
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 1
ISSN 2229-5518
Training and Analysis of a Neural Network
Model Algorithm
Prof Gouri Patil
—————————— • ——————————
Neural Network algorithm could contain multiple networks, depending on the number of columns used for both input and prediction, or that are used
only for prediction. The number of networks a single min- ing model contains depends on the number of parameters connected by the input columns and predictable columns the mining model uses. Neural network function-ale is a mimic of human neural interconnections and memory. Human brain or memory comprises of an average of about ten billion neurons functioning in a network syn- chronization -- and every single neuron is, on average connected to several other neurons ( may be around a thousand) indirectly or directly to the central neural mass, the brain. By way of these connections and interconnec- tions, nerves send and receive messages as packets of energy called as impulses. One very important feature of human neurons is that they don't react immediately to the reception of energy called impulse. Instead, they sum their received energies, and then, they send their own quantities of energy to the other associated neurons only when this sum reaches a certain critical threshold the neurons trigger and respond back as signals or packets of energy called impulse. Brain learns by adjusting the number and strength of these connections and gives a desired response or output in terms of polarization or re- polarization of neurons and difference in the energy le- vels. Neural networks also work on the same principle as our brains work, they respond to a threshold level of
input signal often calculated as weights in the network
system.
As all inputs and outputs of neural networks are numeric, primary task in designing a neural network is to define a
transfer function wide enough to accept input in any nu- meric range and specific enough to give output in the desired range. The range and limit of inputs should be predefined. Saturation/threshold limit for inputs could then be pre-defined, so that inputs in a way are pro- grammed to give the desired outputs or those inputs or functions incompetent of giving the desired outputs are straight away ruled out in a programmed function-ale network model. Networks are built in a manner that they induce a stepwise logical action called the learning rule. Numeric functional values for the inputs are thus prede- fined and scaled but for some non-numeric nominal val- ues as male or female, yes or no the network functions are divided as different links in the network and graded on an another chain of Numeric functional values as inputs like (0 and 1) and thus branching the network in two si- mulating paths working on the same predefined thre- shold value to decide the final output of the process. The input data for training is the fundamental factor of a neural network, as it gives required information to "dis- cover" the optimal threshold operating point and the re- sult or output of the network. If the output of the network is known and weighed inputs are adjusted to reach the desired output then the network training is called super- vised neural network. When the output is not defined or known, as in the case of sale or stock prediction the net- work is an unsupervised network, which is generally programmed to trigger for all hit value of the input. In case of unsupervised networks for hidden neurons, input values of the network may adjust and interpret differen- tially in different situations and the network ripens or learns based on the adjustments made in the input values of hidden neural layer.
————————————————
Prof Gouri. A.Patil is currently working as a faculty for Bioinformatics with Welingkar Institute of Management, Development and Research, Matunga Mumbai -Central, India, contact-+91 9833025213
IJSER © 2011
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 2
![]()
ISSN 2229-5518
Input
X0 = +1
X
0
X
1
Wo=bk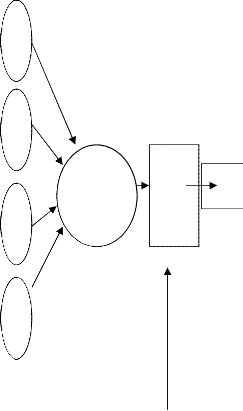

(bias)
W
0
W
1
additional benefit of having an extremely simple derivative function for back propagating errors through the neural network.
Out
Sum- ming
W up juncn
2
2
W X n
n
Ac- tiva- tion Func
-tion
Out put
Out
Out = 1/1+e-Net
Sigmoid function
Net
Input sig- nals
Wei- ghts
Thre shol d
Net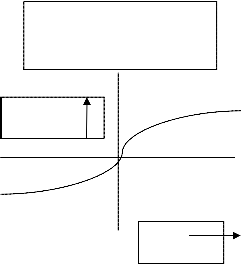
The adjustments made in the input values of the hidden neural layer of an unsurpervised network is nothing but calculations in neural network in terms of adjustments of their weights at the summing up junction and the decisions made at the activation point by defining an activation function value specific for every condition and value. Decisions of the factors include calculations with loops and functions. Initially some time lapse as a function is used to process the data and "winner” input in the time lapse of the model takes all the credit in the first step, where the neuron with the highest value from the calculation fires and takes a value 1, and all other neurons take the value 0.
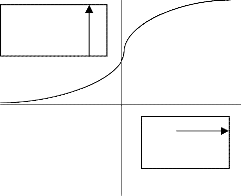
It is advisable that the sigmoid curve is used as a transfer
function because it has the effect of "squashing" the inputs into the range [0,1]. The sigmoid function has the
Out = tanh (Net/2)
tanh function
Typically the weights in a neural network are initially set to small random values; this represents that the net- work knows nothing to begin with. As the training process proceeds, these weights would converge to val- ues allowing them to perform a useful computation. Thus it can be said that the neural network begins with know- ing nothing and moves on to gain admirable real world application.
Activation function is an important function, which de- cides the maturation and output of a neural network. Ac- tivation functions of the hidden values in the neural net- work could introduce non linearity and desired matura-
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 3
ISSN 2229-5518
tion of a neural network otherwise the network would have been just a plain mathematical algorithm without logical application. For feedback or feed forward learning of network, the activation function should be differentia- ble as it helps in most of the learning curves for training a neural network like the bounded sigmoid function , the logistic tanh function with positive and negative values or the Gaussian function. Almost all of these nonlinear activation function conditions assure better numerical conditioning and induced learning.
Networks with threshold limits with out activation func-
tions are difficult to train as they are programmed for
step wise constant rise or fall of weight. Where as a sig-
moid activation functions with threshold limits makes a
small change in the input weight produces change in the output and also makes it possible to predict whether the change in the input weight is good or bad.
In the activation function training, Numerical condition is one of the most fundamental and important concepts of the algorithm, it is very important that the activation function of a network algorithm is a predefined numeric condition. Numerical condition affects the speed and accuracy of most numerical algorithms. Numerical condi- tion is especially important in the study of neural net- works because ill-conditioning is a common cause of slow and inaccurate results from many network algorithms.
Numerical condition is mostly decided based on condi- tion number of the input value, which for a neural net- work is the ratio of the largest and smallest eigenvalues. of the Hessian matrix. The eigenvalues of inputs are the squares of the singular values of the primary input and Hessain matrix is the matrix of second-order partial de- rivatives of the error function with respect to the weights and biases.
body learns to metabolize efficiently with inefficient or week pancreas. Ageing is one of the prime factor for all metabolic disorders and so it goes for diabetes, our pan- creas ages right along with us, and doesn't pump ade- quate levels of insulin as efficiently as it did when we were younger. Also, as our cells age, they become more resistant to insulin (the carrier of glucose for the cells) as well. Modern sedentary lifestyle is damaging our healths and is a prime responsive factor for growing obesity problems." being obese or overweight is one of the prime factors for increasing level of glucose in the blood causing diabetes”. Obesity increases fat cells in the body and fat cells lack insulin or glucose receptors compared to muscle cells, thus increasing fat in the cells is an indirect call to diabetes, exercising and reducing fat in the cells can act as an alert to stay away from this disorder. Eating less of fat and enough fibre and complex carbohydrates compared to simple carbohydrates could contribute to reduce the risk of diabetes. A survey research on 20 individuals for risk to diabetes was conducted using only 4 non-clinical parameters. A supervised network was built and trained to give an output equivalent to associated risk to diabetis with a predefined threshold limit to reach safe non di- abetic level with maximum iterations possible at the acti- vation function to reach the out put, which of course was not fixed but was predefined to reach to zero risk to di- abetes.
Sample data collected
Type 2 diabetes, is a non-neonatal kind of diabetes that develops in the later stages of life due varied reasons, is far more severe and chronic than type 1 or neonatal di- abetis in its destructive metabolic effects on the body. An associated gland called pancreas in our body synthesis
hormone called insulin required to metabolize, break-
down and capture glucose for every cell of the body to synthesize energy in the form of energy rich molecule
called ATP (Adenosine tri- phosphate). Metabolism of
glucose is an indispensable process for the body as this metabolism generates energy for the cell at micro and body at the macro level. There are varied factors response for the onset of this metabolic disorder called diabetes, control of some of these factors could induce synthesis of insulin in correct amount and at required times so that
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 4
ISSN 2229-5518
Predefined Weights for data
Out put = Threshold limit and risk to diabetes
Actiavtion function and Iterations to reach the final out- put from Summing up Junction
Condi- tion No | Maximum Threshold limit | Risk to Diabetis |
1 | 5 | No risk |
2 | 6 | Minimum rirk |
3 | 7 or more | Acute risk |
Network training and summing up Junction
This is a very simple prototype of a network, where every layer of inputs leads to an output. There is no secondary training and learning or firing rule developed in this net- work, however every network begin with as simple learn-
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 5
ISSN 2229-5518
ing single neuron like this and mature to most neural and complex forms. As neural links in the network increases complexity in training and analyzing the network also increases, at the latest with improper links, training and analysis most networks often fails. The next section dis- cusses the common causes for failure of maturing net- works and ways to combat these issues with defining open/flexible activation function along with threshold limits to fire an output.
1. Low coefficient of variation (standard deviation divided by the mean) of input variables causes great difference in the numeric functions. Such an issue probably could be minimized by sub- tracting the mean of each input variable from the variable.
2. If the variances among input variables increase measurably, problem can be cured by dividing each input variable by its standard deviation.
3. High correlations among input variables. This problem could be cured by ortho-normalizing the input variables using Gram-Schmidt, SVD, principal components. The orthogonal compo- nents in this case should be standardized before taking as input value. Single orthogonal compo- nents which fail standardization should be re- moved from the network as they cannot trained or accepted in the network. Training them in the long process mail cause network failure.
4. If some hidden training units in the network be- comes unavoidable and in the long run, the net- work may become saturated with many hidden units. This issue could be handled by using weight decay or similar regularization methods on the input-to-hidden weights, at the risk of less accuracy in learning discontinuities or steep areas of the target function.
5. Low coefficient of variation for activation values of a hidden unit.-this problem can often be ame- liorated by using a hidden unit activation func- tion also with an output range of (-1,1), such as tanh, instead of (0,1) as in the logistic function.
Pvt Ltd, ISBN-13 978-81-315-0395-9W.-K. Chen, Li- near Networks and Systems.
[2] Ill-Conditioning in Neural Networks, Warren S.
Sarle, SAS Institute Inc., Cary, NC, USA Sep 5,
1999Copyright 1999 by Warren S. Sarle, Cary, NC,
USA
[3] The Machine Learning Dictionary for COMP9414
[4] Analytics Consulting, Prasanna Parthasarathy, Man-
agement Journal Bharathidasan Institute of Manage-
ment, Trichy , 324-327
[5] Comparison of Artificial Neural Network and Logis-
tic Regression Models for Prediction of Mortality in
Head Trauma Based on Initial Clinical Data, Bio-Med
Central Feb 2005
[6] R. Roy.. - Furuhashi And Homann, Soft Computing
and Industry Recent Applications, ,CiteSeer.IST Sein-
tific Digital Literature Library
[7] Genetic Programming in Data Mining for Drug Dis- covery - Langdon, Barrett (2004) CiteSeer.IST Seintif- ic Digital Literature Library
[8] Making Indefinite Kernel Learning Practical - Miers- wa (2006) (Correct)
[9] Evolutionary Learning with Kernels: A Generic Solu- tion for Large.. - Mierswa (2006) CiteSeer.IST Seintif- ic Digital Literature Library
[10] Combining Decision Trees and Neural Networks for Drug.. - Langdon, Barrett, etal. (2002) CiteSeer.IST Seintific Digital Literature Library
[11] Diversity in Neural Network Ensembles - Gavin
Brown To (2003)
[12] Linear Equality Constraints and Homomorphous
Mappings in PSO - Christopher Monson CiteSeer.IST
Seintific Digital Literature Library
6 REFERENCES
[1] Neural Network design, Martin T Hagan, Howard B Demuth, Mark Beale, 1996 Cengage Learning India
IJSER © 2011 http://www.ijser.org