remote sensing applications, including land use analysis, pollution monitoring, wide-area reconnaissance, and field surveillance [4]. This paper provides the major steps in remote sensing classification and approaches with comparison.
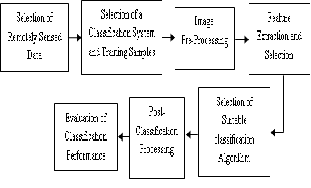
Major steps in remote sensing classification are selection of remotely sensed data, selection of a classification system and training samples, image preprocessing, feature extraction and selection, selection of suitable classification method, post-classification processing and evaluation of classification performance. These steps
are depicted in figure 1.
Bharathiyar College of Engineering and Technology, Karaikal,
U.T. of Puducherry, Email: priyaraji_2002@yahoo.co.in
• 2Professor and Head, Department of Computer Applications,
Bharathiyar College of Engineering and Technology,
Karaikal, U.T. of Puducherry, Email: smsenthil@hotmail.com
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 187
ISSN 2229-5518
Figure 1: Steps in Remote Sensing Classification
Remotely sensed data have different spatial, radiometric, spectral, and temporal resolutions. Understanding the strengths and weaknesses of different types of sensor data is essential for selecting suitable remotely sensed data for image classification. Some previous literature has reviewed the characteristics of major types of remote sensing data [5]. The selection of suitable remotely sensed data requires considering factors such as the needs of the end user, the scale and characteristics of the study area, available image data and their characteristics, cost and time constraints, and the analyst’s experience in using the selected images. Atmospheric condition is another important factor that influences the selection of remote sensing data. Monetary cost is often an important factor affecting the selection of remotely sensed data.
A suitable classification system is a prerequisite for successful classification. Generally, a classification system is designed based on the user’s needs, the spatial resolution of the remotely sensed data, compatibility with previous work, available image-processing and classification algorithms, and time constraints. Such a system should be informative, exhaustive, and separable [6]. In many cases, a hierarchical classification system is adopted to take
different conditions into an account. A sufficient number of
training samples and their representativeness are critical for image classifications [7]. Therefore, selection of training samples must consider the spatial resolution of the remote sensing data being used, the availability of ground reference data, and the complexity of the landscapes under investigation.
Image preprocessing may include the examination of image quality, geometric rectification, and radiometric and atmospheric calibration. If different ancillary data are used, the data conversions among different sources or formats and quality evaluation of these data are necessary before they can be incorporated into a classification procedure.
The examination of original images to see on any remote sensing system–induced radiometric errors is necessary before the data are used for further processing. Accurate geometric rectification or image registration of remotely sensed data is a prerequisite for combining different source data in a classification process.
If a single-date image is used for classification, atmospheric correction may not be required [8]. However, when multitemporal or multisensor data are used, atmospheric calibration is mandatory [9]. Topographic correction is important if the study area is located in rugged or mountainous regions [10].
Selecting suitable variables is a critical step for successfully performing an image classification. Many potential variables may be used in image classification; it includes spectral signatures, vegetation indices, transformed images, textural or contextual information, multitemporal images, multisensor images, and ancillary data.
Because of the different capabilities of these variables in land-cover separability, the use of too many variables in a classification procedure may decrease
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 188
ISSN 2229-5518
classification accuracy [11]. It is important to select only those variables that are most useful in separating land- cover or vegetation classes, especially when hyperspectral or multisource data are employed.
In recent years, many advanced classification approaches, such as artificial neural networks, decision trees, fuzzy sets, and expert systems, have been widely applied in image classification. [12] discussed the status and research priorities of land-cover mapping for large areas [13] assessed land-cover classification approaches with medium spatial resolution remotely sensed data. Published works by [14] specifically focused on image- processing approaches and classification algorithms. In general, image classification approaches can be grouped into different categories, such as supervised versus unsupervised, parametric versus nonparametric, hard versus soft (fuzzy) classification, per-pixel, sub pixel, and per field [15]. For the sake of convenience, [15] grouped classification approaches as perpixel, sub pixel, per-field, contextual, and knowledge-based approaches, and a combination approach of multiple classifiers.
In practice, many factors, such as the spatial resolution of the remotely sensed data, different data sources, classification systems, and the availability of classification software, must be taken into account when selecting a classification method for use.
Post classification processing is an important step in improving the quality of classifications [16]. Its roles include, the recoding of land use/cover classes, removal of “salt-and-pepper” effects, and modification of the classified image using ancillary data or expert knowledge.
Traditional per-pixel classifiers based on spectral signatures
often lead to salt-and-pepper effects in classification maps due to the complexity of the landscape.
Thus, a majority filter is often applied to reduce noise. Also, ancillary data are often used to modify the classification image based on established expert rules. Data describing terrain characteristics can be used to modify classification results based on the knowledge of specific vegetation classes and topographic factors. In urban areas, housing or population density is related to urban land-use distribution patterns, and such data can be used to correct some classification confusions between commercial and high-intensity residential areas or between recreational grass and crops [17].
2.7 EVALUATION OF CLASSIFICATION PERFORMANCE
The evaluation of classification results is an important process in the classification procedure. Different approaches may be employed, ranging from a qualitative evaluation based on expert knowledge to a quantitative accuracy assessment based on sampling strategies. A classification accuracy assessment generally includes three basic components: (1) sampling design, (2) response design, and (3) estimation and analysis procedures [18]. The error matrix approach is one of the most widely used in accuracy assessment [19]. In order to properly generate an error matrix, one must consider the following factors: reference data collection, classification scheme, sampling scheme, spatial autocorrelation, and sample size and sample unit [20].
After the generation of an error matrix, other important accuracy assessment elements, such as overall accuracy, omission error, commission error, and kappa coefficient, can be derived [19-24].
Image classification is an important part of
the remote sensing, image analysis and pattern recognition.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 189
ISSN 2229-5518
In some instances, the classification itself may be the object of the analysis. The image classification therefore forms an important tool for examination of the digital images. Classification is a method of grouping data into classes based on some specific similarity of characteristics.
The classification scheme and the method of classification to be used are primarily dependent upon the application of the classification [25]. At present, there are different image classification procedures used for different purposes by various researchers, they are categorized according to training samples, parameters, pixels, output and spatial information.
In supervised classification, the image data are classified into a fixed number of predetermined information classes selected by the analyst. This is accomplished by the following procedure. Training areas closely representing the desired information classes are selected within the image area. Statistical information of the spectral pattern of the information classes is generated from these training classes. This statistical information serves as the reference data during the classification stage. In this stage, each pixel is assigned into one of the information classes based on some predetermined classification strategy. Some of the commonly used classification strategies are minimum distance to means, parallel piped classifier, and maximum likelihood classifier (MLC) [26].
Unsupervised classification is a method of partitioning the image into clusters based on the spectral properties of the pixels. An analyst provides the number of desired clusters and all the image pixels are partitioned into the specified number of clusters. After the image is partitioned into clusters, each and every cluster is then
assigned to a specific information class by using some form
of reference data such as an aerial photograph or Digital
Orthophoto Quadrangle (DOQ).
The two most commonly used algorithms for unsupervised classification are k-means and Iterative Self- Organizing Data Analysis Technique (ISODATA) [25].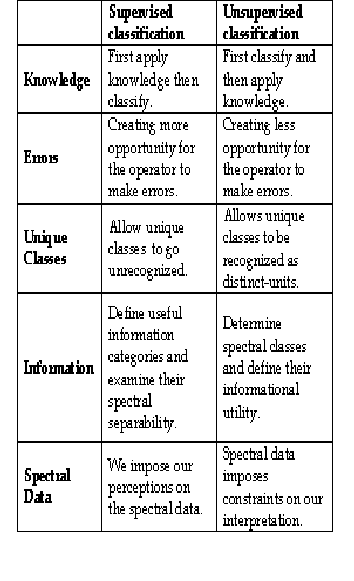
Table 1: Comparison of Supervised and Unsupervised
Classification
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 190
ISSN 2229-5518
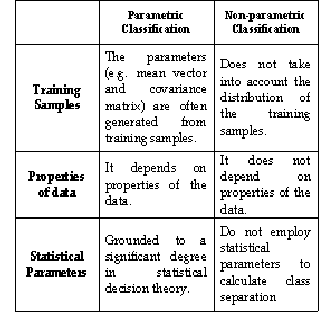
The parameters (e.g. mean vector and covariance matrix) are often generated from training samples. When landscape is complex, parametric classifiers often produce
‘noisy’ results. Another major drawback is that it is
difficult to integrate ancillary data spatial and contextual attributes and non-statistical information into a classification procedure. These classifiers rely on assumptions of data distribution. The performance of a parametric classifier depends mostly on how well the data match with pre-
defined models and on the accuracy of the estimation of the
model parameters. Traditionally most classifiers have been
grounded to a significant degree in statistical decision
theory. They suffer from the Hughes phenomenon (i.e. curse of dimensionality) and consequently it might be difficult to have a significant number of training pixels. They are not adequate to integrate ancillary data (due to difficulties on classifying data at different measurement scales and units) [27].
In non-parametric classifier, no assumption about the data is required. Non-parametric classifiers do not employ statistical parameters to calculate class separation and are especially suitable for incorporation of non-remote- sensing data into a classification procedure. A nonparametric classifier uses a set of nonparametric signatures to assign pixels to a class based on their location, either inside or outside the area in the feature space image. A nonparametric signature is based on an AOI that you define in the feature space image for the image file being classified [27].
Table 2: Comparison of Parametric and Non-Parametric
Classification
Per-pixel classification pattern analyses per-pixel spectrum characteristics, and categorizes each pixel into a certain class by statistical methods (such as discriminant function, clustering) [28], which was brought forth in the early 1970s and is a rather mature technique. Traditional per-pixel classifiers typically develop a signature by combining the spectra of all training-set pixels for a given feature. The resulting signature contains the contributions of all materials present in the training pixels, but ignores the impact of the mixed pixels. Per-pixel classification algorithms can be parametric or non-parametric [29].
Most classification approaches are based on per- pixel information, in which each pixel is classified into one category and the land-cover classes are mutually exclusive. The presence of mixed pixels has been recognized as a major problem, affecting the effective use of remotely sensed data in per-pixel classifications [30].
Subpixel classification approaches have been
developed to provide a more appropriate representation
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 191
ISSN 2229-5518
and accurate area estimation of land covers than per-pixel approaches, especially when coarse spatial resolution data are used. The spectral value of each pixel is assumed to be a linear or non-linear combination of defined pure materials (or end members) [31].
Object-oriented classification pattern deals with image objects, which share the similar attributes, such as Digital Number (DN) value, spectral characteristics, texture, size, shape, compactness, context information with adjacent image objects, etc. [32]. The image objects can be extracted through RS image segmentation technique (to put similar characteristic & spatial conjoint pixels into a same image object). Object-oriented classification pattern uses the image objects as the basic processing units, calculates per- object’s characters, and extracts land-cover information from RS imagery.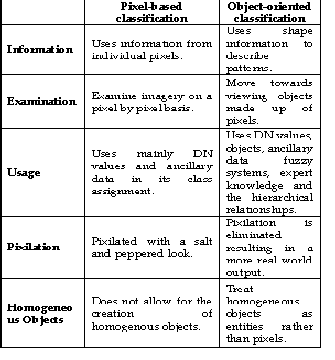
Table 3: Comparison of Pixel-Based and Object-oriented
Classification
The per-field classifier is designed to deal with
the problem of environmental heterogeneity, and has
shown to be effective for improving classification accuracy. The per-field classifier averages out the noise by using land parcels (called ‘fields’) as individual units. GIS plays an important role in per-field classification, integrating raster and vector data in a classification. The vector data are often used to subdivide an image into parcels and classification is based on the parcels, avoiding the spectral variation inherent in the same class [33].
Hard classification is used for making a definitive decision about the land cover class that each pixel is allocated to a single class. The area estimation by hard classification may produce large errors, especially from coarse spatial resolution data due to the mixed pixel problem. Supervised and unsupervised classification algorithms typically use hard classification logic to produce a classification map that consists of hard, discrete categories (e.g., forest, agriculture). The distinguishing characteristic of hard classifiers is that they all make a definitive decision about the landcover class to which any pixel belongs [34].
Soft classification provides more information and potentially a more accurate result, for coarse spatial resolution data classification. Fuzzy set classification logic takes into account the heterogeneous and imprecise nature (mix pixels) of the real world. Proportion of the m classes within a pixel (e.g., 10% bare soil, 10% shrub, 80% forest). Fuzzy classification schemes are not currently standardized. Contrary to hard classifiers, soft classifiers do not make a definitive decision about the land cover class to which each pixel belongs. Rather, they develop statements
of the degree to which each pixel belongs to each of the land cover classes being considered [34].
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 192
ISSN 2229-5518

Table 4 : Comparison of soft and Hard Classification
Spectral classifier is simple and economic as well as it is considers each pixel individually. It can’t describe relation to neighboring pixels. Spectral classes are pixels that are of uniform brightness in each of their several channels. The idea is to link spectral classes to informational classes. However, there is usually variability that causes confusion (forest can have trees of varying age, health, species composition, density, etc.), for this reason pure spectral information is used in image classification. A ‘noisy’ classification result is often produced due to high variation in the spatial distribution of the same class [35].
In addition to object-oriented and per-field classifications, contextual classifiers have also been developed to cope with the problem of intraclass spectral variations.
Contextual classification exploits spatial information among neighboring pixels to improve classification results.
A contextual classifier may use smoothing
techniques, Markov random fields, spatial statistics, fuzzy logic, segmentation, or neural networks. In general, pre- smoothing classifiers incorporate contextual information as additional bands, and a classification is then conducted using normal spectral classifiers, while post-smoothing classification is conducted on classified images previously developed using spectral-based classifiers.
Contextual classification operates on either classified or unclassified scenes. Usually some classification has been done and it reassigns pixels as appropriate based on location (context) [36].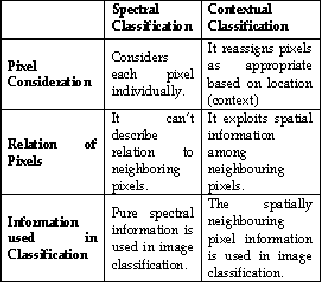
Table 5 : Comparison of Spectral and Contextual
Classification
Besides the spectral data, expert’s knowledge can also play an important role in improving accuracy of the
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 193
ISSN 2229-5518
classification of the satellite images. Human experience and knowledge about the topology, geology etc. of the study area can be embodied in the classification procedures to prepare accurate classified maps; such classification is known as knowledge based classification. The most difficult part of knowledge based classifiers is the creation of the knowledge base [37].
Different classifiers, such as parametric classifiers (e.g. maximum likelihood) and non-parametric classifiers (e.g. Neural network, decision tree), have their own strengths and limitations.
For example, when sufficient training samples are available and the feature of land covers in a dataset is normally distributed, a maximum likelihood classifier (MLC) may yield an accurate classification result.
In contrast, when image data are anomalously distributed, neural network and decision tree classifiers may demonstrate a better classification result. But the integration of two or more classifiers provides improved classification accuracy compared to the use of a single classifier.
A critical step is to develop suitable rules to
combine the classification results from different classifiers. Some previous research has explored different techniques, such as a production rule, a sum rule, stacked regression methods, majority voting, and thresholds, to combine multiple classification results [38].
Despite the long time spent in developing the classification of remote sensing images, a new problems and new user demands have been accumulated to the existing ones: Existing classification techniques do not suit well to new sensors, huge amount of data demand for new
approaches, a wise combination of image analysis
techniques emulating the visual interpretation of humans beings and the need to move from the experimental to the operational applications. Moreover, the combination of different classification approaches has shown to be helpful for improvement of classification accuracy.
[1] A. F. H. Goetz, G. Vane, J. E. Solomon, and B. N. Rock, “Imaging spectrometry for earth remote sensing,” Science 228, pp. 1147–1153, 1985.
[2] G. F. Hughes, “On the mean accuracy of statistical pattern recognizers,” IEEE Transactions on Information Theory, vol. 14, no. 1, pp. 55–63, 1968.
[3] S. Prasad and L. M. Bruce, “Decision fusion with confidence-based weight assignment for hyperspectral target recognition,” IEEE Trans. Geosci. Remote Sens., vol. 46, no. 5, pp. 1448–1456, May 2008.
[4] D. Landgrebe, “Hyperspectral image data analysis,” IEEE Signal
Process.Mag., vol. 19, no. 1, pp. 17–28, Jan. 2002.
[5] Barnsley, M. J. 1999. Digital remote sensing data and their characteristics. In Geographical Information Systems: Principles, Techniques, Applications, and Management, 2nd ed., ed. P. Longley, M. Goodchild, D. J. Maguire and D. W. Rhind, 451. New York: John Wiley & Sons.
[6] Landgrebe, D. A. 2003. Signal Theory Methods in Multispectral Remote
Sensing. 508. Hoboken, NJ: Wiley.
[7] Hubert-Moy, L. et al. 2001. A comparison of parametric classification procedures of remotely sensed data applied on different landscape units. Remote Sens Environ 75:174.
[8] Song, C. et al. 2001. Classification and change detection using Landsat TM
data: When and how to correct atmospheric effect. Remote Sens Environ 75:230. [9] Markham, B. L., and J. L. Barker. 1987. Thematic Mapper bandpass solar exoatmospheric irradiances. International Journal of Remote Sensing 8:517.
[10] Teillet, P. M., B. Guindon, and D. G. Goodenough. 1982. On the slope- aspect correction of multispectral scanner data. Can Journal of Remote Sensing
8:84.
[11] Price, K. P., X. Guo, and J. M. Stiles. 2002. Optimal Landsat TM band combinations and vegetation indices for discrimination of six grassland types in Eastern Kansas. International Journal of Remote Sensing 23:5031.
[12] Cihlar, J. 2000. Land cover mapping of large areas from satellites: Status and research priorities. International Journal of Remote Sensing 21:1093.
[13] Franklin, S. E., and M. A. Wulder. 2002. Remote sensing methods in medium spatial resolution satellite data land cover classification of large areas. Prog Phys Geog 26:173.
[14] Tso, B., and P. M. Mather. 2001. Classification Methods for Remotely
Sensed Data. New York: Taylor & Francis.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 194
ISSN 2229-5518
[15] Lu, D., and Q. Weng. 2007. A survey of image classification methods and techniques for improving classification performance. International Journal of Remote Sensing 28:823.
[16] Harris, P. M., and S. J. Ventura. 1995. The integration of geographic data with remotely sensed imagery to improve classification in an urban area. Photogramm Eng Remote Sens 61:993.
[17] Lu, D., and Q. Weng. 2006. Use of impervious surface in urban land use
classification. Remote Sensing Environment 102:146.
[18] Stehman, S. V., and R. L. Czaplewski. 1998. Design and analysis for thematic map accuracy assessment: Fundamental principles. Remote Sensing Environment 64:331.
[19] Foody, G. M. 2002. Status of land covers classification accuracy assessment. Remote Sensing Environment 80:185.
[20] Congalton, R. G., and L. Plourde. 2002. Quality assurance and accuracy assessment of information derived from remotely sensed data. In Manual of Geospatial Science and Technology, ed. J. Bossler, 349. London: Taylor & Francis.
[21] Congalton, R. G., and R. A. Mead. 1983. A quantitative method to test for consistency and correctness in photo interpretation. Photogramm Eng Remote Sens 49:69.
[22] Hudson, W. D., and C. W. Ramm. 1987. Correct formulation of the Kappa
coefficient of agreement. Photogramm Eng Remote Sens 53:421.
[23] Congalton, R. G. 1991. A review of assessing the accuracy of classification of remotely sensed data. Remote Sens Environ 37:35.
[24] Janssen, L. F. J., and F. J. M. van der Wel. 1994. Accuracy assessment of satellite derived land-cover data: A review. Photogramm Eng Remote Sens
60:419.
[25] Lillesand, T. M., Kiefer, R. W., & Chipman, J. W. (2004). Remote sensing and image interpretation (Fifth ed.). New York: John Wiley & Sons, Inc.
[26] Campbell, J. B. (1996). Introduction to remote sensing (Second ed.). New
York: The Guilford Press.
[27] Jensen, J.R. (1996), Introductory Digital Image Processing: A Remote
Sensing Perspective. 2nd Edition. Upper Saddle River: Prentice Hall.
[28] Zhao Ping, 2003. Knowledge-based Land Use/Cover Classification in the Typical Test Areas of the Lower Reaches of Yangtze River. Nanjing: Nanjing University. (in Chinese)
[29] LAWRENCE, R., BUNN, A., POWELL, S. and ZMABON, M., 2004, Classification of remotely sensed imagery using stochastic gradient boosting as a refinement of classification tree analysis. Remote Sensing of Environment, 90, pp. 331-336.
[30] CRACKNELL, A.P., 1998, Synergy in remote sensing—what’s in a pixel? International Journal of Remote Sensing, 19, pp. 2025-2047.
[31] WOODCOCK, C.E. and GOPAL, S., 2000, Fuzzy set theory and
thematic maps: accuracy assessment and area estimation. International
Journal of Geographic Information Science, 14, pp. 153-172.
[32] Blaschke T, Hay G J, 2001. Object-oriented image analysis and scale-space: theory and methods for modeling and evaluating multi-scale landscape structures. International Archives of Photogrammetry & Remote Sensing,
34(4/W5): 22–29.
[33] LLOYD, C.D., BERBEROGLU, S., CURRAN, P.J. and ATKINSON, P.M.,
2004, A comparison of texture measures for the per-field classification of
Mediterranean land cover. International Journal of Remote Sensing, 25, pp.
3943-3965.
[34] Introduction to Remote Sensing and Image Processing IDRISI Guide to GIS
and Image Processing Volume 1.
[35] CARLOTTO, M.J., 1998, Spectral shape classification of Landsat Thematic
Mapper imagery. Photogrammetric Engineering and Remote Sensing, 64, pp.
905-913.
[36] MAGNUSSEN, S., BOUDEWYN, P. and WULDER, M., 2004, Contextual classification of Landsat TM images to forest inventory cover types. International Journal of Remote Sensing, 25, pp. 2421-2440.
[37] Avelino, J.G. and D.D. Dankel (1993), The Engineering of Knowledge- Based Systems. Upper Saddle River, NJ, USA: Prentice Hall.
[38] Steele, B.M., 2000. “Combining multiple classifiers: an application using spatial and remotely sensed information for land cover type mapping,” Remote Sensing of Environment, vol. 74, pp. 545-556.
IJSER © 2013 http://www.ijser.org