
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2034
ISSN 2229-5518
Health Monitoring of Network Using Probing
Aparna Gaikwad, Prof. B.M.Patil
Index Terms— Active monitoring, Health monitoring, Network Monitoring, Passive monitoring, Probing.
—————————— ——————————
the network can be managed and controlled using the collected
Day by day the nature and the complexity in the networks are
increasing. The wide spread of Internet brought the world closer
as well as challenges too. So monitoring of the networks becomes
information. Network monitoring techniques are developed to allow network management applications to check the states of their network devices. [3]
IJSER
at most important to face and tackle these challenges of failures,
reliability, QoS, etc. For monitoring the health of human beings doctors check the relevant anatomical parameters like, blood pressure, sugar level and other relevant health indicators, likewise networks are needed to be monitored for different performance metrics. A network operations team/admin can optimize network uptimes and avoid significant drops in QOS by monitoring and managing prioritized indicators of network health to keep them within optimum range of target states.
Difficult and demanding task on modern network infrastructures is network Management. Network management very often re- quires the human intervention to create management plans, to coordinate network assets, and to face up to fault situations. Be- cause of the increasing cost of network downtime and the com- plexity of deployed systems, it has become crucial to find a relia- ble way of managing communication networks and their services. These systems need constant monitoring and probing for the pur- poses of management, particularly for configuration setting, fault diagnosis, and performance evaluation, but, as the size of net- works increases, it becomes more and more difficult to extract the right information from them.
So for getting the right information from the network we require network monitoring which is a prominent function of network management. Network monitoring applications collect data from network management applications. Network monitoring is col- lects useful information from various parts of the network so that
————————————————
• Prof. B.M.Patil is currently pursuingPhD in Delhi University,India
There are too many measurable things in the network so what to
measure is important. These monitoring metrics are needed to be collected at various layers ranging from hardware layer, operating system to other layers. Monitoring techniques compute the per- formance problems such as: Process observe heavy CPU usage, Process execution time spent in disk write, etc. These metrics are useful for future network expansion and smooth running net- work.
Quick detection and isolation of unhealthy components in net- work makes it reliable and robust. Hence techniques used for monitoring are processing data from network components, pas- sive monitoring and active monitoring.
Passive monitoring [3] relies on the ongoing traffic to infer the performance of various components. So in absence of traffic it cannot measure such metrics. Hence probes can be used to pro- duce specific traffic and allow passive monitors to observe it. Through passive monitoring, a security admin can gain a thor- ough understanding of the network's topology: what services are available, what operating systems are in use, and what vulnerabil- ities may be exposed on the network. It computes the statistics at the thread level, module level and component level. The analysis these levels can be explained using bayesian networks, neural networks and decision trees.
Probing is nothing but a probe transactions, the examples of probes used for probing [10] are pings, trace-routes, HTTP re- quests, etc. Previous days preplanned probing was used which involves designing a preplanned set of probes that is capable of diagnosing all possible failure scenarios of interest and sending this set of probes periodically in the network. But this generates large amount of wasteful management traffic and increase the
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2035
ISSN 2229-5518
inaccuracy in the network state.
Probes used for this can be of the form of:
Probes can also be Http requests to check the availability and re- sponse time of the nodes and server.
Probes can also be ping sent to test connectivity and availability of the nodes.
Active probing adapts the probing strategy to the observed net- work state. Instead of sending probes for locating all potential problems in the network, it sends a minimal number of probes initially and then adapts the probe set to the observed network state [7]. The probe stations then send probes that provide most information gain. This approach can greatly reduce management traffic and provide more accurate and timely diagnosis. Probing [9] provides flexibility in the design of probe streams with partic- ular properties to match measurement requirements.
This paper is organized as follows. Section 2 gives a brief discus- sion of related work done. In Section 3, we introduce the concept of health monitoring using probing and present details of health monitoring and identification algorithms for health monitoring. Section 4 describes future work of health monitoring using prob-
ing. Finally, a summary is given in Section 5.
measures or monitors the metrics pertaining to certain network element such as link throuput, packet size statistics. It has been used for monitoring web based applications. Analysis in passive monitoring is done with inspecting the packet headers which cre- ates security problems. Also passive monitoring requires more instrumentation but in addition it creates less traffic. Active moni- toring [8] is typically used to obtain end-to-end statics such as latency, loss and route availability. It requires less instrumentation but it creates additional traffic to network. Also the probes used in active monitoring modify the root conditions and perturb the very traffic being monitored.
An extended symptom-fault-action model to incorporate actions into fault reasoning process to tackle the problems is called active integrated fault reasoning (AIR), which contains three modules: fault reasoning, fidelity evaluation and action selection. Corre- sponding fault reasoning and action selection algorithms are re- quired for that.
Adaptive monitoring [4] is framework using end-to-end probing based solutions to adapt at-a-point monitoring tools. ILP and greedy algorithms are used for probe selection and monitoring level recommendation and ROC, DFN for probe analysis. But it require probe station selection and probes selection. Also it will
not work with dynamic changes in the network.
During initial stage of monitoring of networks only the passive
monitoring is used. But the passive monitors have its own limita-
tions such as collect information at only one point. Work done on the network monitoring also consist of following parts obtaining data from network equipment is based on the IETF standard, SNMP (Simple Network Management Protocol) and NETCONF, Passive monitoring and probing.
There are various tools which collect information from vari- ous network components and do processing on it such as trac- eroute which calculate packet loss and delay but it requires spe- cial routers for data collection, MHealth having global reachabil- ity but restricted on RTP and SDR applications also require mtrace enhanced routers. MRM is a step forward toward efficient multicast active monitoring; its deployment will be limited be- cause of using a proprietary protocol and special agents. Offline and online tools [5] are used for root cause analysis. But if off-line transaction log analysis does not find the root cause then it will try to find root cause by running more transaction which creates more data storage. Snort’s open source network-based intrusion detection system (NIDS) has the ability to perform real-time traf- fic analysis and packet logging on Internet Protocol (IP) networks. Snort performs protocol analysis, content searching, and content matching. The program can also be used to detect probes or at- tacks, including, but not limited to, operating system fingerprint- ing attempts, common gateway interface, buffer overflows, server message block probes, and stealth port scans. Passive monitoring
Many researchers have used passive monitoring and probing [1]
in isolation but the novel approach combines it to form an inte-
grated probing which is used for distributed health monitoring. Integrated probing sends fewer probes to healthy area of the net- work and more probes to unhealthy areas which create less traffic as well it require less instrumentation.
In the architecture of the system main part of the network is serv- er having central control of system. In order to develop a health monitoring system for large network sizes, there is need to devel- op a distributed approach with central system. The centre node i.e. server is aware of the information of the entire network and make decisions accordingly. As in this server itself do its own health checking so there are very few chances of its failure.
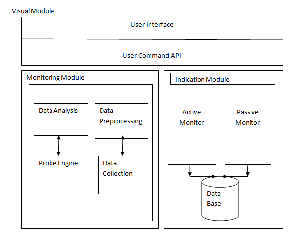
The architecture shown in fig. 1 consist of three major modules as, visual module represents the graphical view of output and the user requirements, Monitoring module computes passive and active measurements used for collecting and processing the net- work traffic, Indication module is used for indicating the criticali- ty of network component. Indication module stores the running process status and other indication of failed network component with its own database. Checking is done in indication module and according to which server do the action.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2036
ISSN 2229-5518
Fig.1 Health monitoring architecture [11]
Indication module is capable of fault correction and future net- work health. In this server sends the probes in the network for monitoring purpose. These probes ping the nodes in the network and starts the passive monitoring at each node. Passive monitor- ing will check the health parameters in the node continuously. If fault is occurred at any node then again the fault is diagnosed by sending additional probes and exact reason of fault is identified. If
there are multiple faults occIurred aJt a node thenSpriority algo- ER
rithm is applied and we localize the fault having high priority.
Server will do server monitoring for checking its own health and sniff the data from the port so that it will get details of other nodes in the network.
After getting details of network it will store it in the database for further processing. Server will sniff the health parameters for eve- ry five seconds and nodes do there passive monitoring for every
2sec. If the particular node is unhealthy then the server will get more information about it immediately and for healthy node it will sniff data with increased time period because of this network will have less traffic. Server will identify the component or pro- cess responsible for performance degradation. In this way after localizing a fault or unhealthy area of the network with the help of finer probes that can identify bottleneck or estimate cross traf- fic.
The health parameters are obtained by using WMIC tool. It is con- sole based tool used for getting criticality of the system and net- work.
Algorithm for health monitoring can be described as follows:
In this way this process continues and it will continuously check
the details of network. Probes are used by server for getting de- tails of network. Hence, there is only one probe station [7] for the network. Probe results are further analyzed to infer health of net- work and for estimating criticality.
By observing the performance degradation or failure, these probes point the processes which are root causes. Nodes having cpu, memory, disk space are some critical resources and if the server or nodes are over-utilize them then crash may occurred. Server network performances mainly consist of four categories as: port listener, ping host, analyzer and bandwidth monitor. While server/node health consist of cpu usage and running process. With the help of this health of the network can be maintained efficiently.
The algorithm for the passive monitoring is as shown below.
In this we have considered the health parameter as CPU utiliza- tion and memory utilization. This algorithm gives output as true if node is faulty or false if node is healthy.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2037
ISSN 2229-5518

Health monitoring using probing approach in the network makes the network healthy and efficient. But working with large, diversi- fied and complex network is still research challenge. Also in fu- ture we can still minimize the probe traffic and make the network healthy.
With an example of integrated probing, we demonstrated how active probing and passive monitoring can be used to comple- ment each-other to develop effective solutions. We believe that powerful network management solutions can be designed by adopting a hybrid approach that uses both passive monitoring and active probing. Also the system monitoring and recovery of system is helpful for maintain health of the network.
[1] M. Natu and A. S. Sethi. Probabilistic fault diagnosis using adaptive probing. In DSOM 2007, San Jose, CA, Oct. 2007
[2] M. Natu and A. S. Sethi. Application of adaptive probing for fault
The flow diagram of health monitoring is as follows:
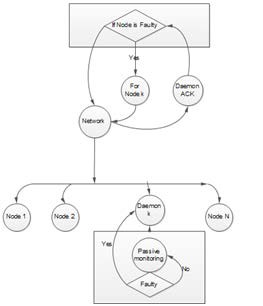
Fig 2.Flow Dig For HSM
This system will measure and monitor the performance and iden- tify whether it is normal, optimal or overloaded. Server sends probes to clients for their health checkup for e.g. consider server sends 10 probes to 10 clients. In this network of 10 clients if 1 node is unhealthy then server will send the probes continuously for further analysis. For healthy node server will send less frequent probes. So it will reduce the probes used for monitoring.
diagnosis in computer networks. In NOMS’08, Apr. 2008.
[3] Se-Hee Han, Myung-Sup Kim, Hong-Taek Ju, and James Won-Ki Hong. The Architecture of ng-mon:A passive Network Monitoring System for high speed ip Networks. In DSOM’02,2002.
[4] Deepak Jeswani, Maitreya Natu and R. K. Ghosh, “Adaptive Monitor- ing: hybrid approach for Monitoring using Probing, 2012.
[5] Ling Huang, Xuanlong Nguyen, Minos Garofalakis, and Joseph M.
Hellerstein. Communication-efficient online detection of network- wide anomalies. In INFOCOM’07, 2007.
[6] Y. Tang, E. S. Al-Shaer, and R. Boutaba. Active integrated fault locali- zation in communication networks. In IM 2005, pages 543–556, May
2005.
[7] M. Natu and A. S. Sethi. Probe station placement for robust monitor- ing of networks. Journal of Net work and Systems Management, 2007. To appear.
[8] M. Natu and A. S. Sethi. Using adaptive probing for fault diagnosis.
Computer Networks, 2007. Submitted..
[9] M. Natu and A. S. Sethi. Using adaptive probing for fault diagnosis.
In IEEE GLOBECOM 2007, Washington, D.C., Nov. 2007.
[10] M. Natu and A. S. Sethi. Active probing approach for fault localiza- tion in computer net works. In End-to-End Monitoring Workshop, E2EMON 2006, Vancouver, Canada, pages 25–33, Apr. 2006.
[11] Mohd Nazri Ismail and Sera Syarmila “Network Management Sys- tem Framework and Development” in 2009 International Conference on Future Computer and Communication.
IJSER © 2013 http://www.ijser.org