Phase-1: Sequential patterns of purchase: sequential rule genera- tion at different time snapshot.
Phase-2: Compare patterns generated at different time snapshot which extracts:
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1354
ISSN 2229-5518
Mining change in customers’ buying behavior on different time snapshot datasets
Niti Desai, Amit Ganatra
Abstract— Customers’ buying behavior is changing because of change in Life style, liking and disliking, priorities of purchase. Such changes have occurred due to demographical changes, technological advancement etc. Earlier, people typically bought TV VCR. The buying pattern is replaced by new technological invention TV DVD. Apart from purchase behavior of customer in terms of item(s), purchase time span has also changed. Earlier purchase period of TVDVD was 6 months to 1 year. This gap is reduced to 3 months - 6 months. This reduction might be because of revised income structure, change in life style, increase purchase power etc. This paper attempted to capture such behavioral changes of customers over time. Real-time Retail dataset capture at different time slot is used to understand changing behavior of customer. Proposed algorithm is working in two phase’s namely sequential rule of purchase and frequent purchase. Frequent item purchase is mine based on Support (frequency of items) and confidence (highly co-related items) of items in huge sequential dataset. Proposed sequential pattern mining algorithm is working on FP- Growth based PrefixSpan for time stamp based sequential dataset. Later phase of proposed framework compare two datasets which are captured at different time. It’s able to evaluate three interesting things of purchase: 1) New patterns captured, 2) Obsolete patterns and 3) Emerging patterns (EPs). Empirical experiment has conducted on real-time sequential dataset ‘retail’. Data has been captured on two different time shot. Various experiment evaluates,
12.33% more purchase sequences are generated by latest dataset. Out of them 13% purchase rules are newly discovered.33% buying patterns are obsolete patterns, which are no longer in existence.
Index Terms— Customers’ buying behavior, Emerging Patterns (EPs), New Patterns, Obsolete Patterns, PrefixSpan, Sequential Pattern
Mining (SPM), Time snapshot sequential dataset
—————————— ——————————
EQUENTIAL patterns have been applied in many domains like retail marketing, fraud detection, understanding of customer, web click analysis and medical research. Plenty
of work has been done on data mining in changing environ- ment [1],[2].Association rule mining is used to find out inter- esting relationship of items from large transaction dataset [3],[4].Incremental updating techniques are proposed for effi- cient maintenance of discovered association rules when new transaction data are added in original transaction dataset. But it does not reflect on changes of association rules[5].Certain patterns are identified whose support are significantly change from one dataset to another dataset, known as ‘Emerging Pat- terns’ (EPs) [6]. There are certain application in which occur- rence of event is equally important known as sequential pat- tern mining (SPM) which can be identified by Apriori and FP- Growth techniques.[1],[7].Apriori based ― GSP[8], SPAM[9], SPADE[10], SPRIT[11] and FP-Growth based Freespan[12] and PrefixSpan[13] are well known SPM techniques. Among those
————————————————
Niti Desai is pursuing Ph.D in Computer Engineering from Uka Tarsada Uni- versity, Bardoli, Surat, Gujarat from 2012. She has 8+ years of teaching experi- ence.Currentlty working as Assistant Professor in computer science and technolo- gy depertment at Usha Mital Institute of Technology – Mumbai.She has publishes and presented 10+ papers in national/international conferences andreputed jour- nals. E-mail: nitiadesai @ gmail. com
Dr. Amit Ganatra is Professor, Head in computer Engineering Department at CSPIT, CHARUSAT and Dean in Faculty of Technology-CHARUSAT, Gujarat (since Jan 2011 to till date). He is a member of Board of Studies (BOS), Faculty Board, Academic Council and Governing Body for CHA- RUSAT and member of BOS for Gujarat Technological University (GTU), KSV and Indus University. He has 15+ years of teaching experience. He is having good research record. He has published and contributed over 90+ papers (as an Author and a Co-author) referred journals and presented in
methods PrefixSpan defeated other SPM methods in context of execution time, memory consumption and pattern generation [13],[14].Current SPM techniques emphasis on such buying patterns which are mostly preferable by customers presently. Customers’ buying behavior is changing over time, it is essen- tial to track such buying priorities of customer. Customers’ changing behavior is captured by association rule mining. Changes of patterns are defied as Emerging Patterns (EPs), Unexpected change in patterns and added/perished rules [15]. Paper focused on how customers’ buying behavior is changing at different time snapshot using sequential pattern mining. Three interesting things of purchase are captured using FP growth based PrefixSpan algorithm. Paper focused on follow- ing interesting analysis of purchase: 1) New purchase patterns
2) Obsolete buying patterns and 3) Change in occurrence of purchase at various time snapshot. Above experiment has been conducted on retail real-time sequential dataset.
FP-Growth based Prefixspan is use to find out frequent se- quences or frequent purchase. Paper tried to focus on change of buying habit of customer as different point in time. So, two datasets are taken which are captured at different time slots for experiment. Sequential patterns based on support thresh- old are used to capture buying behavior of customer. Here, support and confidence threshold values are kept very less. So, the patterns which are suffering of low support values can’t be rejected.
Support: The Support of an item set expresses how often the
various international conferences. E-mail: amitganatra.ce@charusat.ac.inIJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1355
ISSN 2229-5518
item set appears in a single transaction in the database i.e. the support of an item is the percentage of transaction in which that items occurs.
𝐈=𝐏 (𝐗∩𝐘) = (𝐗∩𝐘) / 𝐍 (1)
Range: [0, 1] If I=1 then Most Interesting If I=0 then Least In-
teresting
Confidence: Confidence or strength for an association rule is the ratio of the number of transaction that contain both ante- cedent and consequent to the number of transaction that con- tain only antecedent.
𝐈=𝐏 (𝐘/𝐗) =𝐏 (𝐗∩𝐘)/ 𝐏(𝐗) (2)
Range: [0, 1] If I=1 then Most Interesting If I=0 then Least In-
teresting.
Buying habit of customer is changing over a time. It is neces- sary to capture such buying habit. It is important to under- stand such change. Paper tries to capture emerging trend of buying by changes in frequency. Paper is also able to capture completely new purchase trend and out dated purchase trend. Following notation are used to represent dataset at different time snapshot:
Dt, Dt+k :Dataset at time t and t+k
Rt,Rt+k :Discovered ruleset at time t and t+k
SEQt+ k , SEQt :Discovered set of frequent sequences t+k and t.
ri t, rj t+k :Each rule from corresponding ruleset where i=1,2,3....| Rt | j=1,2,3...| Rt+k |
seq i t, seqj t+k:Each sequences from corresponding sequences where i=1,2,3....|SEQt| and j=1,2,3...|SEQt+k |
A) Emerging Patterns (EPs) [6],[15]
For rule rj t+k following two conditions are met, than we call it the rule of emerging Pattern with respect to ri t
1. Conditional and consequent parts are same between r it and r j t+k
2. Supports of two rules are significantly different.
C) Obsolete Patterns
There are several patterns which are detected only in historical dataset but should not present in dataset captured at later time span. Obs_SEQ is set of patterns contain such patterns which are not detected in later dataset.
Obs_SEQt = SEQt − SEQt+k (6)
∀seqi t ∈ Obs_SEQt and ∀seqi t ∉ SEQt+k where i={1,2..n},
Obs_SEQt ⊂ SEQt
[Note: (A) is partially novel but (B) and (c) are absolutely novel idea of authors]
D) Representation of Sequence Dataset
Data-sequence A is represented as <(a1 , t1 ), (a2 , t2 ), …,(an , tn )>, where (aj , tj ) means that item aj is purchased at time tj where, 1
≤ j ≤ n, and tj -1 ≤ tj for 2 ≤ j ≤ n. In the data-sequence, if items occur at the same time, they are ordered alphabetically.
Dataset Format (SequenceDatabase.txt)
<1> 1 -1 <2> 1 2 3 -1 <3> 1 2 -1 -2
<1> 1 -1 <2> 1 2 -1 <3> 1 2 -1 <4> 1 3 -1 -2
<1> 1 2 -1 <2> 1 2 -1 -2
<1> 2 -1 <2> 1 3 -1 -2
<1>, <2> ….. - TimeStamp (day at which transaction oc- curred)
-1 - End of Transaction
-2 - End of Sequence
1,2,3 - Actual Items
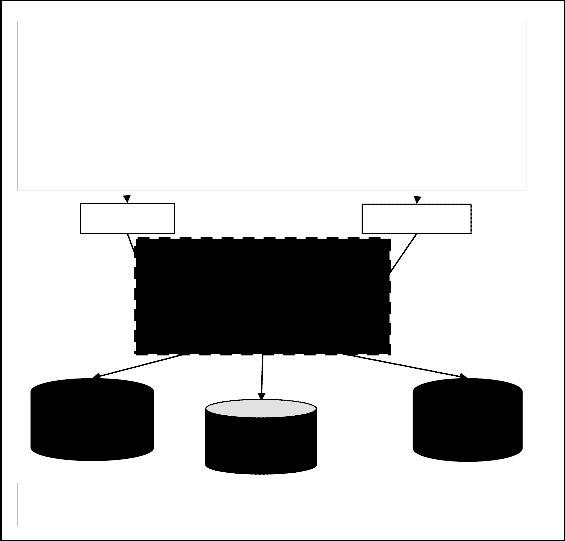
Figure 1 describes system architecture to detect change in cus- tomers’ purchase behavior at different time snapshot. System architecture is divided in two phases namely;
Phase-1: Sequential patterns of purchase: sequential rule genera- tion at different time snapshot.
Phase-2: Compare patterns generated at different time snapshot which extracts:![]()
𝛿 = Support
𝑡+𝑘
(ri)− 𝑆𝑢𝑝𝑝𝑜𝑟𝑡 𝑡(ri)
α𝐷𝐵
(3)
1) Emerging Patterns (EPs)
2) New Patterns
where , α𝐷𝐵 𝑖𝑠 𝑔𝑟𝑜𝑤𝑡ℎ 𝑖𝑛𝑛𝑠𝑖𝑧𝑒−𝑜𝑓𝑛𝑑𝑎𝑡𝑎𝑏𝑎𝑠𝑒 𝑖𝑛 (%)
α𝐷𝐵 =![]()
𝑡+𝑘
𝑛
𝑡 × 100 (4)
3) Obsolete Patterns
Following things can be analyzed from above mentioned
Where, 𝑛𝑡+𝑘 is sequence g𝑡enerated by growth in size of data-
base Dt+k and 𝑛𝑡 is sequence generated by growth in size of
database Dt. Support of any sequence is growing as per
growth of dataset is normal. αDB ≥ 0. If there is no change in database captured at time t and at t+k, then αDB = 0. Expected
growth rate δ, is changed because of change in size of dataset.
If dataset is not changing over time period than δ=0. δ ≤0.2 is
considered as normal growth rate for sequence or rule. Rules
contain δ ≥ 0.2 are considered as Emerging Patterns.
B) New Patterns
There are several patterns which are detected in dataset cap- tured at later time span. These patterns are called as newly generated patterns. New_SEQ is set of patterns contain new patterns which are not detected before.
New_SEQt+k = SEQt+ k − SEQt (5)
∀seqit+k ∈ New_SEQt+k and ∀seqit+k ∉ SEQt where i={1,2..n},
New_SEQt+k ⊂ SEQt+k
phases:
1) New patterns captured, which are not detected earlier.
2) Obsolete patterns are no longer in existence.
3) Change in occurrence of patterns based on its Frequency.
4) Drastic change in frequency of patterns from one dataset to another dataset is used to capture Emerging patterns (EPs).
Input: Dt, Dt+k : Dataset at time t and t+k
Output: (i)New Rules New_Rt+k
(ii)Obsolete Rules Obs_Rt
(iii)Emerging patterns (EPs)
Phase-I
Input: Dt, Dt+k : Dataset at time t and t+k
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1356
ISSN 2229-5518
Procedure: call Seq(Dt , sup)
call Seq(Dt+k , sup)
Output:Rt,Rt+k :Discovered ruleset at time t and t+k
SEQt,SEQt+k :Discovered Complete set of sequences at
time t and t+k
Phase-II
Input: Rt , Rt+k :Discovered ruleset at time t and t+k
SEQt,SEQt+k :Discovered Complete set of sequences at
time t and t+k (Output of Phase-I)
Procedure: Call CompareSeq(SEQt, SEQt+k, sup)
Call EPs(SEQt, SEQt+k )
Output:New Rules New_Rt+k :Discovered rules at time t+k (5)
Obsolete Rules Obs_Rt :Discovered rules at time t (6)
Emerging patterns (EPs) (7)
Procedure: Seq(Dataset D, Support sup)
Step-1: Find length-1 patterns and remove irrelevant sequenc-
es.
i. Scan the sequence database SDB once to count f- support for each itemset.
ii. Identify patterns as length-1 patterns.
iii. Infrequent items are removed and generate pseudo- sequence database.
Step-2: Divide the set of sequential patterns into subsets
i. Without considering constraint C, the complete set of
sequential patterns should be divided into subsets without overlap according to the set of length-1 se- quential patterns (prefix).
Step-3: Construct projected database and mine subsets recur-
sively
i. Construct projected database for each prefix.
ii. Recursively generate projected database for each new prefix and mine it to find local frequent patterns.
Phase-I | ||
Rules set (t) Rules set (t+k)
Phase-II
Compare Rule set capture at time (t) and time(t+k)
Obsolete pat- terns for (t)
Emerging pat- terns (EPs)
New patterns at (t+k)
Fig 1: Architecture to detect change in customers’ purchase behavior at different time snapshot
[Note: block in bold high lights novelty in system frame work]
Step-4: Mine sequential Pattern from Projected database and mine subset recursively.
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1357
ISSN 2229-5518
For each frequent item i append it to prefix to generate new prefix in such a way that
a) i can be assembled to the last element of prefix to form a se-
quential pattern
(iii)Emerging patterns (EPs)
Procedure: EPs(SEQt, SEQt+k ) (refer eq. 7)
or
b) <i> can be appended to prefix to form a sequential pattern.
SEQcommon ← Null
SEQEPs ← Null
SEQcommon = SEQt ∩ SEQt+k
nt+k − nt
Return Complete set of sequential patterns SEQ and Rules Set R
αDB =
![]()
× 100
t
Procedure: CompareSeq(SEQt, SEQt+k, sup)
Obs_SEQt = SEQt − SEQt+k (refer eq.6) New_SEQt+k = SEQt+ k − SEQt (refer eq. 5)
seqi t, seqj t+k :Each sequences from corresponding sequences where i=1,2,3....|SEQt| and j=1,2,3...|SEQt+k |
(Where 𝑛𝑡+𝑘 7T and 𝑛𝑡 7T is total sequences generated at time t+k and t
respectively.)
∀seqi ∈ SEQcommon where i=1,2,3…..| SEQcommon |
For seqi ( i : 1→| SEQcommon | )
![]()
Support𝑡+𝑘 (𝑠𝑒𝑞i) − 𝑆𝑢𝑝𝑝𝑜𝑟𝑡𝑡 (𝑠𝑒𝑞i)
𝛿 =
𝐷𝐵
IF δ > 0.2 then
∀seqit ∈ Obs_SEQt and ∀seqi t ∉ SEQt+k where i={1,2..n}, Obs_SEQt
SEQ
EPs
← SEQ
EPs
∪ { seqi }
⊂ SEQt
∀seqit+k ∈ Obs_SEQt+k and ∀seqit+k ∉ SEQt where i={1,2..n},
New_SEQt+k ⊂ SEQt+k
END
Where,SEQEPs contain all emerging patterns. END IF
Return (i)New Rules New_Rt+k
(ii)Obsolete Rules Obs_Rt
Return SEQEPs
Table 1: Statistical Description
Parameters to evaluate | New Dataset (cap- tured at later time slot) | Old Dataset (captured at earlier time slot) |
Number of sequences | 88162 | 12000 |
Number of distinct items | 16470 | 9004 |
Average number of itemsets per sequence | 10.30575 | 10.00 |
Average number of distinct item per sequence | 10.30575 | 10.00 |
Average number of occurrences in a sequence for each item appearing in a sequence | 1.0 | 1.0 |
Average number of items per itemset | 1.0 | 1.0 |
Algorithm is implemented in Java and tested on an Intel Core Duo Pro- cessor with 2GB main memory under Windows XP operating system.
Duration of data:
The data was obtained from a Belgian retail supermarket
store.
The data are collected over three non-consecutive periods.
First period: starts from half December 1999 to half January
2000.
Second period: 2000 to the beginning of June 2000.
Third period: End of August 2000 to the end of November 2000.
Contain of Data:
The total amount of receipts being collected is 88,163. Data set contains
information about the date of purchase:date, receipt number: receipt_nr,
article number: article_nr, the number of items purchased: amount, the article price in Belgian Francs: price and the customer number: custom- er_nr.5,133 customers have purchased at least one product in the super- market during the data collection period.
Two experiments have been performed on retail real-time da- tasets which are captured at different time period. First exper- iment evaluates: 1) execution time, 2) sequence generation and
3) memory utilization of datasets captured on different time slot. Old and new datasets are 914 KB and 6990 KB respective- ly in size. Table 1 shows statistical description of both datasets. Experiment has been done for 0.1%, 0.08% and 0.05% of sup- port values. Average 12.13% more patterns are generated by dataset captured at later time slot is shown in figure 2. Execu- tion time and memory consumption are increased with incre- ment of size, is shown in figure 3 and figure 4 respectively. Second experiment evaluates and analyzes, change in custom- ers’ buying behavior with respect to different time period. Customers’ buying behavior captured at different time slots
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1358
ISSN 2229-5518
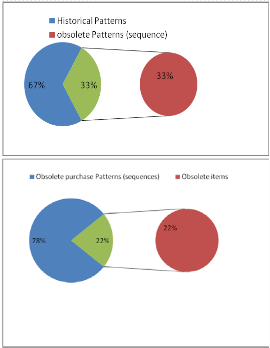
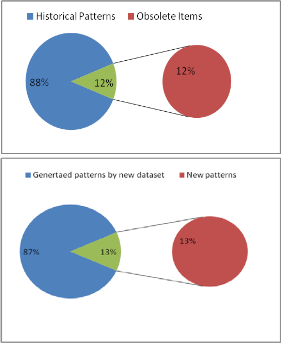
for various supports like 0.1%,0.08% and 0.05%. Figure 5 dis- cussed buying behavior of customers’ for 0.1% of support val- ue. 33% patterns are obsolete patterns, which are no longer in existence for later captured datset.12% (single) items are not preferred by customers.13% totally new preferences (sequenc-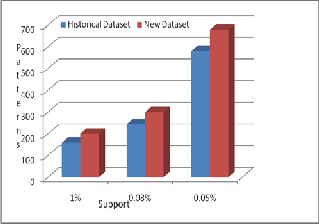
Fig 2: Sequence generation w.r.t support
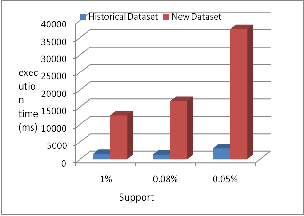
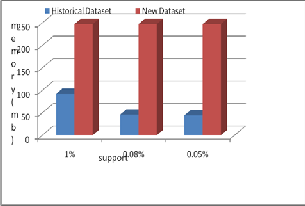
Fig 3: Execution time Vs. support
Figure 3: Execution time w.r.t support
Figure 4: Memory consumption w.r.t support
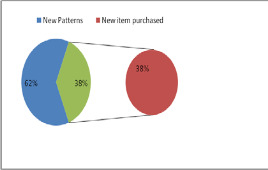
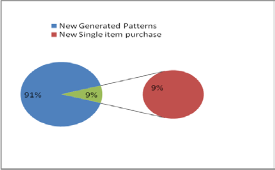
es) are chosen by customers. Out of these new patterns, 31% new items are chosen alone.28.75% patterns are generated by item 48 or sequences generated by item 48 w.r.t historical pat- terns, which are not in existence for dataset captured at later stage.
Business manager can follow the changing trends using pro- posed framework. It can be utilized at macro and micro level business analysis.
In macro aspect, business manager can track changing trend. It is important for them to detect their customers’ changing be- havior in order to provide products and services, which help them to with stand in competitive market. Detection of obso- lete and new buying behavior helps them to focus on accumu- lation of goods. Manager can understand the decreasing rate of co-purchase of two certain products and then decision mak- er can examine the reason and develop a prevention plan to preserve the trend.
In micro aspect, to track the changes are not only the sufficient factor for business manager but to understand how? and why?, parts in depth of such changes are equally important. Data captured at various time snapshot can help in detection of ob- solete buying patterns, as well helps to understand the reasons of its drop off. Like, due to technological advancement, poor service or due to another high competitive product leads the item or co-purchase toward declining. Same way incremental changes in preferences help to predict forming stage of any purchase, which lead business man one step ahead than com- petitor. Proposed framework is useful in marketing of product or service and helpful in target customer group with the ac- cumulation of demographics data.
Evaluation and survey analysis of data captured at various time snapshots are not only helps companies, to understand customers’ ever-changing needs, but also provides important information of future trend and incremental development of purchase tendency. For such purpose, growth of change is measured and on bases of that emerging patterns (EPs) are tracked. Proposed framework has also provides solution to detect new and obsolete trend. Paper has also outline practical use of proposed change detection framework for expansion and enhancement of business in macro and micro aspects.
Later stage of paper illustrates, experiments performed on real time retail data of Belgian supermarket store. Datasets are cap- tured at two different time snapshot. Average 12.13% more patterns are generated by dataset captured at later time slot.
33% patterns are obsolete patterns and 13% absolute new pat-
terns are detected. Paper is not more focused on how and why
part of change detection in purchase because of lack of de- mographics description of captured data.
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1359
ISSN 2229-5518
A B
C D
E F
Fig 5: Study of Historical Patterns (A,B,C) and New Patterns (D,E,F)
[1]Lui B.Hsu W., Han H.S. Mining changes for real-life applications.
Second International conference on Data warehousing and
Knowledge Descovery.2000 pp.337-346
[2] Ganti V ,Gehrke J ,Ramakrishnan R. Framework for measuring changes in Data characteristics. Proceding of the eighteenth ACM SIGACT- SIGMOD- SIGART symposium of principles of Database System (1999) pp.126-137
[3] R. Agrawal and R. Srikant.Fast Algorithms for Mining Association Rules. Preceding of 1994 International Conference of Very Large Da- ta Bases (VLDB ‘94). pp. 487-499
[4] Agrawal R. And Srikant R. Mining Sequential Patterns. Proceding of the 11th International Conference on Data Engineering.Taipei- Taiwan.March 1995.
[5]Cheung D.W,,Han J.,Ng V T & Wong. Maintenance of large associa- tion rules in large database: In incremental updating techniques Proceeding of 12th International conference on data engineering (1996). pp.106-114.
[6] Dong Ji & Li . Efficient mining of emerging patterns: Discovering
Trend and differences. Proceeding of fifth international conference
on Knowledge Discovery and Data Mining 1999 pp.43-52.
[7] J. Han, J. Pei, and Y. Yin.Mining Frequent Patterns without Candi- date Generation. Preceding 2000 ACM-SIGMOD. International Con- ference on Management of Data (SIGMOD ‟00).2000.pp.1 -12.
[8] Srikant R. and Agrawal R.Mining sequential patterns: Generaliza- tions and performance improvements. Proceedings of the 5th Inter- national Conference Extending Database Technology.1996.pp- 3-17.
[9] AYRES, J., FLANNICK, J., GEHRKE, J., AND YIU, T.Sequential pat- tern mining using a bitmap representation. Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2002.
[10] M. Zaki. SPADE: An Efficient Algorithm for Mining Frequent Se- quences. Machine Learning. vol. 40.2001. pp. 31-60.
[11] M. Garofalakis, R. Rastogi, and K. Shim.SPIRIT: Sequential pattern mining with regular expression constraints. VLDB'99.
[12] Han J., Dong G., Mortazavi B., Chen Q., Dayal U., Hsu M.-C.
Freespan: Frequent pattern-projected sequential pattern mining. Proceedings 2000 International Conference on Knowledge Discov- ery and Data Mining (KDD‟00).2000.pp.355 -359.
[13] J. Pei, J. Han, B. Mortazavi, H. Pino. PrefixSpan: Mining Sequential
Patterns Efficiently by Prefix- Projected Pattern
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 12, December-2014 1360
ISSN 2229-5518
Growth.ICDE'01.2001.
[14] Niti Desai, Amit Ganatra Sequential Pattern Mining Methods: A Snap Shot. IOSR Journal of Computer Engineering (IOSR-JCE) e- ISSN: 2278-0661, p- ISSN: 2278-8727.Volume 10. Issue 4,2013. PP
12-20
[15] Hee soek song,Jae Kyeong Kim, Soung Hie kim. Mining the change of customer behaviour in an internet shopping mall Expert system
with Applications. Elesvair Science Ltd .2001.pp. 157-168
[16] Tom Brijs and Gilbert Swinnen and Koen Vanhoof and Geert Wets.
Using Association Rules for Product Assortment Decisions: A Case Study .Knowledge Discovery and Data Mining,.1999.pp. 254-
260.
IJSER © 2014 http://www.ijser.org