The different similarity functions from web services are identified on certain parameters like port type, opera- tion name, input message, data type similarity, informa- tion loosed maximization function and similarity func- tions from the service.
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 1
ISSN 2229-5518
A Study of Finding Similarities in
Web Service Using Metrics
D.Chandramohan, Shailesh Khapre, S.Ashokkumar
Abstract— Newest mounting and escalated recognition of services and its equivalent building of significant Web service mature to be a considerable rally. Web service expertise for permitting right to entry for promoting services regardless of locality and execution policies exist already. On the other hand, a huge discrepancy on structural, semantically and technological intensity all along with the emergent number of offered web services formulate their discovery a significant challenge. Our proposal progresses to classify an ultimate approach for identifying web service resemblance with the help of metrics. In particular, we analyzed the intrinsic worth of using metrics based Models, WordNet metrics and semantic similarity metrics for this evaluation purpose.
Index Terms—Web Service, metrics, Web Service Architecture, Simple Object Access Protocol (SOAP), (SOAP) based multicast protocol (SMP). (Web Service Manipulation Language) W SDL, Universal Description, Discovery and Integration (UDDI), XML, Web Ontology Language (OW L) ontology
—————————— • ——————————
eb service allows different application from differ- ent sources to communicate with each other with- out time consuming and custom coding. It is a
standardized way of integrating web based applications. It allows organizations and users to communicate data without intimate knowledge of each other and share business logic, data and process through a programmatic interface across a network. It has been employed in a wide range of applications and has become a key tech- nology in developing business operations on the web. In order to leverage on the use of web services, web service discovery and composition need to be fully supported. Several systems have been proposed to meet this need. The search and concepts lets to turn out the useful infor- mation retrieval and matching scenarios. Determination of conceptual overlap simplifies phrasing an adequate search concept. These results are ordered by degree of similarity to the searched and compared to the concepts. Delivering a flexible degree of conceptual overlap to a searched concepts gives the similarity measurements and it would additionally deliver the concepts of whose in- stances are located inside and adjacent to the search re- sult. These concepts are close and identical to the user intended concepts. Identifying the attribute filler or rela- tions for identifying the similarity in WSML (Web Service Manipulation Language) and the service integration sce- narios the similarities between the concepts are based on
————————————————
their specification and their chosen representation lan- guages. This proposal leads to develop metrics for identi- fying the service similarities in web services that can help the clients / users to get serviced by
i) Efficiently finding the web service on web by ranking them according to their category with the help of metrics and proposing their degree of similarity
ii) Implicit and explicit data flow identification in services and computing the service to the best for the requesters. iii) Eliminating fuzzy decision to identify the web service through improved fuzzy similarity algorithms.
We are proposing an approach enabling the implicit representation of similarities across distinct services which will help the requestors for identifying the exact service in which they are looking for. Similarity between words is becoming a generic problem for many applica- tions of computational linguistics and it explores the de- termination of similarity by a number of information sources, which consists of structural information and in- formation content from a huge quires.
Services are provided by logical grouping of opera- tions and its functions, if we consider the relevant service in business process as an activity with specific business goals and new products going to introduces in the near feature, current products to sales and ready for service and fulfilled order and business process consists of ser- vice and its operations which are executed in an ordered sequence according to a set of business rules. A service similarity matching algorithm is proposed to address the various degree of similarity in the qualitative matching
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 2
ISSN 2229-5518
level. A multi-level matching frame work for modeling web services are achieved in five different levels syntac- tic, static semantic, dynamic semantic, qualitative servic- es, dependable services and collaborative design for de- monstrating these approaches. The appropriate measur- ing of distance of different services and their similarity relations between the sequences are based on the non computable notations and shows all its computable simi- larities globally and this computable similarity measure is similarity metrics as discussed [5], [7], [10], [12], & [15]. The UDDI registry by an approach for web service re- trieval based on the evaluation of similarity between web services interfaces are defined with web service descrip- tion language (WSDL). The higher the similarity and the less are the difference among their interfaces. A semantic oriented variant approach was proposed and discussed in [1], [8], [9], [11], & [13] as a language to annotate a WSDL description. Effective web service retrieval algorithm and to evaluate the similarity degree between two web servic- es by comparing the related WSDL descriptions and the relation between the main elements composing a WSDL description by means of port Type, operation, message, and part Type. The automatic semantic categorization of web services are enabled by categorizing the pre-defined terms to calculate the sum of measure of semantic rela- tedness, nearest similarity score which are extracted from WSDL of a web service discussed in [2], [14], [17], & [19]. The measures of semantic relatedness are statistical me- thods for extracting word associations of text from WSDL. Vector based and probability based measure of semantic relatedness to find the point of mutual information and the normalized service distances are easily identifiable. A scalable similarity search for learned metrics and their pair wise similarity was measured using the Mahalanobis distance function enables efficient indexing with learned distances with a very large database as discussed in [3], [16], [18], & [21]. This approach to evaluate the impact on accuracy a learned metric has relative to both standard baseline metrics and state of the art methods and to test how reliably our semi-supervised hash functions preserve the learned metrics in practice when performing sub li- near time database searches. Simple Object Access Proto- col (SOAP) [1], [2], [4], [20] based multicast protocol (SMP). The SMP reduces the network traffic by aggregat- ing syntactically similar SOAP messages to form a com- pact SMP message to the service requesters. The similari- ty of SOAP message is measured in pairs and both based on the message template and on the values of each XML tag in the message as discussed [20], [22], [24]. For mea- suring the similarity of semantic services and their com- patibility by annotated with Web Ontology Language (OWL) ontology. This technique to OWL-S an emerging standard based on the inference as discussed [6] and this
are defined with the WSDL [1] and the clarification by semantically enriching the WSDL specifications in a se- mantic explanation. The method of enabling the scalable similarity search for learned metrics by finding the Maha- lanobis distance function by construction of enabling the hashing construction indexing [23] in retrieved services.
The service categorization and discovery is based on the keywords [2] which are extracted from WSDL and measuring the semantic relatedness of each word with predefined category then finding the nearest similarity score. The similarity based SOAP multicast protocol to address the issue of latency service, the similarity of SOAP message is measured in pairs and is based on the message template [4] and on the value of each XML tag in the message. Finding valuable and attractive web services are becoming difficult due to massive number of web services, mining web service frame work in which the fuzzy logic, fuzzy set theory and fuzzy matching for those services into composite web services [5], [6] and finding the service similarity metrics.
This proposal states the web service retrieval based on the evaluation of similarity between the services in which the service descriptions are adopted from Web service Description Language (WSDL), Simple Object Access Pro- tocol (SOAP), Universal Description, Discovery and Inte- gration (UDDI) and XML schema.
i. To identify the similarity in services by finding the replica of port type, operations, message, functions, prototypes, in and out parameters, parts etc from SOAP, UDDI, WSDL, and XML schema registries.
ii. Reducing the complexity of evaluating the words and phrases extracted from WSDL by introducing an im- proved clustering algorithms.
iii. To identify the semantic relatedness of keyword to find the similarity, machine learning techniques can reduce the complexity of extracting from WSDL.
iv. To identify the ontology based service similarity to
match the degree of service recommendation by hy-
brid match making algorithms and techniques in
schemas.
v. To identify the web ontology language OWL similari-
ty functions by targeting inference based matching
with generic clustering algorithms.
vi. To evaluate the scalable similarity of Mahalanobis
distance from very large database by means of intro-
ducing the advance hashing algorithm for implicit
and explicit parameters existing in service.
vii. To explore a generic similarity service view in auto- mated discovery of mediation by identifying the means of scalability.
ontology based techniques and metrics similarities are viii. A statistical approach for service value decomposi-
under development by the research teams. The approach of UDDI registry for web service retrieval based on the evaluation of similarity between web services interfaces
tion to find the balance point accuracy and ranking of
web services based on QOS attributes and cosine val-
ues.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 3
ISSN 2229-5518
ix. Exploiting a linguistic semantics search instead of plain key word based search will make the similarity selection of web service more appropriate.
x. Introducing a retrieval frame work by identify the similarity in service to improve the sophisticated si- milarity measures in XML service retrieval.
xi. To find the similarity in services an improved fuzzy similarity algorithm can improve the scalability among the services.
Heuristic and complex schema matching algorithms for both functional and non functional semantic distance for finding the web service similarity and the process model search.
The proposed approach can be identified by means of extracting details from different services of UDDI regi- stry, SOAP, WSDL, and XML schema applies the pro- posed model and it’s easy to identifying the similarity metrics from any service. To realize the strategies men- tioned in this proposed project, the following metrics are used in different phase to identify the similarity in web service.
![]()
![]()
The different similarity functions from web services are identified on certain parameters like port type, opera- tion name, input message, data type similarity, informa- tion loosed maximization function and similarity func- tions from the service.
MaxSim (f, Q, P) = .max (1)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
, P (aq) =
R (aq) =
![]()
Where oq is the query, Ioq is the returned services after submitting the query, and Roq is the relevant services for the given query. Precision and recall are measures for the entire result set without considering the ranking order. Thus, R-Precision and AP (Average Precision) parameters are also considered. Both of them depend on the precision at a given cutoff point (Pn). Thus, assuming as the set including the first n returned services
Similarity in words in different services are denoted by lexical meaning between two words for example W1 and W2 are two words in WSDL document then the SimSet (Set1, Set2). The set denotes by S1 and S2 and their func- tional similarity value can be calculated as Sim (S1, S2),
Sim (S1, S2) = a * SimSet (S1.T, S2.T) +
B * SimSet (S1.B, S2.B) +
![]()
r * SimSet (S1.A, S2.A)
Sim (S1, S2) = (2)
S, T collection of words in service title information B denotes the service body information, A denotes the ser- vice additional information, and T, B and A represents the weights in similarity computation, a, p, y are coefficients of different parts.
The Web Services are initially categorized under seven different categories Zip Code, Country Information Stock Market, Temperature, Weather, Fax and Currency. The extracted words of a particular Web Service are compared with each category from the WSDL of a web service (pressure, humidity, rainfall etc). The NSS (Normalized Similarity Score) of each word was calculated with cate- gory. We use the probability-based MSR – Normalized Similarity Score (NSS). NSS is an MSR that is derived from NGD. To be more precise, the relatedness between two words x and y is derived by NSS(x, y) =1-NGD(x, y)
Where NGD is a formula derived by cilibrasi and de-![]()
rived as
NGD (x, y) = (3)
![]()
Consider two concepts that belong to a same ontology, the similarity between them are calculated by the follow- ing equation
Sim (C1, C2) = (4)
Where l stands for the shortest path length between the two concepts in the ontology, and h stands for the depth of the closest common ancestor of the two concepts. The explanation of this measure is apparent. f1 takes into ac- count the influence of the path length. The similarity be- tween the two concepts decreases at an exponential rate as the path length increases. f2 reveals the influence of the concepts depth. Deeper a concept in the ontology, more concrete concept that means, a pair of deeper concepts will share more common information comparing with a pair of shallower concepts, when the path lengths of the two pairs are equal.
![]()
Distance metric for semantic nets and similarity for on- tology framework and the semantic similarity was calcu- lated by the similarity of OWL objects a and b is formally defined as
Sim (a, b) =
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 4
ISSN 2229-5518
![]()
0 � sim � 1
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
We have the similarity metric by inference based in- formation value, for any OWL object a and b
Sim (a, b) = (5)
fcommon is the common function measuring the in- formation value of the description that is shared between a, b. fdesc is the description function giving the value of the total information content of a and b. The similarity is defined as the ratio of the shared information between the objects to the total information about both objects. From the definition of the similarity function, sim, we can im- mediately obtain some properties that confirm some of the common intuition regarding similarity.
Metrics learning by similarity search and locality sensi- tive hashing in web service environments main idea of our approach is to learn a parameterization of a Mahala- nobis metric based on provided labels or paired con- straints while simultaneously encoding the learned in- formation into randomized hash functions. These func- tions will guarantee that the more similar inputs are un- der the learned metric, the more likely they are to collide in a hash table. After constructing hash tables containing the entire database examples, those examples similar to a new instance are found in sub linear time in the size of the database by evaluating the learned metric between the new example and any example with which it shares a hash bucket. Parameterized Mahalanobis Metrics was proposed by means of![]()
dA (xi, xj) = (xi- xj)I A (xi- xj)
SA (xi, xj) =
By parameter zing the hash functions instead by G (which is computable since A is p.d.), the following rela- tionship express the hash functions by means of described sample inputs![]()
![]()
Pr [ ] = 1-
![]()
![]()
![]()
{ ![]() } (6)
} (6)
Semantic web service mediation as used throughout the remainder of SWS either the description of the web service or the description of service request and it is for- mally represented with in a particular ontology that com- plies with a certain SWS reference model and defines the semantic similarity between two service members of a![]()
space as a function of the ECD (Euclidean Distance). Euc- lidean distance between the points representing each of the members, the different distance metrics could be con- sidered based on the nature and purpose of the MS and the definitions of MS given by V, U expressed by vectors V0,V1,…..Vn and U1,U2,…..Un within the MS and their dis- tance can be calculated as
Dist (u, v) = 2
A similarity based mediation service can be provided as a general purpose mediator and can be implemented as a particular mediation service in which (MWS1, MWS2) are the standard web services and denotes the ontological refinement of SWSi as a service request description. Con- sequently mediation services MWS computes a set of x sets of distance Dist (SWSi) = {Dist (SWSi, SWSj), Dist (SWSi, SWSj)…Dist (SWSi, SWSx)}
Where each Dist (SWSi, SWSj) contains a set of distance![]()
{dist1…distn}![]()
Sim (SWSi, SWSj) = ( ) -1 =
-1 (7)
Improving the semantic web services discovery through similarity search in services by means of Metric Space M=<D, d> where domain D is a collection of web services and distance function d is the semantic similarity between requester and web services. A semantic web ser- vice modeled in metric space is a triple SWS=<FS, NFS, FW> such that FS is the functional semantics, NFS is the non-functional semantics and FW is the description framework. The functional semantics of SWS is defined as a quadruple of functional features FS=<EX, RE, PR, OU> such that EX describes what a web service expects for enabling it to provide its service, RE describes what a web service returns in response to its input, PR describes con- ditions over the world state to met before service execu- tion, and OU describes the state of the world after the execution of the service. The non-functional semantics of SWS is defined as a triple of non-functional features NFS![]()
= <Q, SP,CP> such that Q is a set of QOS parameters of- fered by the service, SP is a set of service specific parame- ters, and CP is context policy Distance measure is defined as semantic similarity based on functional semantics
dM (SWS R, SWS A) = (8)
![]()
Similarity measures for business process models such as label similarity is one way of measuring the similarity between a pair of process models and relation between elements in one model and elements in other models
(9) Where Siml is a similarity measure between pairs of model elements the similarity between model elements
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 5
ISSN 2229-5518
can be computed from their labels using syntactic similar- ity measures, semantic measures, or a combination of both. Syntactic measures are based on string-edit dis- tance, n-gram, morphological analysis (stemming), and stop-word elimination techniques, whereas semantic techniques are based on synonym and other semantic relations captured. The structural similarity measures are processed as per distance.
![]()
Heuristic search and similarity flooding search algo- rithm A* algorithm was adopted here to find the distance between the services in N-M mapping O (mn) is the worst case in this condition. Fuzzy similarity clustering for the consumer centric for selection of web services, the simi-
larity between can be obtained via the equation![]()
![]()
![]()
(10)
![]()
![]()
![]()
We can find the average agreement degree (AAD), de- noted as A ( ) in the form![]()
![]()
![]()
The RAD (Relative Agreement Degree) for each indi- vidual opinion uses the RAD equation as given below![]()
Similarly to obtain the CDC (Consensus Degree Coeffi- cient) for each participant can be obtained by the equation![]()
![]()
![]()
![]()
The aggregate fuzzy opinions by the CDC can be de- termined as![]()
Thus the AAD, RAD and CDC equations helps to find the similarity in different services.
Service discovery and integration of similar service and ranking it Current web service description model fails to provide sufficient information to enable ranking mechan- ism for service web, but at the same time, due to the fast growth of web services, ranking becomes more and more important for a web user to easily find an appropriate service. Thus, to enrich semantic aspect of a service de- scription for ranking, Anchor Semantic Description Mod- el (ASDM) is proposed to incorporate request semantics and reputation as anchors into a service description. ASDM provides an easy and automatic approach to en- hance service descriptions on semantic aspect. It is simp- ler than the complex OWL-S but can include more infor-![]()
mation than the document element of WSDL. Selection usage level indicates that the retrieved service operation is selected by the service requestor to view its detailed information. When a service selection action is captured, the use Frequency of s-anchor element of the correspond- ing service operation will increase 1. Composition usage level indicates that a retrieved service operation is se- lected and composed into a service application. When a service composition action is captured, the use Frequency of c-anchor element will increase 1 while the use Fre- quency of s-anchor element will decrease 1 for the corres- ponding service operation![]()
![]()
(11)
Ranking by means of DScore and to compute the simi- larity between request description and anchor semantic elements it has a property use frequency and a term list with VSM between request description and anchor se- mantic elements of a service operation should firstly be represented as a vector.![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Where sr, cr, dr, and rr are the reputation values of the four different usage levels; and Ts ,Tc ,Td and Tr are the occurring times of the given term in each anchor se- mantic element. The AScore ranking also found by using the cos (Dr, Da)![]()
![]()
(12)
high frequency of service using leads to high quality by RScore in the mean of sr U, F, cr, dr, rr where UFs, UFe, UFd, UFr are the frequency of the four different anchor semantic elements and it is demanded by,
RScore=sr x UFs + cr x UFe + dr x UFd + rr x UFr![]()
Similarity in query retrieval with ranking for XML ser- vices and their similarity string and a set of services de- scriptions![]()
![]()
![]()
(13)
In this equation, wqj is a weighted vector for a word in a query vector, and wid is a weighted vector for a word in a service descriptions. We also use the following method to apply similarity of child entries in the hierarchical structure of service descriptions for measuring upper de- scription similarity. Current Web service discovery me- chanisms can be classified into three categories. Registry- based discovery like UDDI, Semantic annotation and dis- covery, Similarity-based search calculate term frequencies according to their position. By evaluating the different phase (i.e. from phase 1 to Phase 11) and by using equa- tions 1 to 11 the calculation of similarity by means of me- trics are described in this work. Identifying the related service and their functionality in these competitive global service providers marked as a robust task in web service
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 6
ISSN 2229-5518
world. Fig.1 demonstrates an overview of finding similar- ity in the web environment.
i. Client request ii. Query Handler iii. Query Processor
iv. Request Transporting
v. Registry Handler
vi. Response by XML
vii. Request Execution
viii. Save and Retrieve
ix. Registry Data Storage
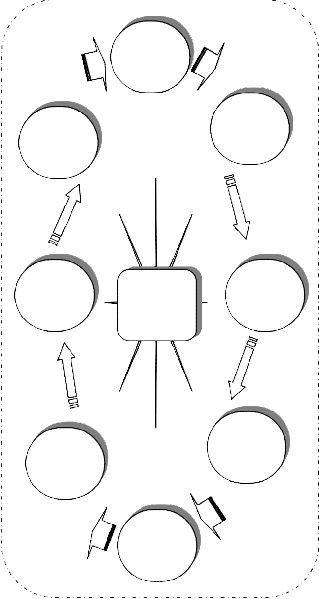
End-user and customers demand get processed with high demand and priority as per the request.
Client
Request
The demand and request of different users across glo- bally routed in correct direction with the help of query handler.
As per the request and demand of query handler and end-users, their overall workstation get activated and compared with huge data sets presented in their ware house.
The communication among various components and
elements are by passed with necessary commands and triggers via proper channel and optimized path.
Maintenance of huge database and ware house of dif- ferent set of service requests are organized in the form of registry by the help of Registry Handler.
Save & Retrieve
Query
Handler
To achieve interoperability as a key feature across the web world the supportive language XML was used to obtain it more consistently.
Client request, Query Handler, Query Processor, Re-
quest Transporting, Registry Handler, and Response by
XML stands in queue for execution in various environ- ment and critical situations etc.
Request Execu- tion
Re- sponse by XML
Registry Data Sto- rage
Registry
Handler
Query Proces- sor
Request Trans- porting
Requesting services are collected by Registry Handler and processed by request executor in various aspects with respect to its own database registry.
Bulk and huge data set information are collected from various service providers to maintain registry set up as per the conditional requests. All datasets get shuffled periodically based on its updating level.
Verdict various related issues in web environment and solving it in a matter of time, our proposed phases pin points stipulated support to web environmental world. A bulky Web services will be offered in the future, which may have the related or the similar utility, situated in un- usual places and furnish by different providers across the internet. The optimization of similar service from differ- ent web services are grouped and alerted on nonfunc- tional requirements such as routine, expenditure and con-
Fig.1. Identifying similarity’s in different slice.
fidence etc. The proposed approach can assure the Up-
coming research proposals contemplates to find the simi-
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 6, June-2011 7
ISSN 2229-5518
larity in different networks with infinite ranking and un- usual query retrieval in universal web world.
[1] Pierluigi Plebani and Barbara Pernici,”URBE: Web Service Retrieval Based on Similarity Evaluation”, IEEE Transaction on Knowledge and Data Engineering, Vol.21, No.11, Nov-2009.
[2] Shalini Batra, Seema Bawa, Thapar University, “Web Service Categori-
zation Using Normalized Similarity Score”, ”International Journal of
Computer Theory and Engineering”, Vol.2, No.1, Feb-2010.
[3] Brian Kulis, Prateek Jain, and Kristen Grauman, “Fast Similarity Search for Learned Metrics”, IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, Vol.31, No.12, Dec-2009.
[4] Khoi Anh Phan, Zahir Tari, Peter Bertok, ”Similarity-Based SOAP Multicast Protocol to reduce Bandwidth and latency in Web Services”, “IEEE Transaction on Services Computing”, Vol.1, No.2, Jun-2008
[5] Ming Li, Xin Chen, Xin Li, Bin Ma, Paul M.B.vitanyi, ”The Similarity Metric”, ”IEEE Transaction on Information Theory”, Vol.50, No.12, Dec-2004
[6] Khurram Shehzad, Muhammad Younus Javed, ”Multithreaded Fuzzy
Logic Based Web Services Mining Framework”, “European Journal of
Scientific Research”, Vol.41, No.4, 633-645, 2010.
[7] Jeffrey Hau, William Lee, John Darlington, “A Semantic Similarity
Measure for Semantic Web Services”, “IEEE Conference”, May-2005
[8] Min Liu, Weiming Shen, Qi Hao, Junwei Yan, “A Multilevel Match Making Frame Work for Semantic Web Service in Collaborative De- sign”, “International Conference on Computer Supported Cooperative Work in Design”, April 2008, pp. 392-398
[9] Xianyang Qu, Hailong Sun, Xiang LI, Xudong, Wei Lin, “A WordNet- Based Web Service Similarity Mining Mechanism”, IEEE-Conference- JAN-2009.
[10] Shalini Batra, Seema Bawa, “Web Service Categorization Using Norma-
lized Similarity Score”, International Journal of Computer Theory and
Engineering, Vol. 2, No. 1 February, 2010 1793-8201.
[11] Haoxiang Xia, Taketoshi Yoshida, “Web Service Recommendation with
Ontology-based Similarity Measure”, IEEE Conference-2009.
[12] Jeffrey Hau, William Lee, John Darlington, “A Semantic Similarity
Measure for Semantic Web Services”, IEEE-Conference-2007.
[13] Ricardo Mendoza Gonzalez, “Web Service-Security Specification based on Usability Criteria and Pattern Approach”, Journal of Computers, Vol. 4, No. 8, AUGUST 2009.
[14] Stefan Dietze, Alessio Gugliotta, John Domingue, "Exploiting Metrics for Similarity-Based Semantic Web Service Discovery", ICWS, pp.327-
334, IEEE International Conference on Web Services, 2009.
[15] Minghui Wu, Fanwei Zhu, Jia Lv, Tao Jiang, Jing Ying, tase, "Improve Semantic Web Services Discovery through Similarity Search in Metric Space", Third IEEE International Symposium on Theoretical Aspects of Software Engineering, pp.297-298, 2009.
[16] Marlon Dumas, Luciano Garcia-Ba nuelos, Remco Dijkman, “Similarity
Search of Business Process Models”, IEEE Conference -2009
[17] Wei-Li Lin, Chi-Chun Lo, Kuo-Ming Chao, Nick Godwin, “Fuzzy Similarity Clustering for Consumer-Centric QOS-aware Selection of Web Services”, International Conference on Complex, Intelligent and Software Intensive Systems-2009.
[18] Jing Luo, Ying Li, “Anchor Semantics Enabled Ranking Method for
Service Discovery and Integration”, 2008 IEEE International Conference
on Web Services.
[19] Shirin Sohrabi and Sheila A. McIlraith, ISWC 2009, LNCS 5823, “Opti- mizing Web Service Composition While Enforcing Regulations”, pp.
601–617, 2009, Springer
[20] Kyong-Ha Lee, Mi-young Lee, Yun-Young Hwang, Kyu-Chul Lee, “A Framework for XML Web Services Retrieval with Ranking”, 2007 In- ternational Conference on Multimedia and Ubiquitous Engineering IEEE.
[21] Jing Luo, Ying Li, “Anchor Semantics Enabled Ranking Method for Service Discovery and Integration”, 2008 IEEE International Conference on Web Services.
[22] Shrabani Mallick, D. S Kushwaha, “An Efficient Web Service Discovery Architecture”, International Journal of Computer Applications Vol.3 – No.12, July 2010.
[23] Hoi Chan, Trieu Chieu and Thomas Kwok, “Autonomic Ranking and Selection of Web Services by Using Single Value Decomposition Tech- nique”, 2008 IEEE International Conference on Web Services.
[24] Manish Godse, Rajendra Sonar, “The Analytical Hierarchy Process Approach for Prioritizing Features in the Selection of Web Service”, In- dian Institute of Technology Bombay, India, Shrikant Mulik, L& T Info- tech Mumbai, India.
IJSER © 2011 http://www.ijser.org