International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 1
ISSN 2229-5518
Significant Role of Search Engine in
Higher Education
Rahul J. Jadhav, Dr. Om Prakash Gupta, Usharani T. Pawar
Abstract- Information explosion has given a rise to quest for more and more knowledge and its applicability to varied fields. Higher education is not exception to this. The facilities, of varied institutions are perpetually involved in teaching, learning, evaluation and research activities. They are using the modern technology to a great extent. Not only the faculty and academicians but students of today’s world also use the latest technology for knowing more and more. Therefore the use of internet has taken rapid stride. For collecting data and information varied programs are developed and the use of search engine prove to be the most significant tool for gathering information and knowledge. Search engine is one of the most widely used method for navigating of cyberspace. The objective of the research paper is to study the significant role of search engine to make the higher education innovative and easily accessible to the students, faculty and researchers.
Keywords: Search engine, Higher education, navigating of cyberspace.
—————————— • ——————————
1. INTRODUCTION
Search Engine: A Capsule Description
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results and are often called hits. The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in databases or open directories. Unlike Web directories, which are maintained by human editors, search engines operate algorithmically or are a mixture of algorithmic and human input.
1.1. What is Search Engine?
A program that searches documents for specified keywords and returns a list of the documents where the keywords were found. Although search engine is really a general class of programs, the term is often used to specifically describe systems like Google, Alta Vista and Excite that enable users to search for documents on the World Wide Web and USENET newsgroups.
Typically, a search engine works by sending out a spider to fetch as many documents as possible. Another program, called an indexer, then reads these
————————————————
Bharati Vidyapeeth Deemed University,Pune Yashwantrao Mohite Institute of Management, Karad. INDIA E-mail rjjmail@rediffmail.com
Bharati Vidyapeeth Deemed University,Pune Yashwantrao Mohite Institute of Management, Karad. INDIA
Shivaji University, Kolhapur Department of computer science S.G.M College
, Karad. INDIA E-mail usharanipawar@rediffmail.com
documents and creates an index based on the words contained in each document. Each search engine uses a proprietary algorithm to create its indices such that, ideally, only meaningful results are returned for each query.
1.2. History of Search Engine
"How could the world beat a path to your door when the path was uncharted, uncatalogued, and could be discovered only serendipitously?" — Paul Gilster, Digital Literacy.
History of Search Engine can be said as started in A.D.
1990. The very first tool used for searching on the Internet was Archie (The name stands for "archives" without the "v", not the kid from the comics). It was created in 1990 by Alan Emtage, a student at McGill University in Montreal. The Archie Database was made up of the file directories from hundreds of systems. When you searched this Archie Database on the basis of a file’s name, Archie could tell you which directory paths on which systems hold a copy of the file you want. Archie did not index the contents of these sites. This Archie Software, periodically reached out to all known openly available ftp sites, list their files, and build a searchable index. The commands to search Archie were UNIX commands, and it took some knowledge of UNIX to use it to its full capability.
Two other programs, "Veronica" and "Jughead," searched the files stored in Gopher index systems. Veronica (Very Easy Rodent-Oriented Net-
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 2
ISSN 2229-5518
wide Index to Computerized Archives) provided a keyword search of most Gopher menu titles in the entire Gopher listings. Jughead (Jonzy's Universal Gopher Hierarchy Excavation And Display) was a tool for obtaining menu information from various Gopher servers.
In 1993, MIT student Matthew Gray created what is considered the first robot, called World Wide Web Wanderer. It was initially used for counting Web servers to measure the size of the Web. The Wanderer ran monthly from 1993 to 1995. Later, it was used to obtain URLs, forming the first database of Web sites called Wandex.
In 1993, Martijn Koster created ALIWEB (Archie-Like Indexing of the Web). ALIWEB allowed users to submit their own pages to be indexed. According to Koster, "ALIWEB was a search engine based on automated meta-data collection, for the Web."
1.3. How Search Engine Works?
A search engine operates, in the following order

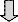
Web crawling Indexing Searching
Web search engines work by storing information about many web pages, which they retrieve from the html itself. These pages are retrieved by a Web crawler (sometimes also known as a spider) — an automated Web browser which follows every link on the site. Exclusions can be made by the use of robots.txt. The contents of each page are then analyzed to determine how it should be indexed (for example, words are extracted from the titles, headings, or special fields called Meta tags). Data about web pages are stored in an index database for use in later queries. A query can be a single word. The purpose of an index is to allow information to be found as quickly as possible. Some search engines, such as Google, store all or part of the source page (referred to as a cache) as well as information about the web pages, whereas others, such as AltaVista, store every word of every page they find. This cached page always holds the actual search text since it is the one that was actually indexed, so it can be very useful when the content of the current page has
been updated and the search terms are no longer in it.
This problem might be considered to be a mild form of linkrot, and Google's handling of it increases usability by satisfying user expectations that the search terms will be on the returned webpage. This satisfies the principle of least astonishment since the user normally expects the search terms to be on the returned pages. Increased search relevance makes these cached pages very useful, even beyond the fact that they may contain data that may no longer be available elsewhere.
When a user enters a query into a search engine (typically by using key words), the engine examines its index and provides a listing of best- matching web pages according to its criteria, usually with a short summary containing the document's title and sometimes parts of the text. The index is built from the information stored with the data and the method by which the information is indexed. Unfortunately, there are currently no known public search engines that allow documents to be searched by date. Most search engines support the use of the Boolean operators AND, OR and NOT to further specify the search query. Boolean operators are for literal searches that allow the user to refine and extend the terms of the search. The engine looks for the words or phrases exactly as entered. Some search engines provide an advanced feature called proximity search which allows users to define the distance between keywords. There is also concept-based searching where the research involves using statistical analysis on pages containing the words or phrases you search for. As well, natural language queries allow the user to type a question in the same form one would ask it to a human. A site like this would be ask.com.
2. Importance of Search Engine
The usefulness of a search engine depends on the relevance of the result set it gives back. While there may be millions of web pages that include a particular word or phrase, some pages may be more relevant, popular, or authoritative than others. Most search engines employ methods to rank the results to provide the "best" results first. How a search engine decides which pages are the best matches, and what order the results should be shown in, varies widely from one engine to another.
In cyberspace, there's no place to "turn." I have only my computer screen in front of me. Somehow, I need to find a place to purchase the book I want.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 3
ISSN 2229-5518
There's no street on my screen so I can't drive around on the Web (I could "surf," but that's hit and miss; even then I still need to know where to start). Sometimes it's obvious: type in the name of the bookstore, add a
.COM and it's a pretty good bet you're going to end up where you want to go. But what if it's a specialty bookstore and doesn't have a Web site with an obvious URL?
One solution to this problem is the search engine. In fact, it's probably one of the most widely used methods for navigating in cyberspace. Considering the amount of information that's available from a good search engine, it's similar to having the Yellow Pages, a guide book and a road map all-in-one.
3. Occasionally, they find a site by hearing about it from a friend or reading in an article.
Thus it’s obvious that the most popular way to find a site is search engine.
Table 1.1 Top Ten Search Engines
Search engines can provide much more information than just the URL of a Web site. Typing in "books" into the Google search engine returns about
9,270,000 results. If we refine the search to "books, Internet", we end up with about 6,070,000 results. If we know the book's author, let's say E.Balguruswamy books , search engines now returns About 80,500 results within 0.18 seconds (of course, these results will change from day to day).For many people, using search engines has become routine. Are the Search Engines are
important? Undoubtedly, positively, absolutely....YES! Here's
how important they are. In the recent Georgia Tech Internet User Survey, respondents were asked how they find pages on the Internet. A full 82% said they used the major search engines.
It is the search engines that finally bring your website to the notice of the prospective customers. When a topic is typed for search, nearly instantly, the search engine will sift through the millions of pages it has indexed about and present you with ones that match your topic. The searched matches are also ranked, so that the most relevant ones come first.

Top Ten Search Engines
70
60
50
40
30
20
10
0
Sea rch Engine
Series1
It is the Keywords that play an important role than any expensive online or offline advertising of your website. It is found by surveys that a when customers want to find a website for information or to buy a product or service, they find their site in one of the following ways:
1.The first option is they find their site through a search engine.

2. Secondly they find their site by clicking on a link from another website or page that relates to the topic in which they are interested.
As you can see from the statistics, Google absolutely
dominates the search engine market. Its closest competitor is Yahoo.com but they seem to be endlessly buying old search technologies that do not provide any innovative techniques. This bodes well for Google’s continued dominion.
4. Role of Search Engine in Higher
Education
To conduct an effective search, the researcher must understand the structure of the various search engines. Search engines do not always provide the right
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 4
ISSN 2229-5518
information, but rather often subject the user to a deluge of disjointed irrelevant data.
All search engines support single-word queries. The user simply types in a keyword and presses the search button. Most engines also support multiple-word queries. However, the engines differ as to whether and to what extent they support Boolean operators (such as "and" and "or") and the level of detail supported in the query. More specific queries will enhance the relevance of the user's results.
4.1. Variations on the Search Engine
A search engine is not the same as a "subject directory." A subject directory does not visit the web, at least not by using the programmed, automated tools of a search engine. Websites must be submitted to a staff of trained individuals entrusted with the task of reviewing, classifying, and ranking the sites. Content has been screened for quality, and the sites have been categorized and organized so as to provide the user with the most logical access. Their advantage is that they typically yield a smaller, but more focused, set of results.

Table 2 Search result.
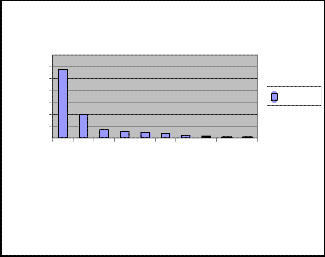
almost 4 hours a day online (see table 1.3) and the majority of that time is spent at work (see table1.4)
Table 3 Daily Time spent online
Daily Time spent online | Percent |
< 1 hour | 10.4 |
1-2 hours | 24.8 |
2-3 hours | 33.1 |
3+ hours | 31.1 |
Table 4 Work VS Personal Internet Use by the
Respondents
Work VS Personal Internet Use By The Respondents | Percent |
0% personal/ 100%work | 7.8 |
50% personal/ 50%work | 68.6 |
75% personal/ 25%work | 21.2 |
100% personal/ 0%work | 2.4 |
Respondents were asked the first place they would go online to learn more about the product or service they were considering. Search was the clear winner over manufacturer’s sites and information portals, with 66.3 % of respondents. (see Table 1.5).
Table 5 first place to find out educational information
Where would be the first place you would go online to find out educational information | Percent |
Search Engine | 66.3 |
Independent Web site | 21.6 |
Educational Portal | 8.3 |
Other | 4.8 |
Above table 1.2 shows, no search engine covers the entire web. There are technical obstacles such as the inability to index frames, image maps, or dynamically created websites
4.2. Importance of Search in higher education
There can be no downplaying the importance of search in higher education. Search continues to be the number one method for finding relevant information online. Respondents indicated that they spend an average of
With the majority of respondents indicating that search plays a major role in their education, we next asked which engine they would use to launch their search. We fully expected Google to be the winner, but we were surprised by how much they dominated their competition (Table 1.6). An amazing 90.9% chose Google as their engine of choice.

Table 6 Search engine chosen by the Respondents
Search engine chosen by the Percent
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 4, April-2011 5
ISSN 2229-5518
Respondents | |
Google | 90.9 |
Yahoo | 4.7 |
MSN | 4.3 |
AltaVista | 0.3 |
Lycos | 0.2 |
5. Conclusion
Table 7 Conclusion
6. References
This study revealed information that will be key to formulating effective search in higher education. This study also reveled that majority of the respondents search for information on general search engines like Google, yahoo. Google is overwhelming the search engine. Percentage of respondents who search for information relevant to their objective is very low.
[1] Craig Lerner. The importance of search engine. Uber Articles
March 2, 2010
[2] Broder, A. Taxonomy of web search, SIGIR Forum, vol. 36,pp. 3-
10, 2002.
[3] Web search engine - Wikipedia, the free encyclopedia
[4] Are SearchEnginesImportant?Searchengineposition.com
[5] How Do Web Search Engines Work – webopedia 02-17-2006
[6] LevelTen_Colin The role of Search Engine Optimization in
Internet Marketing http://www.articlesbase.com/
[7] The Role of Search in B2B Buying Decisions White paper - Enquiro Search Solutions
[8] Lee Underwood A Brief History of Search Engines
[9] Brooks, N. 2004. The Atlas Rank Report II: How searchengine rank impacts conversions. Atlas Institute, 2004.
[10] Finkelstein, L., Gabrilovich, E., Matias, Y., Rivlin, E., Solan,Z., Wolfman G., and Ruppin, E. Placing search in context: the concept revisited. Proceedings of the WWW Conference, 2001.
[11] Greenspan, R. Searching for balance. vol. 2004: ClickZ stats.
[12] R. Villa, M. Chalmers, “A framework for implicitly trackingdata”, Proceedings of the Second DELOS Network of ExcellenceWorkshop on Personalisation and Recommender Systems inDigital Libraries, Dublin City University, Ireland, June 2001.
[13] iProspect Inc. Search engine user attitudes, 2005.
[14] Jansen, B., and Spink, A. The effect on click-through ofcombining sponsored and non-sponsored search engine
results in a single listing, Proceedings of the 2007 Workshop
on Sponsored Search Auctions, WWW Conference, 2007.
IJSER © 2011 http://www.ijser.org