The probability density function of the each individual
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 1
ISSN 2229-5518
Text Independent Speaker Identification In a Distant Talking Multi-microphone Environment Using Generalized Gaussian Mixture Model
P. Soundarya Mala, Dr. V. Sailaja, Shuaib Akram
Abstract -- In speaker Identification System, the goal is to determine which one of the groups of an unknown voice which best matches with one of the input voices. The field of speaker identification has recently seen significant advancement, but improvements have tended on near field speech, ignoring the more realistic setting of far field instrumented speakers. In this paper, we use far field speech recorded with multi microphones for speaker identification. For this we develop the model for each speaker’s speech. In developing the model, it is customary to consider that the voice of the individual speaker is characterized with Generalized Gaussian model. The model parameters are estimated using EM algorithm. Speaker identification is carried by maximizing the likelihood function of the individual speakers. The efficiency of the proposed model is studied through accuracy measure with experimentation of 25 speaker’s database. This model performs much better than the existing earlier algorithms in Speaker Identification.
Keywords-- Generalized Gaussian model, EM Algorithm, and Mel Frequency Cepstral Coefficients.
—————————— • ——————————
peaker recognition is the process of recognizing who is speaking on the basis of information extracted from the speech signal. It has been number of applications such as verification of control access permission to corporate database search and voice mail, government lawful intercepts or forensics applications, government corrections, financial services, telecom & call centers, health care, transportation, security, distance
learning, entertainment & consumer etc [2].
The growing need for automation in complex work environments and increased need for voice operated services in many commercial areas have motivated for recent efforts in reducing laboratory speech processing algorithms to practice. While many existing systems for speaker identification have demonstrated good performance and achieve high classification accuracy
*Ms P.Soundarya mala Completed M.tech in Digital Electronics and Communication Engineering in GIET in Jawaharlal Nehru Technological University,Kakinada,INDIA in 2010,PH:9493493302. Email:soundarya_palivela@yahoo.co.in
*Dr V.Sailaja received Ph.d degree in Speech Processing from Andhra
University in 2010, INDIA,PH:9491444434,
Email:sailajagiet@gmail.com
*Mr Shuaib Akram studying IV B.Tech in Electronics and Communication Engineering, Jawaharlal Nehru Technological University , Kakinada,INDIA,PH:9703976497, Email:shuaib.akram@yahoo.com
when close talking microphones are used. In adverse distant-talking environments, however the performance is significantly degraded due to a variety of factors such as the distance between the speaker and microphone, the location of the microphone or the noise source, the direction of the speaker and the quality of the microphone. To deal with these problems micro phone arrays based speaker recognizers have been successfully applied to improve the identification accuracy through speech enhancement [3][4][6].
In speaker identification since there is no identity claim, the system identifies the most likely speaker of the test speech signal. Speaker identification can be further classified into closed-set identification and open-set identification. Speaker identification can be further classified into closed-set identification and open-set identification. The task of identifying a speaker who is known a priori to be a member of the set of N enrolled speakers is known as closed-set speaker Identification. The limitation of this system is that the test speech signal from an unknown speaker will be identified to be one among the N enrolled speakers. Thus there is a risk of false identification. Therefore, closed set mode should be employed in applications where it is surely to be used always by the set of enrolled speakers. On the other hand, speaker identification system which is able to
identify the speaker who may be from outside the set of
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 2
ISSN 2229-5518
N enrolled speakers is known as open-set speaker identification. In this case, first the closed-set speaker identification system identifies the speaker closest to the test speech data. The speaker identification system is divided into text independent speaker identification and text dependent speaker identification. Among these two, Text Independent Speaker Identification is more complicated in open test.
Given different speech inputs X1,X2,……, Xc simultaneously recorded through C multiple microphones, whoever has pronounced X1,X2,…….Xc among registered speakers S={1,2,…..C} is identified by equation (1). Each speaker is modeled by GGMM Ak.
SA= argmax p(Ak | X1,X2,….Xc).
max p(Ak | X1,X2,….Xc) .P(Ak)
integration method to re-score the hypothesis scores, measure the distance between them and combine them.
2. FINITE MULTIVARIATE GENERALIZED GAUSSIAN MIXTURE SPEAKER MODEL
The Mel frequency cepstral coefficients (MFCC) are used to represent the features for speaker identification. In the set up used, the magnitude spectrum from a short frame is processed using a mel-scale filter bank. The log energy filter outputs are the cosine transformed to produce cepstral coefficients. The process is repeated every frame resulting in a series of feature vectors [1]. We assume that the Mel frequency cepstral coefficients of each are assumed to follow a Finite Multivariate Generalized Gaussian Mixture Distribution. Therefore the entire speech spectra of the each individual speaker can be characterized as a M component Finite multivariate Generalized Gaussian mixture distribution.
The probability density function of the each individual![]()
= arg15.k5.C
(1)
p(X1,X2,……Xc )
speaker speech spectra is
p( x t A) =
ai bi ( x t A) (4)
By using Bayes’s rule equal prior probability (ie.
where,
x t = (xtii ) j=1,2,…,D; i=1,2,3…,M;
P(Ak.)=1/C), and the conditional independency between
different speech inputs X1,X2,….Xc given speaker model
Ap , and not in that p(X1,X2,……..Xc) is the same for all
t=1,2,3,…,T is a D dimensional random vector representing the MFCC vector. A is the parametric set
such A = (µ,Q,I ) ai is the component weight such that
speakers, equation 1 can be simplified as,
i=1
ai = 1
SA= arg15.k5.C Tc=1 p(Xc | Ak) (2)
max C
Taking the logarithm of equation 2, we obtain
bi ( x t A) is the probability density of ith acoustic class
represented by MFCC vectors of the speech data and
the D-dimensional Generalized Gaussian (GG)
distribution (M..Bicego et al (2008)) [5] and is of the form
det( )]-1/2
![]()
µ p [
[z(p)A(p,cr)]D
exp (5)
SA= arg15.k5.C c =1 p(Xc | Ak) (3)
where,z(p) =
r and
max C
![]()
![]()
2 1
![]()
p p
![]()
f(1/p)
The identity of the speaker can be
determined by the sum of hypothesis log likelihood
p cr (6)
f(3/p)
scores obtained from C microphones. In a distance
and llxllp = D
p
|xi |
talking environment, however, the log likelihood score
itself in equation(3) is expected to degraded, ie. Its reliability cannot be ensured. Furthermore, a variety of causes such as the location of the speaker or the noise, the direction of the speaker, and the distance can have a different effect on each microphone. Therefore the identification result obtained from a microphone can be better than the others. In such cases, the simple integration is greatly affected by the incorrect classification of single channel. Thus, we propose a new
i=1 stands for the
lQ norm of vector x, z= is a symmetric positive definite
matrix. The parameter µ i is the mean vector, the function
A (Q) is a scaling factor which allows the var(x) = a2 and
Q is the shape parameter when Q=1, the Generalized
Gaussian corresponds to a laplacian or double exponential Distribution. When Q=2, the Generalized Gaussian corresponds to a Gaussian distribution. In limiting case Q@ + oo Equation (5) Converges to a uniform distribution in (µ--Y3a, µ+-Y3a) and when Q @o +, the distribution becomes a degenerate one when x=µ. The
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 3
ISSN 2229-5518
generalized Gaussian distribution is symmetric with respect to µ,
The variance of the variate xii is
var(X) = crii (7)
The model can have one covariance matrix per a
Generalized Gaussian density of the acoustic class of each speaker. The covariance matrix I can also be a full or diagonal. In this chapter the diagonal covariance matrix is used for speaker model. This choice is based on the initial experimental results. As a result of diagonal covariance matrix for the feature vector, the features are independent and the probability density function of the feature vector is
pij
The proposed Generalized Gaussian Mixture Model in a multi microphone environment are evaluated with a
database uttered by 25 speakers. For each speaker, there are 10 conversational sentences, which are recorded in single session. Each sample is of 2 seconds. Speech samples are recorded by using 8 micro phones. Each of which recorded at centre and diagonal. They were then re-recorded again by playing them back with a loud speaker placed at each position, means 1m, 3m and 5m by using 8 microphones which were placed at different locations. These are used to train GGM and to estimate the distribution of average log likelihood estimation.![]()
ij- ij
exp - A(pij,crij)
D D
![]()
bi (xt|(A) = Ti=1 2
pij
(8)![]()
f 1+ 1 pij
A(pij ,crij)
= Ti=1 fii (xtii )
The model parameters are estimated and initialized by the EM algorithm with k-means [7].
The updated equation for estimating the model parameters are
The updated equation for estimating ai is
As the number of N-best hypotheses per channel (N- best classification results) employed for identification increases, the performance of the proposed method outperform the earlier existing methods.
Table1: Speaker identification accuracy
(l+1)
1 T

ai(l) bi (xt, A(l) )
ai = T
![]()
t=1
a b (x , A )
(9)
M
i=1
i(l) i
t (l)
Where A(l) = (1ii (l) , crii (l) ) are the estimates obtained at
the ith iteration.
The updated equation for estimating µii is
1ii (l+1) =
T
![]()
t=1
ti(xt,A)(l)
A(N,pi)
(xtij
-Jlij)
(10)
T
t=1
t (x ,A(l) A N,pij
Where, A(N, pii ) is some function which must be equal
1
to unity for Qi = 2 and must be equal to
pij-1
![]()
for pi =11, in
the case of N=2, we have also observed that A(N, pii )
must be an increasing function of pii .
The updated equation for estimating crii is
1
N
t=1
ti(xt,A(l) )
3
r
![]()
pij
1
xtij -1ij(l)
1
pij j
![]()
pij
![]()
crii (l+1) =
![]()
p r
pi
(11)
T
t=1
ti(xt,A(l) )
The number of mixture components is initially taken for K – Means algorithm by drawing the histogram of the first Mel frequency cepstral coefficient of the speech
data.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 4
ISSN 2229-5518
The figure represent the identification accuracies of the identification methods, as the number of N- best classification result increases to 25, which corresponds to total number of registered speakers .Table.1 corresponds to the performance of the identification methods in case of N=25. In terms of the base line method (LS), if
we approximate k in Eq (3) to k c N-best hypotheses, it is
possible not to obtain the log likelihood score of the hypothesis from a certain channel depending on the order of hypotheses. Thus we considered only when N is equal to 25. Despite only using 2-best classification results per channel, the proposed method (GGM) is comparable to, or even better than, the baseline methods using all possible hypotheses, which consist of all the registered speakers. And the proposed identification method can achieve its best performance with less than eight best hypotheses per channel. Table 2 shows the average percentage of correct identification for various speaker identification models.
Table 2 Avg. percentage of correct identification vs. speaker identification models.
Speaker Model | % of Accuracy |
LS | 93.0 |
AD | 93.0 |
GGM | 94.0 |
*LS- Least Squared, AD-Adaptive Distribution, GGM- Generalized Gaussian Model
A graph between False Alarm probability and Miss- probability called as DET curve is drawn below. If false alarm probability and Miss-probability are equal, the graph can be approximated as hyperbola.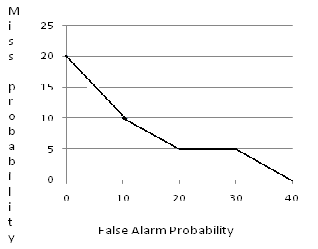
Figure 1: Plot of DET Curves for a speaker identification evaluation.
In this paper we propose Text Independent Speaker Identification model based on Finite Multivariate Generalized Gaussian Mixture Model, to improve identification accuracy in a Multi-microphone environment. In a relatively close-talking environment (1m), Generalized Gaussian model maintain high identification accuracy and they are superior to identification result of the best channel. As the distance between the speaker and microphone increases, the Generalized Gaussian Mixture Model shows more reliable identification performance than other existing models which are given in the table (1). For this, a text independent speaker identification model is developed with the assumption that the feature vector associated with speech spectra of each individual speaker follows a Finite Multivariate Generalized Gaussian Mixture Model. The model parameters are estimated and initialized by using EM algorithms with K-means. An experimentation with 25 speakers speech data revealed that this Text Independent Speaker Identification using Finite Multivariate Generalized Gaussian Mixture Model
outperform the earlier existing Text Independent models.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 5
ISSN 2229-5518
[1] B. Narayana Swamy and R. Gangadharaiah “Extracting Additional Information From GAUSSIAN MIXTURE MODEL PROBABILITIES for improved Text Independent Speaker Identification.” Proc. ICASSP, vol.1, pp.621-624, Philadelphia, USA, March 2005.
[2] D.A.Reynolds, R.C.Rose. E.M. Hofstetter “Integrated Models of signal and background with application to speaker identification in noise” IEEE Trans. On speech and audio Processing, vol 2. No.
2. April 1994.
[3] D.A.Reynolds, R.C.Rose. “Robust Text Independent Speaker Identification using Gaussian Mixture Models” IEEE Trans. On speech and signal Processing, 3(1), January 1995, 72-83.
[4]. I.A. McCowan, J. Pelecanos and S. Sridharan, “Robust speaker recognition using microphone arrays” Proc. Speaker Odyssey, pp.101-106, Crete, Greece, June 2001.
[5] Md M. Bicego, D Gonzalez, E Grosso and Alba Castro (2008) “Generalized Gaussian distribution for sequential Data Classification” IEEE Trans. 978-1-4244-2175-6.
[6] Q. Lin, E. Jan, and J. Flanagan, “Microphone arrays and speaker identification”, IEEE Trans. Speech Audio Process, vol.2,
no.4, pp.622-628, Oct. 1994
[7] Sailaja, K Srinivasa Rao & K V V S Reddy (2010) “Text Independent Speaker identification with Multi Variate Gaussian Mixture Model” International Journal of Information Technology and Knowledge Management July-December 2010, Volume 2, No.
2, pp. 475-480.
IJSER © 2011 http://www.ijser.org