Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 1
ISS N 2229-5518
Mechanism for Enhancing the Overall
Performance of Multicore Processors
Pankaj Rakheja , Charu Rana, Mandeep Singh Naru la
—————————— ——————————
mu lti-core proces sor is an integrated circuit (IC) in wh ich we have t wo or more proces s ors for enhancing the perfo r- mance, reducing power cons umption and having more eff i-
cient s imultaneous process ing of mu ltiple tas ks . The co mpos ition
and balance of the cores in the mult i-core a rchitecture s hows great variety. So me arch itecture e mploys only one core Des ign repeated cons is tently which are known to have homog eneous cores , while others us e a mixture of different cores , each opt i- mized fo r a d iffe rent role they are known to have heterogen eous cores . The general trend in proces sor development has moved fro m dual-, tri-, quad-, he xa-, octo-core chips to ones with tens or even hundreds of cores . This has been made pos s ible through advancement in s e miconductor technology and it is e xpected that number o f cores will increas e. Thes e advances have sustained the validity of Moore ’s law for s everal decades both in device count and performance.
The thread level parallelis m can be e xecuted efficiently in mult i-
core proces sors however this technique needs mo re para lle lis m in programs with increas e in number of cores . If we are unable to e xploit the thread level paralle lis m then performance gain will deteriorate.
In today’s s cenario cos t effective dependability for general pu r-
pose computing is demanded unlike before where h igh depend a- bility/reliability was necess ary for few applications and s ys tems only. Major challenge to this is the unreliable technologies e m- ployed for manufacturing mult icore proces s ors and me mories .
Some effect ive hardware and s oftware s olutions will have to be
———— ——— ——— ——— ———
Mandeep singh Narula is Assistant Professr in Institute of technology and
Management,Gurgaon,India,. E-mail: msnarula@itmindia.edu
developed for increas ing dependability on mult icore chips and computing s ys tems which are built v ia unreliable techniques .
In this paper we are propos ing a mechanis m cons idering both thes e as pects of the s cenario that is with e xtracting and e xp loit ing thread level paralle lis m in mult icore architecture through thread s cheduling and thread s wapping algorithms , we a re co mpens ating various flaws which may creep in due to unreliab le techniques emp loyed for developing thes e structures by adopting core s a l- vaging and faulty component is olation at micro architectural le v- el.
A. Enhancing performance through thread level para lle lis m
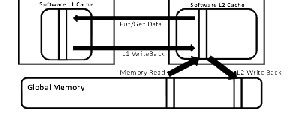
By e mp loying parallelis m in a given progra m mult icore proces s or can be e xecuted efficiently. So we have to e xtract thread level paralle lis m in progra m wh ich is quite difficult but mandatory to have good performance gain. For that we can us e idle e xces s cores on the chip. Yos uke M ORI and ken ji KENSE have pro- posed a cache core mechanis m[1] where the e xces s core behaves like an L2 data cache managed through a software progra m. They have utilized the fact that the communicat ion overheads in chip mu ltiproces s or between on chip cores are s malle r than between core and off chip me mo ry. And global me mo ry acces s frequency will a ls o reduce. Here if the progra m has to access the data in the global me mory it firs t access es the L1 cache. If L1 cache mis s occurs then it acces s es the L2 cache o f the cache core . They have us ed one e xces s core as cache core we can opt for mult iple cache cores which will be access ed bas ed on the instruction or applic a- tion program running in the main co mputation core to improve the hit ratio o f the L2 cache in cache core. And we need to des ign a mechanis m that cache core is isolated at the right time to i m- prove degradation of performance by the L2 cache mis s . Figure 1 below s hows communication a mongs t computation core, cache
IJSER © 2012
lume 3, Issue 2, February -2012 2
Moreover we need to make an improve ment in the L1 cache e m- ployed at the computation core by managing it through an i m- proved software code. For enabling a ll this we will us e virtual hardware and prefetcher code.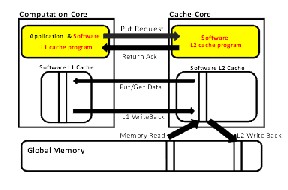
Figure 1. Cache core a rchitecture
B. Co mpens ating flaws due to unreliable techniques
With advancement in s emiconductor technology number of cores on chip has increas ed and performance has imp roved too. But fabrication technologies adopted are not that reliable becaus e of which s ome errors or defects creep in the s ys tem. The mos t i m- portant s ources of unreliable hardwa re operation can lead to s ys- tem fa ilure a re proces s variability that may lead to heterogeneous operation of identical co mponents , trans ient errors in s ubmic ron circuits and ageing effects due to extre me operating conditions . To compens ate thes e we can us e online error detection, recovery and repair s chemes that can guarantee low cos t dependability. For error detection we may e mp loy thes e approaches redundant e x- ecution, periodic built-in s elf tes t, dynamic verification and an o- ma ly detection techniques . Where in redundant execution t wo independent threads execute copies of the s ame progra m and re- s ults are co mpared; in periodic built -in tes t perform non coherent error detection by e xecuting periodic s elf tes ts ; in dynamic verif i- cation we e mploy dedicated hardware checkers to verify valid ity of s pecific invariants and thes e are carried out at run time and in anomaly detection we mon itor anomalous behavior or symptom of faults .
For error recovery and repair we can opt for two bas ic recovery techniques : Forward error recovery (does not require roll back to previous correct s tate) and backward error recovery (requires roll back to previous correct s tate). The redundant and non es s ential components can be dis abled to improve yield and performance. Repair techniques rely on the coordination of the fault diagnos is and is olation at different levels i.e circuit or a rchitectural level. Software anoma ly treat ment method [2] propos ed by Pradeep ra machandran, Siva ku ma r s as try hari, s arita V. adve is a co mpre- hens ive s olution to detect, diagnos and recover from variety of hardware faults by obs erving anomalous behavior of sys tem re- quiring fault detection, fault diagnos is and fault recovery co mpo- nents .
Dynamic verification of cores and memory s ys tem propos ed by
Danie l J .Sorin, Albert meixner is to check the ce rtain s ys tem wide invariants rather checking s pecific co mponents . It is ind e- pendent of imp le mentation and can detect errors due to s oft a nd hard faults .
Accidental heterogeneity can be dealt by core s alvaging propos ed
by Arjit Bis was that allows faulty core to continue operation. It avoids us age of faulty part of the core rather than dis abling whole core.
Here in this paper we will concentrate more on non redundant logic e mp loyed in many redundant s tructures like mu ltientry a r- rays made fro m decoders , buffers along with interconnects . We will a ls o lay s tress on improving thread s cheduling and thread s wapping algorithms which can be e mp loyed in mu ltico re pro- cess ors to enhance their performance.
C. Per-Co re Frequency Scheduling
Multicore a rchitectures offer a potential opportunity for energy cons ervation by allowing cores to operate at lower frequencies . Exis ting analytica l models for power cons umption of mu lticores ass ume that all cores operate at the s ame frequency where off- chip voltage regulator us ed to s et all s ibling co res to the s ame voltage level [3]. For off-chip regulators , cores on the s ame chip mus t operate at the s ame frequency and in cas e of mult iple chips , cores on different chips may operate at different frequencies , [4]. With the help of Turbo Boost [5] technology, better performance can be achieved by boosting all cores to a higher frequency, only when the processor is operating below rated powe r, te mperature, and current s pecification limits . Studies have s hown that s ignifi- cant energy can be achieved by controlling each core voltage. Recent advances leads to on -chip mult icore voltage regulator (MCVR) wh ich can accept an input voltage and s cale it down to a range of voltages to cut po wer according to CPU de mands . [6 ]
A fine gra ined model developed [7] a fter e xp loiting thes e tech-
nologies for energy efficient co mputations and manage ment of res ources . An energy aware res ource management mode l is uti- lized in this paper to reduce the power cons umption by multi cores operating at different frequencies and to provide a mecha n- is m for creat ing s chedule of res ource us age and frequencies at which proces s or cores s hould execute to co mplete co mputation.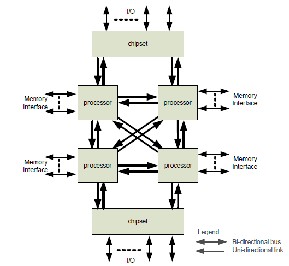
D. Intel Qu ickPath Interconnect Technology
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 3
ISS N 2229-5518
Figure 2. Intel quic kpath interconnect
Intel Quic kpath interconnect technology [8] s hown in figure 2 provides high speed, point to point connections between micro- process ors and external me mory, and bet ween microproces s ors and the I/O hub. It is imp le mented in Intel’s lates t generation microarch itecture along with integrated me mory controlle rs and dis tributed shared me mory a rchitecture.
In this technology each process or has its own dedicated me mo ry which can be access ed through me mory controllers . The dedica t- ed me mory of another proces sor can als o be access ed us ing high s peed Intel Quic kpath Intercon nect which lin ks all proces sors . This technology provides high bandwidth, low latency and e n- hances application performance and reliability for a wide range of mult i-core s ys tems .
We are here concentrating on all the as pects affecting perfo r- mance of the proces s or. The mechanis m p ropos ed here will try to optimize the performance with margina l tradeoff between s peed and efficiency of the process or. After analyzing the whole s cen a- rio the areas which need to be improved are L1 cache; process or to processor commun ication; Interconnections ; errors crept in due to non reliable fabrication technolog ies ; errors due to ma lfun c- tioning of non redundant logic; process or to me mory interaction; Clock frequency allotment and obtaining paralle lis m in applic a- tion program. While s olving thes e is sues we have take into co n- s ideration s peed, accuracy, cos t and effic iency of p rocess or they all need to be optimized. For that work has to be done in every
s phere of operation of proces sor at both hardware and s oftware
level.
A.
increas ed much but the divis ion of cache on the bas is of the type of ins truction it would be s toring that is dependable and und e- pendable execution ins truction will further enhance the pro cess or performance as hit rat io will improve this need to be managed through s oftware. Frequency allocation for c lock s hould be done on demand bas is the idle process or s hould be operated at low frequency to reduce power require ment.
B.
Improve ment at Software leve l
Improve ment at s oftware level is more important as we reduce e xtra hardwa re require ment wh ich will reduce cos t. Firs t the i m- provement needs to be done at L1 cache in computation core it s hould managed properly div is ion of cache into multip le leve ls can be done through s oftware managed program which will s tore frequent ins truction opcodes on bas is of the their type and opera- tion they perform wh ich will reduce the s eeking time and thus hit ratio will improve too. This can be done by obs erving or mon itor- ing control s ignal s tatus during fetching cycle. Then if data cache mis s is found then the cache core can be access ed. Multiple cache cores can be us ed so that if one is bus y then other can be referred. Then the commun ication a mongs t them can be improv ed through Intel’s quick path interconnect. Software ins truction opcode fetcher can be imp le mented and the corres ponding control s ignals generated can be buffered for each ins truction.
The overall proces sor with mu ltip le cores with thes e improv e- ments can be s een as below in figure 3 wh ich s hows conceptual overview of the whole s cenario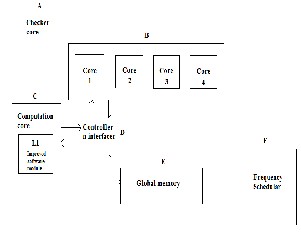
Improve ment at Hardwa re level
Here we have to improve the e xis ting hardware and fabricate new one on chip if neces s ary. We have mu ltiple cores on s ingle ch ip out of which certain a re idle. We can utilize thes e cores which will in turn reduce need of extra hardware. Thes e cores can be us ed as cache cores , checker core and co mmunicator core. Cache core will act as a data cache for the main computation core it will jus t behave as L2 data cache fo r the co mputation core. Checker core will be equipped with a s oftware program that will be cap a- ble of s eeking erroneous non redundant logic in the other cores and replacing that erroneous hardware by a s oftware module giv- ing the s ame res ult. So here we will be s alvaging at micro arch i- tectural level rather at architectural leve l. While the communic a- tion core will act as controlle r for co mputation core to cache cores communication it will be equipped with a s oftware progra m which would give it a s elf learn ing capability jus t like routers in the networking s o it will intelligent enough to access right cache core for s eeking data to reduce hit ratio. And moreover the inter- connections between thes e cores can be deployed through Intel’s quick path interconnect which will s peed up the whole process the type of interconnect deployed will be decided by the rate at which data need to be trans ferred that is on the bas is of app lica- tion. And levels of cache need to be aggravated s ize need not be
Figure 3: Conceptual overview
A. Checker core
It will be equipped with a s oftware module which will look for any dis crepancies in the functioning of the core and will ide ntify the ma lfunctioning of core by dynamic verification method wh ich analys is certain parameters on which performance of the core depends . Bas ic algorith m is s hown below
Step1: Depending upon the core architecture n application dete r-
mine para meters for analy zing perfo rmance
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 4
ISS N 2229-5518
Step 2: Then do periodic analys is of thes e parameters to look for any dis crepancy
Step3: If any dis crepancy found then execute the corres ponding module
Step4: go back to s tep 2
B. Multiple cores
It comp ris es of multip le cores wh ich are eq uipped with s oftware that enable them to be us ed as cache core which will bas ically s tore data. Here an id le core can be us ed as a data cache. The advantage of having mult iple data cache is that if the core being
us ed as a data cache has some urgent work t o do or has encou n-
tered an interrupt it could trans fer its data to neighboring core through controller n interface in between s o as the computation core has access to that data throughout. And moreover perfo r- mance of the core is the effected. Bas ic algorith m is s hown below
Step1: Cache core on encountering an interrupt moves to s tep 3
Step2: Execute L2 cache s oftware module indefinite ly
Step3: Trans fer the data to neighbor cache up to down and to in- terface and controller down to up s o that computation cach e has access to data mean while
Step4: Execute ISR
C. Co mputation core
The core which does computation is called co mputation core it will be equipped with an imp roved L1 ins truction cache along with L2 data cache. The s oftware will generate L1 cache where ins truction opcode will be s tored as per its type in order to im- prove cache hit rat io and L2 data cache will a ls o be ma intained their its elf to reduce core to core co mmunication if poss ible. Here an ins truction prefetcher can be employed which pre fetch all o p- codes of program to increas e parallelis m. Bas ic a lgorith m is s hown below
Step1: Divide the L1 cache into mult iple levels Step2: Store ins truction opcodes in res pective cache Step3: Acces s the right cache depending on its type
D. Controlle r and Interfaces
It aids in co mputation to cache core commun ication s o as to s peed up the process or it will be equipped with a fu lly fledged s oftware module, a proces sor to run that module and a s mall in- built me mo ry.
Step1: Send control mes s ages
Step2: Monitor core Cach e acces s reques t
Step3: Give Direct cache core acces s to computation core and If interrupt comes on bus y pin move to next s tep
Step4: Move data fro m cache to its te mporary me mo ry to give access to computation core n mean while t rans fer the data to new cache core
Step5: Move back to s tep2
E. Global Me mory
Here it is the me mory s hared a mongs t all the cores which is a c- cess ed via the controller or through dedicated lines not s hown in figure 3.
F. Frequency s cheduler
It will as s ign frequency or clock s ignal to the cores on the bas is of s tatus of the core that is if needs to work at bulk of data at a time or needs to speed up higher clock will be g iven and vice vers a. Bas ic algorith m is s hown below
Step1: Determine the core de mand Step2: Switch its clock s ource Step3: Goto s tep1
Multicore arch itectures are focus ed on improving the perfo r- mance o f the proces s or however their overa ll perfo rmance and s peed depends on the thread level paralle lis m, technique of fabr i- cation, fault detection and recovery, the ty pe of interconnections deployed, cache maintenance algorithms etc. He re in this paper we tried to cover all as pects over which the performance depends and sugges ted requis ite s teps which need to be carried out in o r- der to enhance the s peed, reduce power co ns umption, utilizing the available res ources at s ake to full and to manage mult iple cores in bes t poss ible way. The concept of mu ltip le cache cores , controller and interface, chec ker core and Qu ick path interco n- nect will optimize the overall s cenario. Futu re work co mpris es of imple menting in on s imu lator to analyze by what factor perfo r- mance imp roves and then burning it on chip and analyzing real time cons traints .
.
Yos uke Mori, Kenji Kis e, “The Cache-Core Architec- ture to Enhance the Memory Performance on Multi- Core Proces s ors ”, International Conference on Parallel and Dis tributed Computing, Applications and Technolo- gies , 2009.
Arijit Bis was et. al., “Architectures for Online Error De-
tection and Recovery in Multicore Proces sors ”, EDAA,
2011
Naveh, E. Rotem, A. Mendels on, S. Goch man, R. Ch a- buks war, K. Kris hnan, and A. Ku mar, "Power and Thermal Manage ment in the Intel Core Duo process or," Intel Technology Journal, vol. 10, no. 2, pp. 109 -122,
2006.
[4] X. Zhang, K. Shen, S. Dwarkadas , and R. Zhong, "An Evaluation of Pe r-Chip Nonuniform Frequency Scaling on Multicores ," in Proc. o f USENlXAT C, 2010.
IJSER © 2012
Inte rnatio nal Jo urnal o f Sc ie ntific & Eng inee ring Re se arc h, Vo lume 3, Issue 2, February -2012 5
ISS N 2229-5518
[5] "Intel Turbo Boos t Technology in Intel Core Microarc- hitecture (Nehale m) Bas ed Proces sors ," White paper, In- tel, November 2008.
[6] W. Kim, D. Brooks , and G. -Y. Wei, "A Fully-Integrated
3- Level DC/DC Converter for Nanos econd -Scale DV S
with Fas t Shunt Regulation," in Proc. of ISSCC, 2011.
[7] Xinghui Zhao and Nadeem la ma li, Fine -Gra ined Per- Core Frequency Scheduling for Po wer Effic ient Mult i- core Execution, Proceedings of the 2nd IEEE Intern a- tional Green Co mputing Conference (IGCC 2011, pp:1--
8, July 2011.
[8] An Introduction to the Intel Quic kPath Interconnect, White Paper,Intel, January,2009.
IJSER © 2012