Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 1
ISS N 2229-5518
A Hybrid Metaheuristic Algorithm for Classification using Micro array Data
Mrs.Aruchamy Rajini, Dr. (Mrs.) Vasantha kalyani David
Abs tract—A metaheuristic algorithms provide eff ective methods to solve complex problems using f inite sequence of instructio ns. It can be def ined as an iterative search process that eff iciently perf orms the exploration and exploitation in the solution space aiming to eff icient ly f ind near optimal solutions. This iterative process has adopted various natural intelligences and as pirations. In this w ork, to f ind optimal solutions f or microarray data, nature-inspired metaheuristic algorithms w ere adapted. A Flexible Neural Tree (FNT) model f or microarray data is created using nature-inspired algorithms. The structure of FNT is created using the Ant Colony Optimization (ACO) and the parameters encoded in the neural tree are optimized by Firef ly Algorithm (FA). FA is used to produce near optimal solutions and hence it is superior to the existing metaheuristic algorithm. Experime ntal results w ere analyzed in terms of accuracy and error rate to converge to the optimu m. The proposed model is compared w ith other models f or evaluating its perf ormance to f ind the appropriate model.
Ke ywords --- ACO, FNT, FA, Metaheuristic, Nature-inspired
—————————— ——————————
1.0 INTRODUCTION
In the r ecent decades, r esear cher s have developed many optimization computation appr oaches to solve complicated pr oblems by lear ning fr om life system. Optimizing r eal-life pr oblems is challenging because of huge, complex and noisy solution space. Resear cher s have pr oposed appr oximate evolutionary-based or met aheur istic algorithms as means to search for near -optimal solutions [ 1].Optimization pr oblems ar e solved using appr oximate mathematical sear ch techniques.
These computational systems that mimic the efficient behavior of species such as ants, bees, birds and fr ogs, as a means to seek faster and mor e r obust solutions to complex and noisy optimization pr oblems. The evolutionary based techniques intr oduced in th e literatur e w er e Genetic Algorithm or GA [2], Memetics Algorithm or MAs [2], Shuffled Fr og Leaping Algorithm or SFLA [2], Fir efly Algorithm or FA [3, 4, 5], Bees Algor ithm or BEES [6,
7],Harmony Sear ch Algor ithm or HSA [8], Neur al Networ k or NN [9], Ant Colony Optimization or ACO [10], Evolutionary Pr ogr amming or EP [11], Differ ential Evolution
or DE [12] and Particle Swar m Optimization or PSO [13]. Mor eover , ther e ar e some with the socially-based inspiration, e.g.Tabu Sear ch or TS [14] and the physically -based inspiration such as Simulated Annealing or SA [15]. These algor ithms have been w idely used in many social and industr ial ar eas. These kinds of algorithms for scientific computation ar e called as ‘‘Ar tificial-Life Computation‛.
———— ——— ——— ——— ———
Aruc hamy Rajini, Assistant Pro fe sso r, De partme nt o f Co mpute r Applic atio ns,Hindusthan Co llege o f Arts Sc ie nce ,Co imbato re, TamilNadu, Indi a. E-mail a ruchamy_ra jini@yahoo.co.in
Dr. (Mrs.) V asantha kaly ani Dav id Assoc iate Pro fesso r,
A r elatively new family of natur e inspir ed metaheuristic algor ithms known as Swarm Intelligence (SI) has emer ged r ecently, which is known for its ability to pr oduce accurate solutions to complex sear ch pr oblems. This is focused on insect behavior in or der to mimic insect’s pr ob lem solution abilities. The social insect colonies ar e focused on the inter action betw een insects contr ibuting to the collective intelligence.
Gener ally, meta-heuristics w or k as follows: a population of individuals is randomly initialized wher e each individual r epr esents a potential solution to the pr oblem. The quality of each solution is then evaluated via a fitness function. A selection process is applied dur ing the iteration of metaheur istic in or der to form a new population. The searching pr ocess is biased toward the better individuals to incr ease their chances of being included in the new population. This pr ocedur e is r epeated until conver gence r ules ar e r eached [16].
A paradigm for designing metaheuristic algor ithms is Ant Colony Optimization (ACO), which is a technique for solving combinator ial optimization pr oblems .The inspir ing source of ant colony optimization is the for aging behavior of r eal ant colonies. Though they live in colonies, they follow their own r outine of tasks independent of each other . They per form many complex tasks necessary for their survival. They per form parallel sear ch over sever al constructive thr eads based on local pr oblem data and also have a dynamic memory str uctur e w hich contains information on the quality of pr eviously obtained r esults.
The meta-heur istic algor ithm, which idealizes some of the flashing char acter istics of fir eflies, has been r ecently developed and named as Fir efly algor ithm (FA). Natur e inspir ed methodologies ar e curr ently among the most
De partme nt o f Co mpute r Sc ie nce Av inashiling am De e me dIJSER © 2012 http :// www.ijser.org
Univ e rsity , Co imbato re TamilNadu, Indi a
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 2
ISS N 2229-5518
pow er ful algorithms for optimization pr oblems. Fir efly algor ithm is a novel natur e-inspir ed algor ithm inspir ed by social behavior of fir eflies. Fir eflies ar e one of the most special, captivating and fascinating cr eatur e in the natur e. Most fir eflies pr oduce short and r hythmic flashes though ther e ar e about tw o thousand fir efly species . The r ate and the rhythmic flash, and the amount of time form part of the signal system which br ings both sexes together . Ther efor e, the main part of a fir efly's flash is to act as a signal system to attract other fir eflies. By idealizing some of the flashing char acteristics of fir eflies, the fir efly-inspir ed algor ithm w as pr esented by Xin-She Yang [3]. In this paper the author ’s pr evious w or k [17] is extended to experiment the model w ith differ ent cancer sets. The obj ective of this paper is to investigate the per formance of Fir efly and EPSO algor ithm to find optimal solutions with differ ent micr oarray data.
In modern numer ical optimization, biologically inspired algorithms ar e becoming power ful. From the existing metaheur istic algorithms, Fir efly Algor ithm (FA) is the super ior and solves multim odal optimization pr oblems. A Fir efly Algor ithm deals with multimodal functions mor e naturally and efficiently.
The Flexible neur al tr ee (FNT) [18] has achieved much success in ar eas of classification, r ecognition, appr oximation and contr ol. In this paper , a tr ee-structur ed neural networ k is cr eated. A FNT model can be cr eated and evolved, based on the pr e-defined instruction/operator sets . FNT allows input var iables selection, over -layer connections and differ ent activation functions for differ ent nodes. The tr ee structur e is cr eated using Ant Colony Optimization (ACO) and the parameters encoded in the structur e ar e tuned using Fir efly Algor ithm (FA).
The r emainder of this paper is or ganized as follows: Section II gives the basic model of FNT. Section III descr ibes the tr ee structur e and the parameter lear ning. Section IV pr esents exper iment r esults of various cancer data sets to show the effectiveness and r obustness of the pr oposed metaheuristic method. The conclusion is summar ized in Section V and it is follow ed by r efer ences.
2.0 THE B ASIC FLEXIBLE NEURAL TREE.
A special kind of Artificial Neural Netw or k (ANN) is FNT with flexible neural tr ee str uctur es. The flexible tr ee str uctur e is the most distinctive featur e, w hich make it possible for FNT to obtain near-optimal netw or k structur es using tr ee str uctur e optimization algor ithms
The FNT model has two stages in the optimization. Firstly the tr ee structur e is optimized using tr ee str uctur e evolutionary algor ithms like genetic pr ogr amming (GP) [20], pr obab ilistic
incr emental pr ogram evolution algor ithm (PIPE) [19], extended compact genetic pr ogramming (ECGP), and immune pr ogr amming (IP) [21], w ith specific instr uctions. A tr ee structur e population is gener ated at the beginning of the optimization pr ocess .Each structur e in the population is then evaluated and the best one is selected. After selecting the best structur e, the next stage is to optimize the parameters of this structur e .The fine tuning of the par ameters in the str uctur e could be accomplished using simulated annealing (SA) [19], particle swarm optimization (PSO) [22], memetic algorithm (MA) [20].
A new tw o-stage optimization is executed and t his iterative pr ocess is called the evolving pr ocess of FNT model. Each time a new str uctur e has been foun d, the parameters of this new structur e has to be optimized. It means both the tr ee structur es and parameters ar e to be optimized [23] .
By using tr ee str uctur e optimization algorithm, it is r elatively easy for a FNT model to obtain near-optimal structur e. The leaf nodes of FNT ar e input nodes and the non -leaf nodes ar e neur ons. The r oot node output is also the output of the whole system. FNT model use tw o types of instruction sets, the function set F and terminal instr uction set T for constructing nodes in tr ee structur es. F is used to construct non -leaf nodes and T is used to constr uct leaf nodes. They ar e descr ibed as
S = F U T = {+2 ,+3 , . . . ,+N}U{x1 , . . . , xn},
wher e +i(i = 2, 3, . . .,N) denote non-leaf nodes’ instr uctions and taking i ar guments. x1 ,x2 ,. . .,xn ar e leaf nodes instr uctions and taking no other ar guments. The output of a non-leaf node is calculated as a flexible neur on model (see Fig.1). Fr om this point of view, the instr uction + i is also called a flexible neur on operator with i inputs.
In the cr eation process of neur al tr ee, if a nonterminal instruction, i.e., +i(i =2, 3, 4, . . .,N) is selected, i r eal values ar e randomly gener ated and used for r epr esenting the connection str ength between the node + i and its childr en. In addition, tw o adjustable par ameters ai and bi ar e randomly cr eated as flexible activation function parameter s and their value r ange ar e [0, 1]. For developing the for ecasting model, the flexible activation function f (ai, bi, x) = e− ((x − ai)/bi )2 is used.
The total excitation of +n is
ne tn = ∑nj=1 wj * xj,
wher e xj (j = 1, 2, . . ., n) ar e the inputs to node + n and wj ar e generated r andomly with their value range ar e[0,1].The output of the node +n is then calculated by
outn = f(an, bn, netn) =e− ( (netn− an)/ bn)2 .
IJSER © 2012 http :// www.ijser.org
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 3
ISS N 2229-5518
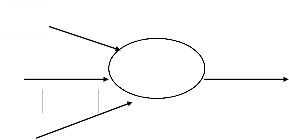
The overall output of flexible neur al tr ee can be computed fr om left to r ight by depth-first method, r ecursively [24].
X1
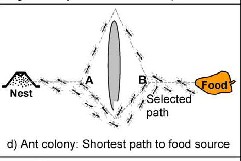
by the foraging behavior of r eal ants. The ants ar e able to find the shortest r oute betw een their nest and sour ce of food due to the deposition of pher omone in the path. This pher omone trails for m has an indir ect communication and each ant pr obabilistically pr efers to follow the dir ection r ich in this chemical.
w1
w2 + n
X2
w3

X3
f(a,b)
Y
As shown in Fig 2, when ants leave their nest to sear ch for a
food sour ce, they r andomly r otate ar ound an obstacle, and
initially the pher omone deposits w ill be the same for the r ight and left dir ections. W hen the ants in th e shorter dir ection find a food sour ce, they carry the food and star t r etur ning back, follow ing their pher omone trails, and still depositing mor e pher omone. As indicated in Fig. 2, an ant will most likely choose the shor test path when r etur ning back to the nest w ith
food as this path w ill have the most deposited pheromone. For the same r eason, new ants that later starts out from the
Output
Layer 6
nest to find food will also choose the shortest path. Over time, this positive feedback (autocatalytic) pr ocess pr ompts all ants to choose the shorter path [2].
Second hidden layer
+2 +3 +3
X1 X2 X3
Firs t hidden layer
Input layer
X1 X2 +2 X3
X1 X2 X3 X3 X2 X1 X2 X3
Fig 2: Schematic Diagram of ACO
In the ACO, the pr ocess starts by gener ating m random ants, wher e each ant w ill build and modify the tr ees based on the quantity of pher omone at each node. Each node is memor ized with a rate of pher omone and is initialized at 0.5, which means that the pr obability of choosing each terminal and function is equal initially . At the start, populations of pr ograms ar e r andomly generated. If the rate of pher omone is
Fig 1. A flexible neur on model and its typical r epr esentation
of the FNT w ith function instr uction set F = {+2 ,+3 ,+4 ,+5 ,+6 }, and
terminal instr uction set T = {x1 , x2 , x3 } (r ight)
3.0 TREE S TRUCTURE AND P ARAM ETER LEARNING.
3.1 Tree Structure Optimization
The str uctur e of the FNT model is optimized using Ant Colony Optimization (ACO). ACO is a pr obabilistic technique developed by Dor igo et al.[10]. This technique was inspir ed
higher , then the pr obability to be chosen is also higher . Each
ant is then evaluated using a pr edefined obj ective function
which is given by Mean Squar e Err or (MSE) [24].
Fit (i) =1/p ∑p j= 1 (At - Ex)2 (1 )
Wher e p is the total number of samples, At and Ex ar e actual and expected outputs of the j th sample. Fit(i) denotes the fitness value of the ith ant.
Ther e ar e tw o mechanisms to update the pher omone:
IJSER © 2012 http :// www.ijser.org
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 4
ISS N 2229-5518
– 1. Trail Evaporation: - Evaporation decr eases the r ate of pher omone for every instruction on every node, in or der to avoid unlimited accumulation of tr ails, according to follow ing for mula:
Pg = (1 − α) Pg−1 (2)
wher e Pg denotes the pher omone value at the gener ation g, α is a constant (α = 0.15).
– 2.Daemon actions: - The components of the tr ee will be r einfor ced accor ding to the Fitness of the tr ee, for each tr ee. The formula is
Pi,s i = Pi,s i + α (3)

Fit(s)
wher e s is a solution (tr ee), Fit(s) its Fitness, si the function or the terminal set at node i in this individual, á is a constant (á =
0.1), Pi,si is the value of the pher omone for the instr uction si
in the node i[24].
The algor ithm is br iefly described as follows:(1) every component of the pher omone tr ee is set to an aver age value; (2) r andom generation of tr ee based on the pher omone; (3) evaluation of ants (4) update of the pher omone; (5) go to step (1) unless some cr iter ia is satisfied[24].
3.2 Parameter learning Op timization
Ther e ar e a number of lear ning algorithms such as GA, EP, and PSO that can b e used for tuning of parameters (w eights and activation parameter s) of a neural tr ee model.
The flashing behavior of fir eflies has inspir ed the development of a metaheuristic algorithm known as fir efly algorithm (FA). The fir eflies ar e cr eatur es that generate light inside of it, which is due to the chemical r eaction. The bioluminescence is a chemical pr ocess generated by the flashing light. The pr imary pur pose of the flashing of fir eflies is to act as a signal system to attract other fir eflies.
This can idealize the flashing character istics of fir eflies as to consequently develop fir efly algor ithm. The thr ee idealized r ules based on the flashing char acter istics of fir eflies, ar e as follows:
Rule 1: All fir eflies ar e unisex, so that one fir efly will be attracted to all other fir eflies. Each fir efly will attract all the other fir eflies with weaker flashes [25];
Rule 2: Attractiveness is pr oportional to their brightness, and for any tw o fir eflies, the less br ight one will be attr act ed (and thus move) to the br ightest one; how ever , the br ightness can decr ease as t heir distance incr eases;
Rule 3: If ther e ar e no fir eflies br ighter than a given fir efly, it will move r andomly.
The brightness of a fir efly is determined by the landscape of the obj ective function. The br ightness can simply be pr oportional to the value of the obj ective function, for a maximization problem. The fir efly algor ithm has two impor tant issues to be consider ed. They ar e the var iation of light intensity and formulation of the attractiveness .The attractiveness of a fir efly determined by its br ightn ess or light intensity which in tur n is associated w ith the encoded obj ective function.
In the simple case for maximum optimization pr oblems, the br ightness I of a fir efly at a particular location x can be chosen as I(x) α f(x).
The attr activeness is r elative and so it var ies w ith the distance r ij between fir efly i and fir efly j . The attr activeness varies w ith the degr ee of absorption, as the intensity of light decr eases with the distance fr om its sour ce and the media absorbs the light.
In the simplest form, the light intensity I(r ) var ies w ith the
distance r monotonically and exponentially. That is
I=I0 e-γr (4)
wher e Io is the or iginal light intensity and γ is the light ab sorption coefficient. As a fir efly’s attractiveness is pr oportional to the light intensity seen by adjacent fir eflies, the attr activeness β of a fir efly can be defined by
β = β0 exp (-γr 2 ) (5)
wher e β0 is the attr activeness at r =0. It is w orth pointing out that the exponent γr can b e r eplaced by other functions such as γr m when m>0[4].
The distance betw een any tw o fir eflies i and j at Xi and Xj can be the Cartesian distance r ij= ||xi-xj||2 . For other applications such as scheduling, the distance can be time delay or any suitable forms, not necessar ily the Cartesian distance [4].
The movement of a fir efly i is attracted to another mor e attractive (br ighter ) fir efly j is determined by
IJSER © 2012 http :// www.ijser.org
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 5
ISS N 2229-5518
Xi=xi+β0 exp (-γr2 ij) (xj-xi) +α (r and-0.5) (6)
wher e the second term is due to the attraction, while the thir d term is randomization with α b eing the randomization parameter . r and is a random number generated uniformly distr ibuted in [0,1] [ 26].
Fir efly Algor ithm wor ks as follows:
1. Cr eate an initial population r andomly.
2. Light intensity of a fir efly is determined by its obj ective function.
3. Define Light absor ption coefficient γ and randomness α
in advance.
4. Move fir efly towar ds better br ighter ones.
5. Attractiveness varies with distance r thr ough exp[-γr ]
6. Evaluate new solutions and update light intensity.
7. If maximum iterations r eached, then stop; otherwise go to
step (4).
8. Rank the fir eflies and find the curr ent best [27].
It can be shown that the limiting case γ →0 corresponds to the standard Particle Swarm Optimization (PSO). If the inner loop (for j ) is r emoved and the brightness Ij is r eplaced by the curr ent global best g *, then FA essentially becomes the standar d PSO.
3.3 Pro cedu re of the Gen eral Learning Hybrid
Algorithm .
The pr oposed pr ocedur e interleaves both optimizations. It starts with r andom str uctur es and corr esponding parameters. It fir st tr ies to impr ove the str uctur e and then when the impr oved structur e is found, the parameter s ar e then tuned. It then goes back to impr ove the structur e again and, then tunes the structur e and parameters. This loop continues until a satisfactory solution is found or a time limit is r eached.
The general learning procedur e t o find or construct an optimal or near-optimal FNT model str uctur e and parameters optimization ar e used alter nately, combining the ACO and FA algorithm, a hybrid algor ithm for evolving FNT model is described as follows:
Step 1: Par ameters Definition: Par ameters ar e initialized first i.e, size of population, size of agent and so on.
Step 2: Initialization. An initial population is cr eated r andomly (set FNT tr ees and its corr esponding par ameters). Cr eate a FNT model M (t) r andomly limited by the given parameters
.Set t=0.
Step 3: W eights Optimization by fir efly algorithm. For each
FNT model (M0 (t),M1 (t),…,Mn(t)) the weights ar e optimized by fir efly algor ithm.
Step 4: Structur e Optimization by ACO. Cr eate a new population M (t+1) by ACO. Set t=t+1.
Step 5: Iter ation: the new solution is submitted to step 2 , the pr ocess continues iter atively until a stopping cr iter ia is met.
4.0 EXPERIMENT AL STUDIES
The main purpose is to compar e the quality of EPSO and FA, wher e the quality of these algorithms is measur ed in terms of err or r ate and accuracy.
4.1 Classification problem s
To compar e the per formance of EPSO and Fir efly algor ithms, thr ee classification pr oblems ar e used. They ar e:
-Br east cancer : The Wisconsin Pr ognostic br east cancer (W PBC) [28] data set has 34 attr ibutes (32 r eal-valued) and 2 classes w ith 198 instances. The methodology adopted for br east cancer data set was applied. Half of the observation was selected for tr aining and the r emaining samples for testing the per formance.
-Liver cancer : The liver cancer data set (http://genome- www.stanfor d.edu/hcc/) has two classes, i.e., the nontumor liver and HCC (Hepatocellular car cinoma). The data set contains 156 samples and the expr ession data of 1,648 impor tant genes. Among them, 82 ar e HCCs and th e other 74 ar e nontumor livers. The data set is randomly divided into 78 training samples and 78 testing samples. In this data set, ther e ar e some missing values and so the k-near est neighbor method is used to fill those missing values.
-Lymphoma cancer : In the lymphoma data set [5] (http://llmpp.nih.gov/ lymphoma), ther e ar e 42 samples der ived fr om diffuse lar ge B-cell lymphoma (DLBCL), nine samples fr om follicular lymphoma (FL), and 11 samples fr om chr onic lymphocytic leukemia (CLL). The entir e data set includes the expr ession data of 4,026 genes, randomly divided the 62 samples into two parts: 31 samples for training, 31 samples for testing.
4.2 Experimen tal setting s
The algor ithms EPSO and Fir efly algor ithm ar e applied to above thr ee datasets. For easy comparisons the algor ithms was made to r un for the same number of iterations .For EPSO, the learning par ameters w ith c1=c2=1.49 ar e used with the varying inertia. For FA, the par ameters α = 0.2, β0 = 1.0 and γ
=1.0 ar e used. Var ious populations sizes ar e used fr om n=15 to 100 and found that it is sufficient to use n= 15 to
50.Ther efor e a fixed number of population size is used for
both the models for comparison.
IJSER © 2012 http :// www.ijser.org
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 6
ISS N 2229-5518
4.3 Results and Di scu ssi on s
Table 1 summar izes the r es ults obtained fr om the two algor ithms which is applied to medical domain. Thr ee differ ent medical data sets ar e used to evaluate the per formance of the pr oposed ACO-FA algor ithm. This model is compar ed w ith ACO-EPSO to show its per for mance. In this wor k,the algor ithms ar e implemented in MATLAB. Both the models w er e trained and tested with same set of data. By applying ACO algor ithm an optimal tr ee structur e can be found. In this exper iment the input is the number of ant and the number of iterations. Each ant is made to r un for a specified number of iter ations. Each ant constr ucts a neural tr ee w ith its obj ective function which is calculated as MSE. The ant which gives the low MSE is taken to be the best tr ee for which the parameter s ar e optimized with EPSO a nd FA. The tr ee which pr oduces the low err or is the optimized neural tr ee and this extracts the informative genes.
Table 1
PERFORMANCE COMPARISION OF EPSO, FIREFLY ALGORITHMS
Pr oblem | Algorithm | Accuracy | Er r or rate |
Br east Cancer | EPSO | 86.49 | 8.00 |
Br east Cancer | Fir efly | 90.41 | 6.00 |
Liver data set | EPSO | 86.47 | 8.02 |
Liver data set | Fir efly | 90.41 | 6.50 |
Lymphoma data set | EPSO | 86.49 | 8.03 |
Lymphoma data set | Fir efly | 90.49 | 6.52 |
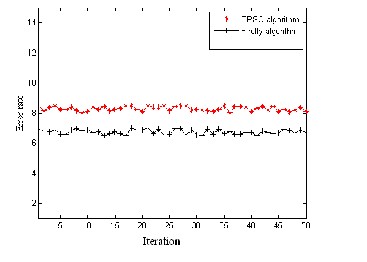
Var ious iterations imply that FA is mor e potentially pow er ful than EPSO for solving many optimization pr oblems. This is partially due to the fact that the br oadcasting ability of the curr ent best estimates gives better and quicker conver gence towar ds the optimality. As with differ ent cancer data set, it was w ell pr oven that the tr ee str uctur e w ith ACO and parameter optimization done with FA can achieve better accur acy and low err or rate compar ed with the other models. The main pur pose is to compar e the models quality w ith differ ent medical data set , wher e the quality is measur ed according to the err or rate and accuracy. The ACO-FA model has the smallest err or rate when compar ed with the other models. The tw o models ar e made to r un for the same number of iter ations and the r esults shows that ACO-FA success to r each optimal minimum in all r uns. This method
gives the best minimum points b etter than the other model. This is depicted in the following figur es.
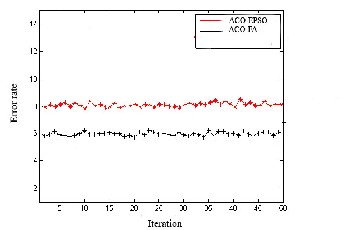
In Figur es 3 to 5, it shows that the error rate of the model ACO-FA is low when compar ed w ith ACO–EPSO for thr ee medical data sets. Fr om the figur es shown below it depicts that the accur acy of the model w ith ACO-FA is high, which shows that the pr oposed model is highly efficient that it could be used for faster conver gence and low err or r ate.
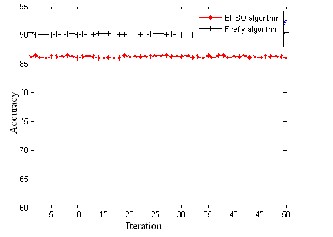
Fig 3: Comparison of models in terms of err or r ate and accur acy for br east cancer .
IJSER © 2012 http :// www.ijser.org
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 7
ISS N 2229-5518
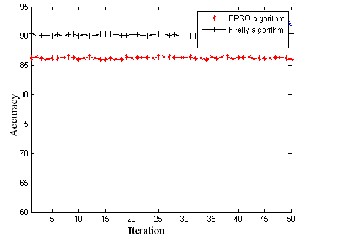
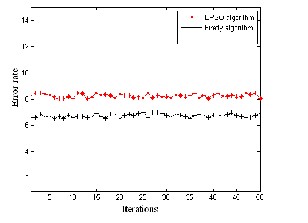
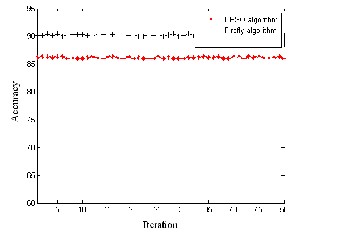
Fig 5: Comparison of models in terms of err or r ate and accur acy for liver cancer .
5.0 CONCLUSION
Fig 4: Comparison of models in terms of err or r ate and accur acy for lymphoma cancer .
A new for ecasting model based on neural tr ee r epr esentation by ACO and its par ameter s optimization by FA was proposed in this paper . A combined appr oach of ACO and FA encoded in the neur al tr ee was developed. It should be noted that ther e ar e other tr ee-str uctur e based evolutionary algor ithms and parameter optimization algor ithms that could be employed to accomplish same task but this pr oposed model yields feasibility and effectiveness .This pr oposed new model helps to find optimal solutions at a faster conver gence. EPSO conver gence is slow er to low error , while FA conver gence is faster to low err or . Fir efly Algor ithm (FA) and Exponential Particle Swarm Optimization (EPSO) w er e analyzed, implemented and compar ed. Results have shown that the Fir efly Algor ithm (FA) is super ior to EPSO in ter ms of both efficiency and success. This implies that the combined approach of ACO-FA is potentially mor e pow er ful than the other algor ithms, which leads to the pr oper level of conver gence to the optimum. The Pr oposed method incr eases the possibility to find the optimal s olutions as it decr eases with the err or rate.
REFERENCES
[1] E. Elb eltag, T. Hegazy and D. Gr ier sona, ‚Modified Shuffled Fr og- Leaping Optimisation Algorithm: Applications to Pr oj ect Management‛, Structure and Infrastructure Enginee ring , vol. 3, no. 1, 2007, pp. 53 – 60.
[2] E. Emad, H. Tar ek, and G. Donald, ‚Comparison among
Five
Evolutionary-based Optimisation Algor ithms‛, Advanced
Engineering Informatics, vol.19, 2005, pp. 43-53.
[3] X.S. Yang, ‚A Discr ete Fir efly Meta -heur istic with Local
Sear ch for Make span Minimisation in Permutation
IJSER © 2012 http :// www.ijser.org
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 8
ISS N 2229-5518
Flow Shop Scheduling Pr oblems‛, International Journal of Industrial Engineering Computations, vol. 1, 2010, pp. 1–10.
[4] X.S. Yang, ‚Fir efly Algor ithms for Multimodal Optimisation‛,Stochastic Algor ithms: Foundations and Applications, SAGA 2009,Lectur e Notes in Computer Sciences, vol. 5792, 2009, pp. 169-178.
[5] S. Lukasik and S. Zak, ‚Fir efly Algor ithm for Continuous Constrained Optimisation Tasks‛, Systems Resear ch Institute, Polish Academy of Sciences, 2010, pp. 1–10.
[6] D.T. Pham, A. Ghanbar zadeh, E. Koc, S. Otr i, S. Rahim and M.Zaidi, ‚The Bees Algorithm. Technical Note‛. ManufacturingEngineer ing Centr e, Cardiff University, UK, 2005.
[7] D.T. Pham, Ghanbar zadeh A., Koc E., Otr i S., Rahim S., and M.Zaidi, ‚The Bees Algorithm - A Novel Tool for Complex Optimisation Pr oblems", Pr oceedings of IPROMS 2006 Confer ence,
2006, pp. 454-461.
[8] K.S. Lee and Z.W . Geem, ‚A New Meta -heuristic
Algorithm for
Continues Engineer ing Optimisation: Harmony Sear ch
Theory and
Practice‛, Comput: Meth. Appl. Mech. Eng., vol. 194,
2004, pp.3902–3933.
[9] P. Muller and D.R. Insua, "Issues in Bayesian Analysis of
Neur al
Networ k Models", Neural Computation, vol. 10, 1995, pp.
571–592.
[10] M. Dor igo, V. Maniezzo and A. Colorni, ‚Ant System:
Optimisation
by a Colony of Cooperating Agents‛, IEEE Transactions on
Systems,
Man, and Cybernetics Part B, vol. 26, numér o 1, 1996, pp.
29-41.
[11] J.Y. Jeon, J.H. Kim, and K. Koh ‚Experimental
Evolutionary
Pr ogramming-based High-pr ecision Contr ol,‛ IEEE Control Sys.
Tech., vol. 17, 1997, pp. 66-74.
[12] R. Stor n, ‚System Design by Constr aint Adaptation and
Differ ential
Evolution", IEEE Tr ans. on Evolutionary Computation, vol. 3, no. 1,
1999, pp. 22-34.
[13] M. Cler c, and J. Kennedy, ‚The Particle Swarm- Explosion, Stability,
and Conver gence in a Multidimensional Complex
Space‛, IEEE
Transactions on Evolutionar y Computation, vol. 6, 2002, pp.58-73.
[14] Lokketangen, A. K. Jor nsten and S. Stor oy ‚Tab u Sear ch
within a
Pivot and Complement Framew or k‛, International
Transactions in
Operations Research, vol. 1, no. 3, 1994, pp. 305-316.
[15] V. Granville, M. Kr ivanek and J.P. Rasson, ‚Simulated
Annealing: a
Pr oof of Conver gence‛, Patter n Analysis and Machine
Intelligence,
IEEE Transactions, vol. 16, Issue 6, 1994, pp. 652 – 656.
[16] N.Chai-ead,P.Aungkulanon,and P.Luangpaib oon,‛Bees and Firefly Algorithms For Noisy Non-Linear Optimization Problems‛IMECS 2011,Vol II,Mar ch16-18,2011,HongKong.
[17] Ar uchamy Raj ini, Dr . (Mr s)Vasantha Kalayani
David,‛AComparative Performance Study on Hybrid Swarm
Model for Micro a rray Data‛, International Jour nal of
Computer Applications(0975-8887) , Vol 30 No.6, Sept
2011.
[18] Y. Chen, B. Yang, J. Dong, Nonlinear systems modelling via optimal design of neur al tr ees, International Journal of Neural System 14 (2004) 125 –138.
[19] Y. Chen, B. Yang, J. Dong, A. Abraham, Time ser ies for ecasting using flexible neur al tr ee model, Information Sciences 174 (2005) 219–235.
[20] Y. Chen, B. Yang, A. Abraham, Flexible neur al tr ees ensemble for stock index modeling, Neur ocomputing 70 (2007) 697–703.
[21] Y. Chen, F. Chen, J.Y. Yang, Evolving MIMO flexible neural tr ees for nonlinear system identification, in: IC-AI,
2007, pp. 373–377.
[22] Y. Chen, A. Abr aham, B. Yang, ‚Hybrid flexible neural tree based intrus ion detection systems‛, International Journal of Intelligent Systems 22 (4) (2007) 337 –352.
[23] Lizhi Peng,Bo Yang,Lei Zhang,Yuehui Chen,‛A Parallel evolving algorithm for flexible neur al tr ee‛,Parallel Computing 37 (2011),653-666.
[24] Yuehui Chen, Bo Yang and Jiw en Dong, ‚Evolving Flexible Neural Networks using Ant P rogramming and PSO Algorithm‛, Spr inger – Verlag Berlin Heidelber g 2004.
[25] H. Zang, S. Zhang and K. Hapeshi, ‛A Review of Natur e-
Inspir ed Algor ithms‛, Journal of Bionic Engineering, vol. 7,
2010, pp. 232–237
[26] Xin-She Yang, X.S., (2010) ‘Fir efly Algorithm, Stochastic Test Functions and Design Optimisation’, Int. J. Bio- Inspir ed Computation, Vol. 2, No. 2, pp.78-84.
[27] X.-s. Yang,‛Fir efly Algorithm, Levy flights and global optimization‛,in: Resear ch and development in Intelligent Systems XXVI (Eds M. Br amer , R. Ellis, M. Petr idis), Spr inger London, pp.209 -218(2010).
[28] Available on the UW CS ftp server , ftp ft p.cs.w ics.edu, cd math-pr og/cpo-dataset/machine-lear n/WPBC/
IJSER © 2012 http :// www.ijser.org
International Journal of Scientific & Engineering Research, Volmne 3, lsst12 2, February -2012 9
JSSN 2229-5518
IJSER ©2012
http //www 11ser org