International Journal of Scientific & Engineering Research Volume 2, Issue 7, July-2011 1
ISSN 2229-5518
Modified Prime Number Based Partition
Algorithm
Mr. Praveen Kumar Mudgal, Prof. Ms. Shweta Modi
Abstract— Frequent pattern mining is always an interesting research area in data mining to mine several hidden and previously unknown pattern. The better algorithms are always introduced and become the topic of interest. Association rule mining is an implication of the form X implies Y, where X is a set of antecedent items and Y is the consequent items. There are several techniques have been introduced in data mining to discover frequent item sets. This paper describes and takes an approach for mining frequent pattern and suggests some modifica- tion. The new algorithm uses both the concepts of top-down and bottom-up approach.To calculate the support count prime representation of item sets is used .It enables to save time in calculating frequent item sets. Through this Efficiency of system improves when the frequent item sets are generating in lesser time.
Index Terms—Association Rule Mning,Cluster Based Partition Algorithm,Data mining,Frequent patterns,KDD,Support Count,Prime num- bers.
—————————— • ——————————
he method of association rule mining was given by R. Agrawal in 1993.It can show the association of vari- ous products by generating frequent item sets. The
data mining requires, need to store wide variety of data to be stored in memory for future processing .It takes sever- al years to accomplish this large storage. Because the size of data is maintained and processed basically captures more then tera bytes of space in memory. This kind of large volume of data may originate from business enter- prises and scientific research. Data mining is the process of extracting interesting and undetected patterns from large storage after their processing. Data mining is a one step of the process known as Knowledge Discovery in Database; through this process relative and previously unknown and needful information can be extracted. For extracting such kind of important information data fil- tered through KDD process of data mining. This data helps in decision support, market analysis, deciding mar- ket policies, weather forecasting, medical diagnosis and many other applications.
Problem is based on the market basket problem. One can state the problem as follows: Let A= {a,b,c,…………,y,z} be the set of m different literals. Transaction database T is a collection of transaction. Each transaction contains a set of items {a,b,………….,y,z} is a subset of T.
Generally an association rules mining algorithm contains
————————————————
• Ms.Sweta Modi is currently HOD of masters degree program Computer
Science in SRIT college ,India, E-mail: modi_shweta84@yahoo.com
the following steps:
• The set of candidate k-item sets is generated by 1-
extensions of the large (k -1) - Item sets generated in the
previous iteration.
• Supports for the candidate k-item sets are generated by
a pass over the database.
•Item sets that do not have the minimum support are
discarded and the remaining item sets are called large k-
item sets.
This process is repeated until no
larger items sets are found.There are some algorithms
which are used for mining frequent item set-
1) Apriori algorithm.
2) Partition algorithm
3) Pincer search algorithm
And many more algorithms are described after
these three.
This algorithm uses the concept of prime numbers to represent the items in the transaction. Each item is assigned a unique prime number. Each transaction is collection of items, so transaction is represented by prime product of uniquely assigned prime number of each item. Since the product of prime number is unique and modulo division of prime multiple of transaction by prime multiple of each item set can check the presence of item set in the transac- tion. Each division generates either remainder-
• If remainder = 0, item set is present in the trans- action.
• If remainder <> 0, item set is present in the transaction.
The advantage of using prime
number is presence of each item set can be calculated
very quickly. Prime numbers representation method ge-
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 7, July-2011 2
ISSN 2229-5518
nerates only one number for one transaction.Each number is very easily operatable and storable in memory.Each number requires less processing time to calculate support count because each item set is unique.
Table 1: Sample Database
transaction with item set {2, 4}’s prime multiple 21 gives remainder zero then it is counted as one support.This process can also be applied for calculating support of each item set.The time required for calculating the sup- port count of each item set is same, because it requires only one single division operation.
Table 3: Prime multiple of each transaction
In this algorithm each item is as- signed a unique prime number.That takes part in calculat- ing support count of each item sets. As shown is table 2.
Table 2: Equivalent Prime Assignments
Table 4: Calculating support count of item set {2, 4}
3.2 Prime multiple representations
Reason to adopt Prime numbers in our new approach is to perform fast calculation for calculating support count of each item sets. The support count is calculated using modulo division operation between transactions prime product and items prime product. If the If the remainder is zero, it indicates that the item is in the transaction. If the remainder is non-zero, it indicates that the item is not present in the transaction. The support count of item set
{2, 4} can be found by performing the modulo division of each transaction’s prime product by the product ‘21’ of item 2’s corresponding prime number ‘3’ and item 4’s corresponding prime number ‘7’ as shown in table 3. Next table 3 shows the prime multiple of each transaction.
Now it is the right time to calculate support count of item set {2, 4}. The support count of item set is found to be ‘3’.If modulo division operation of each
For calculating the support count two possibilities are as follows:
1) The support count for item set is greater than or equal to the minimal support count.
2) The support count for item set is less than the
minimal support count.
For each possibility the two solutions are given below correspondingly:
1) It is maximal frequent item set and procedure end.
2) The subset of length equal to n=p/2 is generated and their support is calculated.
This again leads to the following possibilities.
1) If the support count of the set of size N is greater
than the minimal support count, all possible super-
sets of size N+N/2 are generated.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 7, July-2011 3
ISSN 2229-5518
2) If the support count is less than the minimal sup- port count, the subsets of length equal to n/2 is generated.
This process ends when maximal frequent item set is found.
3.3 Previous algorithm:
The algorithm is divided in to two parts the first part which is the main algorithm which invokes the sub algo- rithm. The main algorithm creates equal partitions of transaction database and assigns each partition to sub algorithm. It then takes each partition and generates fre- quent item set.
1. Find the infrequent item sets of length 1 and store them in IF 1
2. Remove the infrequent 1-items as denoted by IF1 in all transactions.
3. Assign separate Prime Number Pj to each unique item
ITj for n-items.
4. Represent the item sets in Prime Number Representa- tion form as follows:
(a) Replace each Transaction’s item ITj by Corresponding
Prime Number Pj.
(b) Represent each Transaction Tj of Size m by the mul- tiple Mj of all the prime number representation Pj of the items in the transaction (P1 x P2 x P3 x…….xPm) and store them in shared memory.
5. Find the size Maxlength of maximal size transaction in
Database and put it in shared memory.
Lopfinal=false
6. For each node j in the cluster
Divide the transactions equally based on the number of
nodes and assign to j-th Node.
Connect to j-th node’s server program to initiate process.
End loop
7. for each node j in the cluster
Wait until result comes from j-th node
Combine the result from j-th node into finalresultset.
End loop.
1. Wait until master initiates process.
2. Read Transactions Tj from shared memory.
3. Read Prime number multiple Mj of Transactions from shared memory.
4. Read the size Maxlength of Maximal size transaction from shared memory.
SG=empty Where SG is the subset group
FrequentItemset = empty
Start = 1
End = Maxlength
j = Maxlength
Exitflg = 0
5. Do While Exitflg = 0
For each transaction Tj with size >= j do
For each itemset S of Transaction Tj with size j
Do
If S is not in SG AND if IF1’s items are not a subset of S
then
Find the Support count of itemset S
Mj mod K and counting its presence using the remainder
and store it in SUPPORT
If SUPPORT >= minsupport then Add S to FrequentItem-
set
End If
Add S to SG; End If
End loop End loop Clear the SG
If FrequentItemset is not empty
Start = j
j = Round ((Start + End)/2)
If j = End then
Send all Item set AllFrequentItemset to master
Exitflg = 1
Exit the Do loop
End if
Find the infrequent items in infrequent j-size
Item sets and add them to IF1
Add FrequentItemset to AllFrequentItemset
Clear the FrequentItemset
Else
End= j
j = Round (Start + End) /2
If j= Start -1 then
Send all Item set AllFrequentItemset to master Exit the Do
loop.
End if
End if
Lopfinal=true
End Do loop
3.4 Modified Prime Number Based Partition Algo- rithm:
The new modified algorithm has suggested two modifica- tions in this paper which works very efficiently. In the first modification sub algorithm select the records of size
=j from the transaction database, at the same time it select the item set of size=j to generate the support count of the each item set. After the observation it is founded that number of transactions are very less as compared to sup- port count, so there is no need to generate the support count this time, so time can be reduced this time. Another modification is that since we can generate multiple parti- tions of the data base after the each partition, frequent item set can be removed from further processing.
3.4.1 Steps of Algorithm for Master:
1. Find the infrequent itemsets of length 1 and store them in IF 1
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 7, July-2011 4
ISSN 2229-5518
2. Remove the infrequent 1-items as denoted by IF1 in all transactions.
3. Assign separate Prime Number Pj to each unique item
ITj for n-items.
4. Represent the itemsets in Prime Number Representa- tion form as follows:
(a) Replace each Transaction’s item ITj by Corresponding
Prime Number Pj.
(b) Represent each Transaction Tj of Size m by the mul- tiple Mj of all the prime number representation Pj of the items in the transaction (P1 x P2 x P3 x…….xPm) and store them in shared memory.
5. Find the size Maxlength of maximal size transaction in
Database and put it in shared memory.
Lopfinal=false
6. For each node j in the cluster
Divide the transactions equally based on the number of
nodes and assign to j-th Node.
Connect to j-th node’s server program to initiate process.
End loop
7. for each node j in the cluster
Wait until result comes from j-th node
Combine the result from j-th node into finalresultset.
Lopfinal=true
End loop.
3.4.2 Steps of Sub Algorithm:
1. Wait until master initiates process.
2. Read Transactions Tj from shared memory.
3. Read Prime number multiple Mj of Transactions from shared memory.
4. Read the size Maxlength of Maximal size transaction from shared memory.
SG=empty Where SG is the subset group
FrequentItemset = empty
Start = 1
End = Maxlength
j = Maxlength
Exitflg = 0
5. Do While Exitflg = 0
For each transaction Tj with size >= j do
For each itemset S of Transaction Tj with size j
Do
If S is not in SG AND if IF1’s items are not a subset of S
then
Find the Support count of itemset S
Mj mod K and counting its presence using the remainder
and store it in SUPPORT
If SUPPORT >= minsupport then Add S to FrequentItem- set
End If
Add S to SG;
End If End loop End loop Clear the SG Label 5:
If FrequentItemset is not empty
Start = j
j = Round ((Start + End)/2)
If j = End then
Send all Itemset AllFrequentItemset to master
Exitflg = 1
Exit the Do loop
End if
Find the infrequent items in infrequent j-size
Itemsets and add them to IF1
Add FrequentItemset to AllFrequentItemset
Clear the FrequentItemset
Else
End= j
j = Round (Start + End) /2
If j= Start -1 then
Send all Itemset AllFrequentItemset to master Exit the Do loop.
End if
End if
End Do loop
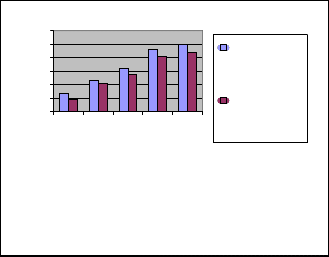
For the comparative study of previous algorithm and modified algorithm, we have taken a database of 1000 transaction of 13 items. In this analytical process we con- sidered 1000 transactions to generate the frequent pattern with the support count 25% .We have repeated the same process by increasing the transaction, after the experiment on both approach, we have designed a graph and sum- marized a result in the following table 5.
Table 5: Recorded time with different parameters
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 2, Issue 7, July-2011 5
ISSN 2229-5518
120
100
80
60
40
20
0
cluster Based partition algorithm
Modified Prime Number Based algorithm
ACM SIGMOD International Conference on Management of Data, Washington D.C. , May 1993, pp. 207-216.
[9] M. Houtsma and A. Swami, Set Oriented Mining for Association Rules in RelationalDatabases. In Proceedings of 11th IEEE Interna- tional Conference on Data Engineering, 1995, pp : 25-33.
[10] Rakesh Agrawal and R. Srikant . Fast Algorithm for Mining Association Rules in Large Databases, Proceedings of the 20th Inter- national Conference on Very Large Databases, Santigo, Chile, 1994, pp 487-499.
[11] Akhilesh Tiwari, Rajendra K. Gupta, and Dev Prakash Agrawal Cluster Based Partition Approach for Mining Frequent Itemsets IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.6, June 2009.
[12]Dr.S.N.Sivanandam , Dr.S.Sumathi , Ms.T. Hamsapriya,
Fig 1. Performance evalution of Cluster Based Parti-
tion Algorithm and Modified Prime Number Based
Algorithm.
Mr.K.Babu Parallel Buddy Prima – A Hybrid Parallel Frequent item- set mining algorithm for very large databases,Academic open inter- net journal.
In this paper, new algorithm for mining frequent item sets using prime number based partition approach was proposed. The concept of using prime number improves the performance of algorithm in terms of memory and time complexity. The pruning step in first scan reduces the size of transaction in memory besides the problem ofdiscovering association rules mining we have looked in to include the enhancement of data base capability.
We wish to thank Mr. Manish Tiwari for his insightful comments and suggestions.
[1] Arun K Pujari. Data Mining Techniques (Edition 5): Hyderabad, India: Universities Press (India) Private Limited, 2003.
[2] Margatet H. Dunham. Data Mining, Introductory and Advanced
Topics: Upper Saddle River, New Jersey: Pearson Education Inc.,
2003.
[3] Jiawei Han. Data Mining, concepts and Techniques: San Francis- co, CA: Morgan Kaufmann Publishers.,2004.
[4] R.K. Gupta. Development of Algorithms for New Association
Rule Mining System, Ph.D. Thesis, Submitted to ABV-Indian Insti- tute of information Technology & Management, Gwalior, India,
2004.
[5] A. T. Bjorvand. Object Mining: A Practical Application of Data Mining for the Construction and Maintenance of Software Compo- nents. Proceedings of the Second European Symposium, PKDD-98, Nantes, France, 1998, pp :121-129.
[6] Akhilesh Tiwari, R. K. Gupta, D.P. Agrawal, Mining Frequent Itemsets Using Prime Number Based Approach. In Proc. 3rd Interna- tional Conference on Advanced Computing and Communication Technologies (ICACCT), India, November 08-09,2008, pp: 138-141.
[7] M. Houtsma and A. Swami. Set Oriented Mining for Association
Rules in Relational Databases. In Proceedings of 11th International conference on Data Engineering, 1995, pp 25-33.
[8] Agarwal R., Imielinski T., and Swami A. Mining associations
between sets of items in massive databases. In Proceedings of the
IJSER © 2011 http://www.ijser.org