International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 1214
ISSN 2229-5518
Image Segmentation For CT Image With Artefact
Sharmila.G , Dr.V.Valli Mayil
—————————— ——————————
An image is an artefact that depicts or records visual perception, for example a two-dimensional picture, that has a similar appearance to some subject – usually a physical object or a person, thus providing a depiction of it. Image processing is any form of signal processing for which the input is an image, and the output of image processing may be either an image or a set of characteristics or parameters related to the image. Image segmentation is the process of partitioning a digital image into multiple segments or dividing the given image into regions homogenous with respect to certain features, and which hopefully correspond to real objects in the actual scene. Segmentation plays a vital role to extract information from an image to create homogenous regions by classifying pixels into groups thus forming regions of similarity. Image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics. To reduce the artefacts caused by metal in images the image has to be segmented. Clustering approaches were one of the first techniques used for the segmentation. K-means clustering algorithm is used to segment the artefact image. K-Means clustering algorithm is an unsupervised learning and partition-al clustering algorithm which attempts to directly decompose the dataset into a set of disjoint clusters based on similarity between objects. After segmenting the image, the ROI has to be taken for further processing.
Segmentation partitions an image into distinct regions containing each pixels with similar attributes. The main idea of the image segmentation is to group pixels in homogeneous regions and the usual approach to do this is by common feature. Features can be represented by the space of colour, texture and gray levels, each exploring similarities between pixels of a region. The goal of segmentation is to simplify and change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries (lines, curves, etc.) in images. The result of image segmentation is a set of
regions that collectively cover the entire image, or a set of
contours extracted from the image. Each of the pixels in a
region are similar with respect to some characteristic or computed property, such as colour, intensity, or texture. The segmentation is based on the measurements taken from the image and might be grey-level, colour, texture, depth or motion. Image segmentation techniques are categorized into three classes: Clustering, edge detection, region growing. Some popular clustering algorithms like k-means are often used in image segmentation. In this paper, K-Means clustering algorithm is used to segment the metal artefact image from which the further processing has to be made to reduce the artefact from the image.
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups. The groups are called clusters. Clustering is a data mining technique used in statistical data analysis, data mining, pattern recognition, image analysis etc. Because of its simplicity and efficiency, clustering approaches were one of the first techniques used for the segmentation of textured images. Clustering can be divided as partitional and hierarchical clustering. Hierarchical clustering algorithms repeat the cycle of either merging smaller clusters in to larger ones or dividing larger clusters to smaller ones. Partitional clustering algorithms generate various partitions and then evaluate them by some criterion. In partitional clustering, the goal is to create one set of clusters that partitions the data in to similar groups. A clustering algorithm attempts to find natural groups of components (or data) based on some similarity. Also, the clustering algorithm finds the centroid of a group of data sets.To determine cluster membership, most algorithms evaluate the distance between a point and the cluster centroids. The output from a clustering algorithm is basically a statistical description of the cluster centroids with the number of components in each cluster.
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 1215
![]()
ISSN 2229-5518
IMAGE DATA SET
CLUSTERING ALGORITHM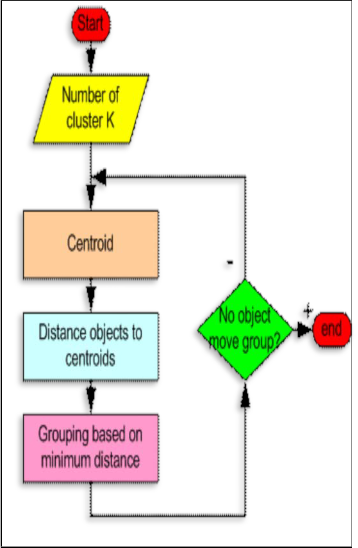
CLUSTEREDI MAGE
A good clustering method will produce high quality clusters with high intra-class similarity and low inter-class similarity. The quality of clustering result depends on both the similarity measure used by the method and its implementation. The quality of a clustering method is also measured by its ability to discover some or all of the hidden patterns. Image Segmentation is the basis of image analysis and understanding and a crucial part and an oldest and hardest problem of image processing. Clustering techniques classifies the pixels with same characteristics into one cluster, thus forming different clusters according to coherence between pixels in a cluster. It is a method of unsupervised learning and a common technique for statistical data analysis used in many fields such as pattern recognition, image analysis and bioinformatics. In this paper K-means clustering approach is used for performing image segmentation using Matlab software.
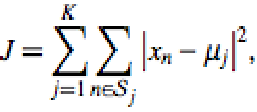
K-means clustering is an partitional clustering technique which attempts to directly decompose the dataset into a set of disjoint clusters based on similarity between objects. K-means clustering algorithm is one of the simplest unsupervised learning algorithms that solve the well known clustering problem. The k-means algorithm is an algorithm to cluster n objects based on attributes into k partitions, where k < n. An algorithm for partitioning (or clustering) N data points into K disjoint subsets Sj containing data points so as to minimize the sum-of-squares criterion
where, xn is a vector representing the the nth data point and uj is the geometric centroid of the data points in Sj. K-Means clustering is an algorithm to classify or to group the objects based on attributes/features into K number of group. K is positive integer number. The grouping is done by minimizing the sum of squares of distances between data and the corresponding cluster centroid.
Step-by-step process of k-means algorithm :-
1. Initially, the number of clusters must be known, or chosen, to be K say.
2. The initial step is the choose a set of K instances as centres of the clusters. Often chosen such that the points are mutually “farthest apart”, in some way.
3. Next, the algorithm considers each instance and assigns it to the cluster which is closest.
4. The cluster centroids are recalculated either after each instance assignment, or after the whole cycle of re- assignments.
5. This process is iterated.
K-means is a clustering algorithm, which partitions a data set into clusters according to some defined distance measure. Images are considered as one of the most important medium of conveying information. Understanding images and extracting the information from them such that the information can be used for other tasks is an important aspect of Machine learning. One of the first steps in direction of understanding images is to segment them and find out
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 1216
ISSN 2229-5518
different objects in them. To reduce the artefact, the artefact region has to be segmented so that the algorithm namely K- means clustering is used to segment the image. It has been assumed 1that the number of segments in the image is known and hence can be passed to the algorithm. K-Means algorithm is an unsupervised clustering algorithm that classifies the input data points into multiple classes based on their inherent distance from each other. The algorithm assumes that the data features form a vector space and tries to find natural clustering in them. The functions of k-means are as follows. IDX = kmeans(X,k) partitions the points in the n-by-p data matrix X into k clusters. This iterative partitioning minimizes the sum, over all clusters, of the within-cluster sums of point- to-cluster-centroid distances. Rows of X correspond to points, columns correspond to variables. Kmeans returns an n-by-1 vector IDX containing the cluster indices of each point. By default, kmeans uses squared Euclidean distances [8,9]. When X is a vector, kmeans treats it as an n-by-1 data matrix, regardless of its orientation.[IDX,C] = kmeans(X,k) returns the k cluster centroid locations in the k-by-p matrix C.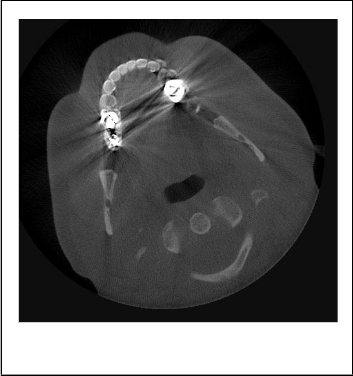
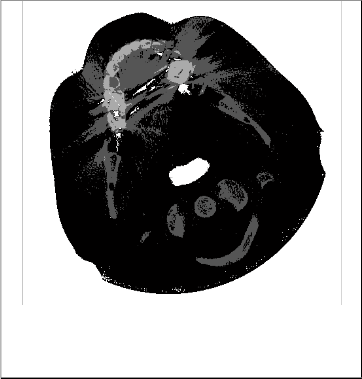
Figure 1. Original image with artifact
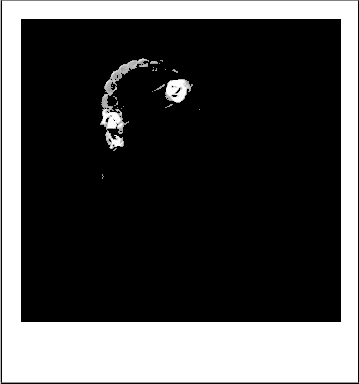
Figure 2. Image labeled by cluster index
Figure 3. Objects in cluster-1
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 1217
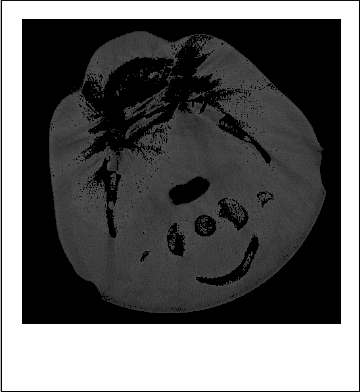
ISSN 2229-5518
Figure 4. Objects in cluster-2
Figure 6. Objects in cluster-4
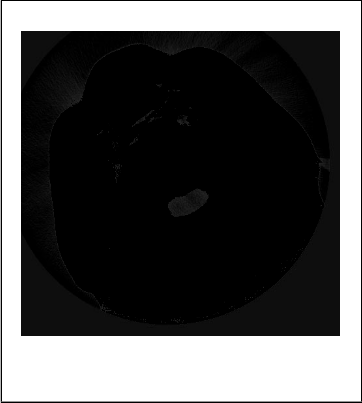

To reduce the artefact in the image, the artefact region has to be taken first and then find the approximate values of the hidden pixel are to be found. To segment the artefact region k- means clustering algorithm has been implemented and segmented the artefact image into k number of images. K- means algorithm has been successfully implemented. The next step of reducing the artefact is to find the hidden pixel values. The result aims at developing an accurate and more reliable image which can be used to reduce the artefact from the image and help the physicians for medical diagnosis.
Figure 5. Objects in cluster-3
[1] J.A Hartigan “Clustering Algorithms”, New York Wiley 1975.
[2] S. P. Lloyd, ―”Least squares quantization in PCM,” IEEE Trans.
Inf.Theory, vol. IT-28, no. 2, pp. 129–136, Mar.1982.
[3] J. Besag, “On the statistical analysis of dirty pictures,”J. Roy. Statist.Soc. B, vol. 48, pp. 259–302, 1986.
[4] S. Zhu and A. Yuille, “Region competition: Unifying snakes, region growing, and Bayes/MDL for multiband image segmentation,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 18, no. 9, pp. 884–900, Sep.1996.
[5] S.Mary Praveena, Dr.IlaVennila,” Optimization Fusion Approach for
Image Segmentation Using K-Means Algorithm”, International Journal of
Computer Applications (0975 – 8887)Volume 2 – No.7, June 2010.
IJSER © 2014 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 1218
ISSN 2229-5518
[6] A.M Uso,F.Pla,P.G Sevila,” Unsupervised Image Segmentation using a Heirarchical Clustering Selection Process”.Structural Syntactic and Statistical Pattern Recognition Vol 4109,pp.799-807,2006.
[7] A.Z Arifin,A.Asano,”Image Segmentation by histogram thresholding using hierarchical cluster analysis”Pattern Recognition Letters,Vol.27,no.13,pp. 1515-1521,2006.
[8] J.L Marroquin,F. Girosi,,”Some Extentions of the K-Means Algorithm For
Image Segmentation and Pattern Classification”, Technical Report,MIT Artificial Intelligence Laborartory,1993. International Journal of Information Technology (IJIT), Volume – 1, Issue – 1, August 2012 ISSN
2279 – 008X International Academic and Industrial Research Solutions
(IAIRS) Page 17 .
[9] M.Luo, Y.F.Ma ,H.J. Zhang,”ASpecial Constrained K-Means approach to Image Segmentation”,proc. The 2003 Joint Conference of Fourth International Conference on Informations Communications and Signal Processing and the Fourth Pacific Rim Conference on Multimedia,Vol.2,pp.738-742,2003.
[10] M.Betke, N.C Makris, ”Fast Object Recognition in Noisy Images Using
Simulated Annealing”, Intl.Conf on Computer Vision,pp.523,Jun.20-
23,1995.
[11] T. Kanungo, D. M. Mount, N. Netanyahu, C. Piatko, R. Silverman, & A.
Y.Wu (2002) “An efficient k-means clustering algorithm: Analysis and
Dr.V.ValliMayil,.Director Of MCA, Vivekanandha Institute
Of Information And Management Studies,Tiruchengode.E-
Mail-ID: vallimayilv@gmail.com ![]()
implementation” Proc. IEEE Conf. Computer Vision and Pattern
Recognition, pp.881-892.
[12] J. Shi and J. Malik, ―Normalized cuts and image segmentation, ‖ IEEE
Trans. Pattern Anal.Mach. Intell., vol. 22, no. 8, pp. 888–905, Aug.2000.
IJSER © 2014 http://www.ijser.org