International Journal of Scientific & Engineering Research, Volume 6, Issue 1, January-2015 540
ISSN 2229-5518
Performance analysis of isolated Bangla speech recognition system using Hidden Markov Model.
MD. Abdullah-al-MAMUN, Firoz Mahmud
Abstract— here we present a model of isolated speech recognition (ISR) system for Bangla character set and analysis the performance of that recognizer model. In this isolated Bangla speech recognition is implemented by the combining MFCC as feature extraction for the
input audio file and used Hidden Markov Model (HMM) for training & recognition due to HMMs uncomplicated and effective framework for
modeling time-varying sequence of spectral feature vector. A series of experiments have been performed with 10-talkers (5 male and 5
female) by 56 Bangla characters (include, Bangla vowel, Bangla consonant, Bangla digits) with different conditions. So, it this proposal achieved 85.714% efficiency for isolated Bangla speech recognition system.
Index Terms— Hidden Markov Model, Isolated recognizer, Bangla speech, MFCC, Viterbi algorithm, Baum-Welch algorithm, Forward- Backward algorithm.
1. Introduction:
—————————— ——————————
Speech Recognition is one of the most dynamic areas of today’s Informatics. Speech Recognition could be helpful in many different areas of everyday life [1] – including command and control, dictation, transcription of recorded speech, searching audio documents and interactive spoken dialogues [2] . Speech recognition system also include voice user interfaces such as voice dialing, call routing, domotic appliance control, search, simple data entry, preparation of structured documents, speech-to-text processing, and aircraft [3].
In Computer Science, Speech recognition is the translation
of spoken words into text. The term voice/speech
recognition [4] refers to finding the identity of "who" is speaking, rather than what they are saying. Speech recognition system also known as Automatic Speech Recognition (ASR) or Speech to Text (STT). Speech recognition can be divided into two types: one is isolated speech recognition and other is continuous speech recognition.
An isolated-word system operates on single words at a time
- requiring a pause between saying each word. This is the
simplest form of recognition to perform because the end
points are easier to find and the pronunciation of a word tends not affect others. Thus, because the occurrences of words are more consistent they are easier to recognize. But a continuous speech system operates on speech in which words are connected together, i.e. not separated by pauses [5].
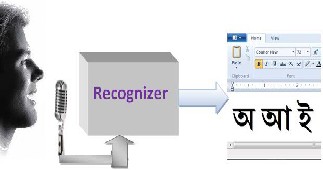
Figure 1: Isolated Bangla speech recognition system.
There are number of recognizer are available for English, French, Spanish, Arabic and so on. But there are lacks of efficient process are absence for Bangla. So, in this paper we want to discuss the process of isolated Bangla speech recognition system. In this isolated speech recognition system is involved: Voice recording, feature extraction, and recognition and training with the help of a model. The most successful modeling approach for the recognition and training process of isolated speech recognition (ISR) is to use a set of hidden Markov models (HMMs).
HMM is doubly stochastic process with an underlying
stochastic process that is not observable, but can only be
observed through another set of stochastic processes that produce sequence of observed symbols [6].
The technique of HMM has been broadly accepted in today’s modern state of- the art ASR systems mainly for two reasons: its capability to model the non-linear dependencies of each speech unit on the adjacent units and a powerful set of analytical approaches provided for estimating model parameters [7] [8].
Now following we want to discuss the process the isolated
speech recognition system with help of the Hidden Markov
Model (HMM).
IJSER © 2015 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 6, Issue 1, January-2015 541
ISSN 2229-5518
2. Model of speech recognizer:
Automatic Speech Recognition (ASR) is technology that allows a computer to identify the words that a person speaks into a microphone or telephone. In this system involves various steps is just like following:
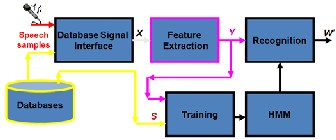
Figure 2: Block diagram of speech recognizer model.
2.1 Voice Recording: To recognizes the speech, at first
input the speech as audio file by voice recording. That’s audio is feed into the recognizer to give the word as output.
2.2 Feature Extraction: From the input speaker voice audio files produced the feature vector by the feature extraction method which is to strip unnecessary information from the input data and convert the properties of the signal that simplifies the distinction of the classes. The feature vector sequences are used to training and testing utterances are the inputs of the classification step of a speaker recognition system.
2.3 Database Design: A speech database is a collection of recorded speech accessible on a computer and supported with the necessary transcriptions. This database collects the observations required for parameter estimations. In this isolated recognizer system we use 56 Bangla characters which include Bangla vowel set, Bangla consonant set and Bangla digits.
2.4 Training: Training is most important matter for any recognizer. To training this recognizer we use Hidden Markov Model. Building HMM speech models based on the correspondence between the observation sequences and the state sequence which known as training. This is the same training procedure of a baby.
2.5 Recognition: Recognition returns the final output
word from the given input speech. All the possible
sequences of words W are tested to find the W* which is the best matches from the training database file.
3. Feature Extraction:
When the input data to an algorithm is too large to be processed and it is suspected to be notoriously redundant then the input data will be transformed into a reduced representation set of features (also named features vector). Transforming the input data into the set of features is called feature extraction [9]. There are several feature extraction methods are exists, such as, Linear Prediction
Coding (LPC), Mel-Frequency Cepstrum Coefficients (MFCC), Perceptual Linear Predictive Coefficients (PLP) and so on.
3.1 Mel-Frequency Cepstrum Coefficients (MFCC):
Here feature extraction method is implemented by the Mel- Frequency Cepstrum Coefficients (MFCC). Mel-frequency cepstral coefficients (MFCCs) are coefficients that collectively make up an MFC where MFC (mel-frequency cepstrum) is a representation of the short-term power spectrum of a sound for audio processing. Here, cepstral means "spectrum-of-a-spectrum". The MFCCs are the amplitudes of the resulting spectrum.
To established MFCC process, at first cuts the digitized
speech signal, that values are overlapping windows of
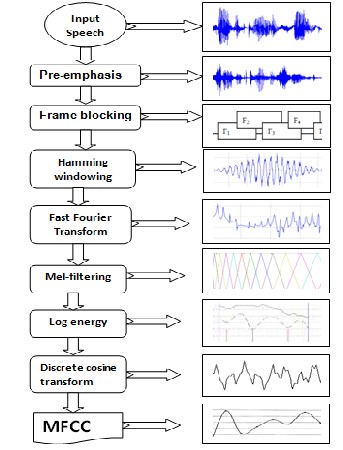
equal length. The cut-out portions of that speech signal are called "frames", they are extracted out of the original signal every 10 or 20 ms. The length of each frame is about 30 ms. Each frame in the time domain is transformed to a MFCC vector, where each vector representing cepstral properties of the speech signal within the corresponding window. The feature vector sequences O=( O1 , O2 … OT ) of training and test utterances are the inputs of the classification step of a speech recognition system [11].
Figure 3: Steps for Mel-Frequency Cepstrum Coefficients
(MFCC)
IJSER © 2015 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 6, Issue 1, January-2015 542
ISSN 2229-5518
4. Hidden Markov Model:
bj (k) ≥0, 1≤ j ≤ N , 1≤ k ≤ M and ∑𝑴
𝐛 (k)=1, 1 ≤ j
Hidden Markov Models (HMMs) provide an efficient ≤ N
𝒌=𝟏 Rj
framework for modeling time-varying spectral vector sequences. HMMs lay at the heart of virtually all modern speech recognition systems and although the basic framework has not changed significantly in the last decade or more, the detailed modeling techniques developed within this framework have evolved to a state of considerable sophistication. As significance, automatic speech recognition systems (ASR) are based on HMMs.
After feature extraction by MFCC, The input signal is split into frames of equal length. For each frame Ft ¸t =1/T , a cepstral vector Ot is calculated that is a Q-dimensional feature vector Ot=(Ot(i), i=1/Q). Thus, the input speech signal is represented by its time sequence O=( O1 , O 2 … O T ) of cepstral vectors. In practice, Q is chosen in the range of
20/40 [10, 12]. We generally assume that the input speech is
already split into isolated words, or respective syllables, or other phonetic-lexical units, e.g. the “allophones” from [13], which cepstral representation O is to be given to a HMM for recognition.
The sequence of cepstral vectors Ot =(O1 ,O2 , ….. OT ) that
feeds into the HMM as input and the conditional probability P(O|M) is the HMM output. Here M is the training degree of HMM with respect to O.
• The initial state distribution, 𝝅 = {𝝅R i } where, πi
= p{q1 = i}, 1≤ i ≤N
4.1 Three basic problems of HMM:
(1) Evaluation, or computing P(Observations | Model). This allows us to find out how well a model matches a given observation sequence.
(2) Decoding, or finding the hidden state sequence which is
the best corresponds to the observed symbols is that the model is maximizes P(Path | Observations, Model).
(3) Training, or finding the model parameter values λ=( Π,
A, B) that specify a model most likely to produce a given sequence of training data.
4.2 Probability Evaluation:
Given a model λ=( Π, A, B) and observations sequence O1 , O2 … OT and P{O|λ} can be determine by the following forward and backward probability.
Now to calculate the forward variable α t (i) as the probability of the partial observation sequence O1 , O2 … OT in the current state can be mathematically define by the following
αt (i) = P{ O1 , O 2 … OT , qt = i|λ} ……………………………(1)
Then recursive relationship to calculate αt+1 (j) are following.
αt+1 (j) = bj (O t+1 ) ∑𝑵
𝛂 (i) α
, 1 ≤ j ≤ N , 1 ≤ t ≤ T-1
𝒊=𝟏 R t ij
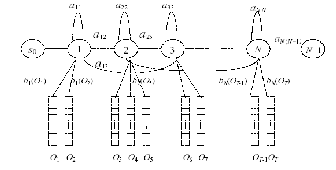
Figure 4: diagrammatic representation of a HMM
…………………………………………………………….(2)
Where, α1 (j) = πjb j (o1 ) , 1 ≤ j ≤ N
By the equation no. (1.2) we can calculate αT(i) , 1 ≤ i ≤ N
So the desired probability is given by,
P{O|λ} = ∑𝑵 𝟏 𝛂
𝒊=
R T(i) …………………………………….…..(3)
The model of HMM is λ=( Π, A, B) which elements are following
• The number of states of the model N.
• The number of observation M.
• A set of state transition probabilities A={aij }.
In a similar way to define the backward variable βt (i) as the
probability in the current state is i is as following-
βt (i) = P{ Ot+1 , Ot+2 … OT , q t = i, λ} ……………………….…(4)
Then recursive relationship to calculate βt (i) are following.
βt+1 (i) = ∑𝑵 𝛃
aij = p{q t+1 =j | qt =i} , 1 ≤ i,j≤ N where, q t denotes the current state. Transition probabilities should satisfy the normal stochastic constraints, a ij ≥0, 1≤
R t+1 (j) α ij b j (Ot+1 ) , 1 ≤ i ≤ N , 1 ≤ t ≤ T-1
……………………………………………………….……….(5)
Where, βT (i)=1, 1≤ i ≤ N
Further we can calculate is following,
i, j ≤ N and ∑𝑵
𝐚 ij=1, 1 ≤ i ≤ N
αt (i) βt (i) = P {O, qt = i|λ} 1 ≤ i ≤ N , 1 ≤ t ≤ T
𝒋=𝟏 R
• A probability distribution in each of the states,
B={bj (k)}.
bj (k)=p{ot =vk | qt =j}, 1 ≤ j ≤ N , 1 ≤ k ≤ M where
………………………………………………………………….(6)
So another way to calculate P{O|λ}by using both forward and backward variables as follows
Vk denotes the kth observation symbol in the
P{O|λ} = ∑𝑵
𝐏 {O, qt = i|λ } = ∑𝑵 𝛂
(i) β (i)
𝒊=𝟏
𝒊=𝟏 R t t
alphabet, and Ot the current parameter vector.
Following stochastic constraints must be satisfied.
……………………………………………………………….…………………………...(7)
IJSER © 2015 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 6, Issue 1, January-2015 543
ISSN 2229-5518
4.2 Decoding (finding the best path):
We have a model λ=( Π, A, B) and observations sequence O1 , O2 … OT , and we need to determine P{O|λ} but problem is to determine most likely state sequence. To solve this problem we can use Viterbi algorithm that can return whole state sequence with the maximum likelihood. In order to computation we define an auxiliary variable,
γ t (i)=P{qt = i|O, λ} …………………………………….…..(11) In forward and backward variables this can be expressed by,
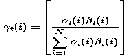 …………………………………. (12) Now establish a relationship between γt (i) and ξt (i,j) by the equation (10) & (12) is given by,
…………………………………. (12) Now establish a relationship between γt (i) and ξt (i,j) by the equation (10) & (12) is given by,
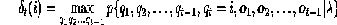
γ t (i) = ∑𝑵 𝜺
(i,j) 1≤ i ≤ N , 1≤ t ≤ M
By this calculation we can have the highest probability that partial observation sequence and state sequence up to t=t when the current state is i. It is easy to observe that the following recursive relationship holds.
𝒋=𝟏 R t
…………………………………………………………….…(13)
For a given model λ=( Π, A, B) the Baum-Welch learning process can be describe by the following way, where parameters of the HMM is updated in such a way to maximize P{O| λ}.
At first, calculate the 'α's and 'β's using the recursions
equations (5) and (2),
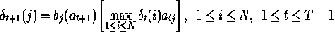
αt+1 (j) = b j(O t+1 )∑𝑵
𝛂 (i) α
, 1 ≤ j ≤ N , 1 ≤ t ≤ T-1 and
…………………………………………………………….. (8)
βt+1 (i) =∑𝑵 𝛃
𝒊=𝟏 Rt ij
where, δ1 (j) = πj b j (o1 ), 1 ≤ j ≤ N
So the procedure to find the most likely state sequence
starts from calculation of δΤ (j), 1 ≤ j ≤ N using recursion in
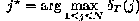
(1.8). Finally the state j* is as follows
𝒋=𝟏 Rt+1 (j) αij b j (Ot+1 ) , 1 ≤ i ≤ N , 1 ≤ t ≤ T-1
Then calculate the ‘ξ's and 'γ's using equations no. (10) and
(13)
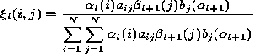 And γ t (i) =
And γ t (i) =
∑𝑵
𝜺 (i,j) 1≤ i ≤ N , 1≤ t ≤ M
4.3 The Learning Problem:
The learning problem is how to adjust the HMM parameters where, the strings which are output by the machine or observed from the machine are given, is called the training set. And each output sequence can be the result of more than one state sequence generate by the training algorithm of the hidden markov model. The forward and backward algorithm both are used for the training of the hidden markov model. So the training algorithm is known as forward and backward algorithm or more famously known as Baum Welch algorithm.
To describe the Baum-Welch algorithm we need to define two
more auxiliary variables, one is forward variable and other
is backward variables.
First forward variables is defined in state i at t=t and state j
at t=t+1 is following,
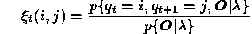
………………………………………………………………. (9) Using forward and backward variables this can be expressed as,
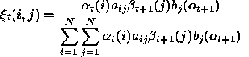
…………………………………………….……………….. (10) Next the backward variable probability in state i at t=t is given by
𝒋=𝟏 R t
Next step is to update the HMM parameters by the
following equations.
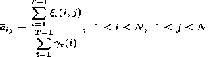
Πi = γt (i) 1 ≤ i ≤ N …………………………………..……..(14)
………………………………………………….………….. (15)
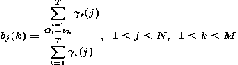
……………………………………………………………… (16) Above equations are known as re-estimation formulas is used for learning problem of an HMM.
4.4 Isolated recognition by HMM:
Isolated recognition in means recognition of speech based on any kind of isolated speech unit. In a simple isolated speech recognition task contains N speech units,
In isolated speech recognition process two tasks are associated with its; namely the training and recognition.
4.4.1: Training
The training of the hidden markov model is unsupervised learning. For a given HMM parameters λ i 1≤ i ≤ N the sequence of observation vectors O= {O 1 , O2 … ON }. The training procedure can be describe is as following-
IJSER © 2015 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 6, Issue 1, January-2015 544
ISSN 2229-5518
(1) Initialize the each HMM, λ i = (Αi , Bi , πi ) 1≤ i ≤ N with randomly value.
(2) Take an sequence of observation and calculate is as follows
a) Calculate the forward and backward probabilities for each HMM, using the equation (5) and (2).
b) The likelihoods can be calculated by the following
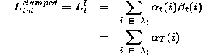
equations
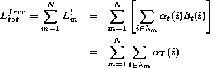
……………………………………………(17)
…………………………………………… (18)
c) For each model calculate the gradients parameters
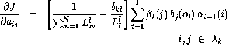
for each model is following-
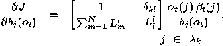
……………………………………………(19)
…………………………………………… (20)
d) Update parameters by the equation
Ɵnew=Ɵold - η� δJ �
5. Experimental Result:
The experiment of proposal isolated Bangla speech recognition was applied on the following 56 Bangla character set. So in the training period we are only use following character set.
Table 1: Training character set for using this experiment.
Character Type | Character Set |
Vowel | অ আ ই ঈ উ ঊ ঋ এ ঐ ও ঔ |
Consonant | ক খ গ ঘ ঙ চ ছ জ ঝ ঞ ট ঠ ড ঢ ণ ত থ দ ধ ন প ফ ব ভ ম য র ল শ ষ স হ ড় ঢ় য় |
Digits | ০ ১ ২ ৩ ৪ ৫ ৬ ৭ ৮ ৯ |
According to the character set from table-1, we was designed the training database which description is shown in table-2 just following.
Table 2: Training database description.

𝛿Ɵ
R Ɵ=Ɵold
(3) Go to step (2), unless all the observation sequences are
considered.
(4) Repeat step (2) to (3) until a convergence.
4.4.2 Recognition
Comparative to the training, recognition is much simpler and the procedure is given below.
(1) Initialize the each HMM, λ i = (Αi , Bi , πi ) 1≤ i ≤ N with
randomly value.
(2) Take an sequence of observation to be recognized and
calculated is as following
a) Calculate the forward and backward probabilities for each HMM, using the equation (5) & (2).
b) Calculate the likelihoods, Ll m 1≤ m ≤ N by the
equation (18)
c) The observation sequence for the recognized set l*
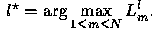
is given by
(3) Go to step (2), unless all the observation sequences are considered to be recognition.
From the set of database, we was performed an experiment with 5 males and 5 females voice for this isolated recognition system. Following table shows the recognition rate for the speakers.
Table 3: Result for isolated speech recognition.
IJSER © 2015 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 6, Issue 1, January-2015 545
ISSN 2229-5518
As, the recognition rate is the ratio between number of correctly recognized speech units and total number of speech units to be recognized. Mathematically,
𝑅𝑐
helps during this work and the review this article with suggestions to improve this script.
Recognition rate R=
𝑅𝑡

x100%
Where, Rc = Correctly recognized speech and Rt = total number of speech units to be recognized.
For example, for Speaker_1:-
Given, Rc = 48 and Rt = 56
48
Reference:
[1] Dimo Dimov and Ivan Azmanov “Experimental specifics of using HMM in isolated word speech recognition (*)” in proc International Conference on Computer Systems and Technologies - CompSysTech’2005

So, R=
56
x100% = 80.35%
[2] “The Application of Hidden Markov Models in Speech
Same as, for the Speaker_2, Speaker_3, Speaker_4……
Recognition rate is 85.71%, 75.00%, 83.93% ....... respectively.
So, Total recognition rate for 10 speaker
Recognition” Mark Gales1 and Steve Young2
[3] http://en.wikipedia.org/wiki/Speech_recognition
[4] ^ "British English definition of voice recognition". Macmillan
Publishers Limited. Retrieved February 21, 2012.
[5] http://www.speech.cs.cmu.edu/comp.speech/Section6/Q6.1.html
[6] Bhupinder Singh, Neha Kapur, Puneet Kaur “Speech Recognition

∑10
= 𝑛=1
𝑅𝑒𝑐𝑜𝑔𝑛𝑖𝑡𝑖𝑜𝑛 𝑅𝑎𝑡𝑒 𝑓𝑜𝑟 𝑆𝑝𝑟𝑎𝑘𝑒𝑟 𝑛
𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑠𝑝𝑒𝑎𝑘𝑒𝑟
= 85.714%
with Hidden Markov Model: A Review” in proc Volume 2, Issue
3, March 2012 ISSN: 2277 128X pp(400-403)
[7] Picone, J. (1990), “Continues Speech Recognitionusing Hidden Markov
Models”, IEEE ASSP Magazine, Vol. 7, Issue 3, pp. 26-41.
6. CONCLUSION & DISCUSSIONS:
Generally it is really difficult to gain 100% accuracy of a speech recognition system. For example, an English recognizer Dragon is most familiar and most popular recognizer all over the world, its accuracy is not fully 100%. Because some criteria is associated with any speech recognizer system, such as training is most important matter. Training of the recognizer will provide an even better experience. By train more and more your recognizer system efficiency will be increases. This training system of a recognizer is just like a baby. Also, you should avoided poor quality microphone consider using a better microphone to get better result from the recognizer. Noise of the environment is one of the large obstacles to get better result from the recognizer.
In this paper, we try to present an isolated Bangla
recognizer system with help of the Hidden Markov Model (HMM) due to its effective framework. According to this process an experiment was done isolated data that means
56 Bangla character set (i.e. Bangla vowel, consonant and digits). In this isolated recognition process is done with 5 males and 5 females voice in different environment or conditions. So from the experimental result we had seen that 85.714% achievement for isolated speech recognition system by the Hidden Markov Model approach. And this experimental result is below 100% due to some real life problem, such as, using poor microphone, noise of the environment, poor utterance of a speaker.
7. ACKNOWLEDGEMENTS
I would like to thank Lecturer Firoz Mahmud, department of computer science & Engineering (CSE) in Rajshahi University of Engineering & Technology (RUET) for his
[8] Flahert, M.J. and Sidney, T. (1994), “Real Timeimplementation of HMM speech recognition for telecommunication applications”, in proceedings of IEEE International Conference on Acustics, Speech, and Signal Processing, (ICASSP), Vol. 6, pp. 145-148.
[9] http://en.wikipedia.org/wiki/Feature_extraction
[10] Dunn B., Speech Signal Processing and Speech Recognition, Current Topics in DSP, Speech Proc.2, RBD, May 13, 2003, 34p.,
[11] S. M. Design of an Automatic Speaker Recognition System Using
MFCC, Vector Quantization and LBG Algorithm {IJCSE11-03-
08-115.pdf}
[12] Wu Y., A. Ganapathiraju, and J. Picone, Baum -Welch reestimation of Hidden Markov Models, Report of Inst. for Signal and Information Processing, June 15, 1999, Mississippi State Univ., MI, US, (http://ieeexplore.ieee.org/iel5/5/698/00018626.pdf).
[13] Totkov G. A., Conceptual and Computer Modelling of Language Structures and Processes (with Applications for the Bulgarian Language), D.Sc. dissertation, Spec. #01-01-12 “Informatics”, Univ. of Plovdiv, 2004, (by resume in Bulgarian, 57p.).
IJSER © 2015 http://www.ijser.org