International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 256
ISSN 2229-5518
Tuning & Recommended Related Evolution
Approaches for Distributed Databases
1PG Scholar in Computer Science and Engineering, SSJ Engineering College, Vattinagulapally, Gandipet,
Hyderabad 500 075.
2Principal & Professor, Department of Computer Science and Engineering, SSJ Engineering College, Vattinagulapally, Gandipet, Hyderabad 500 075.
3Associate Professor & Head, Department of Computer Science and Engineering, SSJ Engineering College, Vattinagulapally, Gandipet, Hyderabad 500 075.
ABSTRACT---Today’s databases are complex databases with duplicates. Due to complexity database we introduce the tuning and recommendation techniques. Tuning and recommendation process is important task in data integration task. Different existing system techniques like record matching, record linkage detects the same entities in single database. De- duplication removes the duplicates in single database. These techniques are completely related data cleaning mechanisms. These techniques are not gives the significant accuracy results.
In this paper we discuss related to distributed databases duplicates detection and improve the quality of databases. In
Distributed databases apply the new techniques like tuning. Tuning completely related to multiple levels of classification with different rules. In each and every level possible to improve the accuracy. Every level we show some variance of improvement in implementation. These tuning techniques are detecting the all types of duplicates as a speed up format and quality features achieve by tuning mechanism. Here we show comparison in between of single database and multiple databases performance with
classification.
—————————— ——————————
analysis. Detection of duplicates here we spend
In information retrieval duplicate detection major important role in search engine development and Digital libraries. In different online stores maintains the same data with slight modifications. In extraction time we find out the some problems related performance and quality and cost issues. Much number of businesses, government agencies collects the different kinds of huge amount of data. Huge amount of data processing purpose many number of researchers are introduces many number of techniques for efficient solutions. This is one of the good attractive areas. Different organizations are interested to improve the accuracy specification here. Previous many numbers of techniques are available for detection of duplication in extraction data. Those techniques are matching and linkage and duplication.
Using matching and linkage techniques
already we work on same entities detection and remove the duplicates here with data mining
more amount of cost. It’s expensive. The aim of
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 257
ISSN 2229-5518
present paper work using new techniques we
reduces the cost in detection of duplicates. New techniques give the solutions with less amount of cost utilization.
Present techniques start the detection of
duplicates with reusability and integrity part. Every time whenever we start the new process use the existing resources work. Different ways and rules for compile the databases routinely till quality results.
Record duplication is the present growing related research concept in database environment. Many problems are generating under extraction of results from different number of styles. It’s not possible to understand all duplicate records of information in database environment. That’s why it may chance to missing of some duplicates information.
After some number of days similarity
function we implement in present environment for detection of duplicates specification. It’s give the inconsistency results in extraction of results. New concept is introduced that is called as a approximate query processing based on edit
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 258
ISSN 2229-5518
distance mechanism. Duplicate detection possible
within the limited distance specification process.
Some people start the research work in machine learning techniques. Some existing supervised clustering algorithms works as a training phase of work. It’s possible to remove the duplication maximum like 50%. This is called as a semi supervised clustering algorithm. It’s work on single rule classification mechanism.
Probabilistic approaches give the results
as a statistical performance records. Each and every record of duplicate weight once we calculate here. In duplicates weight apply the threshold filter the unique records optimal solution output results. In same duplicate detection environment apply the concept boundary detection environment process. Select the record identifies the duplicate weight, below boundary which
records are present, those records are unique
duplicate in sequential order of all attributes
specification in tree format. All attributes whenever its present sequential its gives the proper format or patterns. In model patterns there is no missing of duplicates content. Different databases follow the different patterns to detection of duplicates. These all patterns are dynamic patterns environment. It’s give the more powerful results in detection of duplicates.
In present duplicates detection mechanisms without training phase directly select the training phase and perform the operation in detection of duplicates. It’s possible to reduce the cost. Deep web search gives the results in different patterns under detection of duplicates. Its show the results with many number of patterns. All patterns results we publish and show the results to users. Users are
different opinions and select any one of the
IJSER
remaining records are duplicates output results.
These techniques are completely related supervised clustering techniques.
The above supervised clustering techniques are not provides results as an effective duplicates detection in implementation. Now some users are introduced unsupervised clustering techniques for duplicate records detection. Now we improve high duplicate ratio with new techniques. It’s follow the number rules in detection of all dimensions of duplicates in implementation. It is the infinite process under detection of duplicates in implementation process.
Last and final ranking techniques display
the based on decision tree approach. These results also display the based on range approach. Compare to above approach it’s provide better results in implementation process. This technique also it’s not providing optimal solution.
Present De-duplication techniques are not gives the accuracy results in duplication of results identification. Now we introduce the new deep web search techniques in detection all duplicates in
implementation process. Now here we search the
pattern. Each and every pattern how numbers of
users are selected we count here. In total number of effective duplicates detection one of the pattern select as a best pattern based on recommendation value.
In Different levels detects the duplicates using tuning phase. Every level apply the classification process and detect the best results output. Every level improves the duplicate results identification process. All levels are remove the different ways duplicates in implementation using learning classifier and Bayesian classifier mechanisms.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 259
ISSN 2229-5518
Present tuning and recommendation model related approaches gives the best results. Its gives the good accuracy in duplicate detection compare to all previous approaches. Normal Generational evolutionary approach gives the status with evidence without any duplicates identification. Generational evolutionary approach sometimes failure in detection of duplicates. Now present tuning we apply till all duplicate detection with good performance. Lastly recommendation models also give the proper solution in detection of duplicates.
1. Optimization Techniques to Record De- duplication, 2012.
2. Evolutionary Tuning for Distributed Database
Performance, 2010.
3. on Evaluation and Training-Set Construction for
Duplicate Detection, 2012.
4. A Language Independent Approach for Detecting
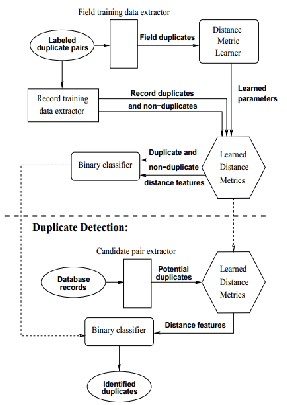
Figure: Proposed system architecture with different
approaches for less training cost
Using distance based environment some type of duplicate we start the detection in database environment. Tuning approach it applies the different times of Bayesian classifier till optimal results identification in output results.
Different facilities related different patterns are available in detection of duplicates. Display the working procedure of each and every pattern. In total number of patterns which pattern works as a best pattern in detection of duplicates that pattern all users are select here. Best pattern gets the high
recommendation environment procedure.
Duplicated Code, 2009.
5. Learning to Combine Trained Distance Metrics for
Duplicate Detection in Databases, 2011.
6. A Genetic Programming Approach to Record De- duplication, 2011.
7. Learning Linkage Rules using Genetic
Programming, 2009.
8. Adaptive Duplicate Detection Using Learnable
String Similarity Measures, 2010.
9. Collection Statistics for Fast Duplicate Document
Detection, 2009.
10. Near-Duplicate Detection by Instance-level
Constrained Clustering, 2008.
IJSER © 2013 http://www.ijser.org