In HLBA[11], Yun et al puts forth the idea of load
ALCi=L,m
a CPU2 + a NU2 + a MU2 + q2
balancing so as to reduce completion time of jobs and to
International Journal of Scientific & Engineering Research, Volume 3, Issue 5, May-2012
ISSN 2229-5518
Enhanced Hierarchical Load Balancing
Algorithm in Grid Environment
Joshua Samuel Raj, Hridya K. S, V. Vasudevan
—————————— • ——————————
HE sophisticated technological manipulation demands the utilization of grid systems. Grid computing necessitates dynamic resource creation,
job allocation which can be computationally intense, clustering, and coordination of the processing entities. The heterogeneous and homogeneous characteristics[1] of resources add to the complexity of the scheduling problem.
For scheduling jobs[2] to dynamic resources, improved versions of traditional algorithms were formulated. Most of the algorithms that dealt with scheduling were inconsiderate of load balancing[3] issues, which is a critical issue in grid environment. Scheduling algorithms computes the fitness factor for resources and allocates jobs to most eminent resources. The drawback in this method of allocation is that fittest resources get overloaded and other resources remain unutilized. Such scheduling practices impact the overall system throughput. This paper puts forth an enhanced algorithm for allocating fittest resources to jobs coupled with load balancing. The experimental results shows improved system throughput and reduced makespan for computation.
This paper is divided into sections as follows: Section 2
explains the key concepts, section 3 describes the related works, section 4 gives the description of enhanced algorithm and finally, section 5 provides implementation details, section 6 gives the conclusion and future enhancement.
Clustering[4] is the grouping of multiple resources to form a single large highly capable system. The resources include multiple computers, workstations,
storage devices, interconnections etc. Clustering can be employed for accomplishing load balancing and system availability.
Clustering also comes up with the advantages like reliability, performance and low- cost. Clusters divide computationally intense tasks among multiple systems so as to reduce workload on a particular server, thus accomplishing load balancing. Clustering finds its applications in scientific computing, commercial servers etc.
Ungurean as in [5] defines scheduling issue as Best mapping of jobs to processors so that the desired cost function is optimized. Objective of scheduling must be to reduce the total cost, i.e., the sum of computation cost and communication cost. Scheduling is a set of rules and policies to control the order of job execution in a system. Scheduling can be long term, medium or short term according to the type of task to be executed. Scheduling can be static or dynamic, online or batch mode.
Belabbas et al as in [6] explains load balancing as an efficient methodology in grid system whereby tasks are distributed among multiple resources so as to improve efficiency and system performance.
Load balancing strategies include local or global, static or dynamic, distributed or centralized, cooperative or non cooperative etc. Load balancing can be intra-cluster, inter-cluster, static or dynamic.
Probability[7] distribution is the likelihood of a variable to take a given value. Probability distribution can be discrete or continuous. Discrete probability distribution calculates the probability of occurrence of countable
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 3, Issue 5, May-2012
ISSN 2229-5518
number of events or samples.
In DLBA[8], each cluster communicates their load with each other. When tasks are allocated to the clusters, current load is calculated. If the cluster becomes overloaded the task is transferred to the neighborhood cluster whose load value is below threshold. DLBA employs decentralized load balancing methodology and task transfer will be carried out on the fly. The algorithm ensures performance of the system and avoid system imbalance.
In MFTF[9], jobs are allocated to resources based on the fitness value. Higher the fitness value of a resource, more suitable the resource. Fitness value is calculated based on expected execution time and estimated execution time. If the estimated execution time is less than the expected execution time, the source is considered to be of high fitness value.
The fitness value is calculated using the equation:
computing power of each resource. The average computing power is calculated using available CPU utilization and current CPU utilization. HLBA then calculates the average load of each resource and compares it with a balance threshold. If ALC is higher than balance threshold, the cluster is considered to be overloaded. The under loaded clusters with high ACP are chosen and jobs are assigned to it.
In this section, the proposed algorithm called Enhanced Hierarchical Load Balancing Algorithm is being explained. It puts forth a method for job allocation to fittest resource coupled with load balancing .
In EHLBA, a method for resource allocation with load balancing is being put forth. It inherits the ideas of Hierarchical Load Balancing algorithm in “[11]”. When a job request comes, the scheduler initializes job parameters and find the Expected computing power, ECP for each job using the equation (3)
Fitness ( i, j )= 100000 /(1+| Wi / Sj - Ei |) (1)
ECPi=L,t
CPUSpeedk /t (3)
Where Wi is the workload of job i, Sj is the CPU speed of node j, and Ei is the expected execution time of job
i.
BACO[10] is derived from Ant Colony Optimization algorithm. The purpose of BACO is to reduce the job
Where CPUSpeedk is the MIPS requirement of each task k in a job i. t is the number of tasks in job i.
EHLBA uses HLBA in calculating the ACP, ALC and
Average System Load as shown below.
The algorithm calculates ACP, average computing power using equation (4)
completion time together with load balancing. The
ACPi=L,n
CPU_speedk ∗ (1 − CPUk )
algorithm calculates the weight value, called pheromone for each resource. Jobs are assigned to resources based on the pheromone value. Initially the pheromone value and pheromone indicator value will be same. The pheromone indicator shows the status of resource, size of jobs, program execution time so as to select the best suitable resource.
The pheromone indicator PI is calculated as given below:
PIij=[Mi/bandwidthi + Ti/(CPU_Speedi × (1 − loadi)]-1
(2)
Mi is the size of the job j, bandwidthi is the bandwidth between a scheduler and the resource to which it is connected. The estimated execution time is calculated using the equation Mi/ bandwidthi. Tj is the time taken to execute job j, CPU_speedi is the CPU speed of resource i, and loadi is the current workload on the resource i.
k=1 /n (4)
Where CPU_speedk is the available MIPS of resource k in cluster i and CPUk is the current CPU utilization of resource k. Here n is the number of resources in cluster i. Three weighted value parameters are used for load calculation, namely a1, a2 and a3. These are known as the weight factors. The weight factors a1, a2 and a3 provide a support for CPU utilization, network utilization and memory utilization respectively. For the cluster to execute instructions at a faster rate, the CPU utilization should be high. In the case of network utilization, if the data transfer speed is less, then the transfer time of the cluster will increase. Similarly, if the memory utilization is high, time taken for computation will increase. All these factors may affect the load of the system and in turn the system throughput. So, we choose weight values that are high for CPU utilization and network utilization. And small weight value for memory utilization. The algorithm calculates the average load of cluster using equation (5).
In HLBA[11], Yun et al puts forth the idea of load
ALCi=L,m![]()
a CPU2 + a NU2 + a MU2 + q2
balancing so as to reduce completion time of jobs and to
k=1 1
k,i
2 k,i
3 k,i
k.i
(5)
increase system performance. The algorithm chooses suitable resource for jobs by considering the average
Where CPUk,i is the current CPU utilization of resource k, NUk,i is the current network utilization of resource k,
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 3, Issue 5, May-2012
ISSN 2229-5518
MUk,i is the current memory utilization of the resource k, and qk,i is the queue length of resource k in cluster i. a1, a2, a3 are the three weight values with values 0.6, 0.3 and 0.1 respectively.To calculate the average system load using equation (6)
In HLBA, when a job request comes, the scheduler initializes the cluster parameters and retrieves cluster information from Grid Information system like ALC, memory utilization etc and computes the ACP for each
AL=1/mL,m
ALCi
(6)
cluster. The cluster with the highest ACP is selected and
checked if its ALC is less than balance threshold. If the
Here ALCi is the Average Load of Cluster i, m is the number of clusters in the system.
The deviation of Average System Load from ALC of each cluster is found out and the probability value is checked for confinement within the range of 0 to 1 as shown below.
diff_ci=ALCi – Average system load if(0< P(diff_ci)<1)
selected cluster is under loaded job is allocated to it. Otherwise, cluster with next highest ACP is which is underutilized is found out. The algorithm also employs local and global updates to inform the scheduler the current load status of the system and the clusters.
Whereas, in EHLBA, on receiving a job request the
scheduler initializes job as well as cluster parameters. The job parameters include OS requirement, MIPS rating etc for a cluster. Whereas, the job parameters
underloaded_list[]=ci
initialized by scheduler include,
current memory
All clusters with probability of deviation
within the
utilization, current load on cluster, current number of
jobs waiting to be executed etc. In our algorithm, we
given range is considered as under loaded. The clusters
consider only the MIPS rating requirement in the task
with values outside the given range is
marked as
clause. The scheduler calculates
ECP of each job
overloaded and discarded from current
cycle.
scheduling
together with ALC, Average System Load and ACP of clusters before job allocation. The algorithm find the
The ACP of these under loaded clusters is compared
with the ECP value of jobs. Clusters with ACP less than or equal to ECP is marked as fittest and jobs are allocated to it. The algorithm is represented using Fig
4.1
deviation of ALC with the Average system load and find out the probability value of deviation for every cluster. If the probability of deviation is within the range of 0and 1, the cluster is marked as under loaded. The ACP of under loaded clusters are compared with the ECP of jobs. If the ACP value of a cluster is less than or equal to ECP of jobs, the cluster is considered as fittest and job is allocated to it.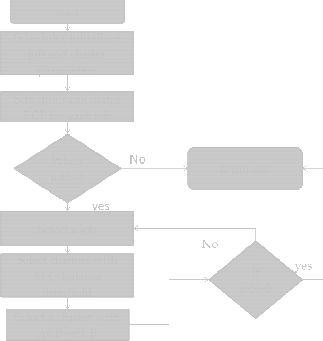
In EHLBA, task clauses in the
job request are
Fig 4.1: flowchart for EHLBA
recorded and the number of tasks are initialized. A task clause includes the stipulations for a job . The number of tasks in a job is determined by the number of task clauses. The scheduler calculates the number of tasks t by perusing the number of task claus s. The computing power requirement, ECP of a job i is calculated using the equation (3).
ECP is the expected computing power requirement of a job i, CPUSpeedk is the MIPS rating required by the clusters to execute task k in job i. t is the number of tasks in job i.
The ACP, ALC, and Average system load is calculated using the HLBA algorithm. To calculate the load of each cluster the weighted values a1, a2, a3 is chosen from a set of three, ie, a1=0.6, a2=0.3, a3=0.1; a1=0.3, a2=0.6, a3=0.1; a1=0.1, a2=0.3, a3=0.6.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 3, Issue 5, May-2012
ISSN 2229-5518

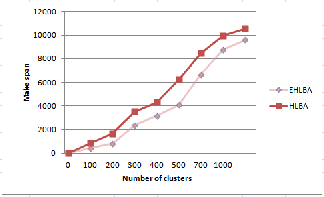
power. But the algorithm does not consider the load factor for these resources, which results in multiple search cycles to come up with a resource that is under loaded and with high ACP. Another demerit of HLBA is that a job will be allocated to a cluster with high ACP, even if the computing power requirement of the job is minimum. This can impact on the system throughput. Whereas, EHLBA, underutilized clusters are selected with ACP less than or equal to ECP. Fig 4.2 show the result of both the algorithms.
Fig 5.1- Graph showing makespan for weighted values in EHLBA
and HLBA
The weighted value set, a1=0.6, a2=0.3, a3=0.1, with reduced makespan is employed for load calculation of each resource in a cluster. Each weight factor corresponds to three different cluster parameters namely, CPU utilization, network utilization and memory utilization. EHLBA then calculates the average load of cluster ALC is calculated using Eq(5). After calculating ALC for clusters, the algorithm calculates the Average System Load, AL using Eq(6). The deviation between ALC of each cluster and the Average system load, which is calculated using Eq(7) is ciphered. The probability that the deviation value x falls between the range (0<x<1) is checked for each cluster. If the condition is satisfied the cluster is marked as under loaded.
Before allocating jobs to under loaded clusters ECP of job is checked with the ACP of cluster. Clusters with ACP less than ECP of jobs are the most suitable resource and jobs are allocated to it. Fittest cluster is the one whose ACP is same as the ECP of jobs. Fig 4.2 shows the flowchart for algorithm execution.
The flowchart shows the algorithm execution steps. HLBA and EHLBA are compared. Both the algorithms are executed with 500 and 1000 jobs each. The experimental results shows that EHLBA has lower makespan than HLBA. The parameters used for simulation are shown in table 4.1.
TABLE 5.1![]()
![]()
PARAMETERS FOR EHLBA Parameters Value
Number of clusters 15
Number of jobs 50
Number of tasks 500
Computing power of resource nodes 3000-5000
Baudrate 100-1000![]()
HLBA selects clusters based on the highest computing
Fig 5. 2- Graph showing makespan for HLBA and EHLBA
In EHLBA, the job allocation is done ensuring that the load of the system is balanced. EHLBA establishes more number of balanced clusters than HLBA. This improves the system performance together with load balancing which in turn improves the performance of individual resources in the system. This is reflected in the fig 5.2, which shows the reduced makespan of individual clusters in the computational grid system.
In this paper, an enhanced algorithm is put forward to reduce the makespan of algorithm execution and to allocate fittest resources to jobs coupled with load balancing. EHLBA collects job and cluster parameters to calculate the ECP and ACP for the jobs and clusters. In order to evaluate cluster imbalances the ALC and Average System Load are calculated. The clusters with probability of deviation between ALC and Average system load within the range of 0 and 1 are marked as under loaded clusters. The ACP of these clusters are compared with the ECP of jobs. If the value of a given cluster is less than or equal to ECP of a job, the cluster is considered fittest and job is allocated to it. The experimental results shows that the makespan of EHLBA is found to decrease than HLBA. The load balancing methodology employed in EHLBA is found to be less complex compared to that in HLBA.
The algorithm does not deal with dynamic heterogeneous clusters . In future, we would like to extend our work to accomplish load balancing using heterogeneous dynamic clusters.
IJSER © 2011 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 3, Issue 5, May-2012
ISSN 2229-5518
[1] Elisebeth Holemen, Magnar Forbord, Espen Gressetvold, Ann- Charlott Pedersen, Tim torvatn, “A Paradox? Homogeneity in the imp perspective”, 19th Annual International IMP Conference, Sept
2003, pp: 1-20;
[2] Hongzhang Shan, Leonid Oliker, Warren Smith, Rupak Biswas, “Scheduling in Heterogeneous Grid Environments: The Effects of Data Migration”, 2004.
[3] Sandeep Sharma, Sarabjit Singh, and Meenakshi Sharma, “Performance Analysis of Load Balancing Algorithms”, World Academy of Science, Engineering and Technology, Vol No: 38,
2008, pp: 269-272.
[4] Ming- Wu, Xian- He Sun, “A General Self Adaptive Task Scheduling System For Non Dedicated Heterogeneous Computing”, Research work supported by National Science Foundation, 2005.
[5] Ungurean, “Job Scheduling Algorithm based on Dynamic
Management of Resources Provided by Grid Computing Systems
”, Electronics and Electrical engineering, Vol: 103, No: 7, 2010. [6]Belabbas Yagoubi, Yahya Slimani, “Load Balancing Strategy in Grid Environment”, Journal of Information Technology and Applications, Vol: 1, No: 4, March 2007, pp: 285-296.
[7]Charles M. Grinstead, J. Laurie Snell, “Introduction to
Probability”.
[8]Elle El Ajaltouni, Azzedine Boukerche, Ming Zing, “An Efficeint Dynamic Load Balancing Scheme for Distributed Simulations on a Grid Infrastructure ”, 12th 2008 IEEE/ACM International Symposium on Distributed Simulation and Real Time Applications, pp: 61- 69.
[9]Ruay- Shiung Chang, Chun- Fu lin, Jen-Jom Chen, “Selecting
the most fitting resource for task execution”, Future Generation
Computer Systems, 2011, Vol: 27, pp: 227-231.
![]()

Hridya K. S
PG student, SE Karunya University.
Brief Biographical History:
Graduated in 2009 from Information Technology Department from Mangalam College of Engineering under Mahatma Gandhi Unversity. Currently persuing M.Tech in Software Engineering in Karunya University.
![]()

V. Vasudevan
Director, Software Technologies Lab, TIFAC Core in Network Engineering,
Srivilliputhur, India
1984- M.Sc in Mathematics and worked for several areas towards
Representation Theory
1992 Received his Ph.D. degree in Madurai Kamaraj University
2008- the Project Director for the Software Technologies Group of TIFAC Core in Network Engineering and Head of the Department for Information Technology in Kalasalingam University, Sirivilliputhur, India
Grid computing, Agent Technology, Intrusion Detection system, Multicasting and so forth
[10] Ruay- Shiung Chang, Jih- Sheng Chang, po-Sheng Lin, “An
Ant Algorithm for Balanced Job Scheduling in Grids”, Future generation Computer Systems, 2009, Vol:25, pp:20-27.
[11] Yun-Han Lee, Seiven Leu, Ruay- Shiung Chang, “Improving
job scheduling algorithms in a grid environment ” Future generation computer systems, May 2011.
![]()

R. Joshua Samuel Raj
Assistant Professor / CSE Karunya University.
2005 -Graduated in 2005 from the Computer Science and
Engineering Department from PETEC under Anna University
2007 -Received M.E Degree in Computer Science and Engineering from Jaya College of Engineering under Anna University
2009 Working towards the Ph.D degree in the area of Grid
scheduling under Kalasalingam University
Grid computing, Mobile Adhoc Networking, Multicasting and so forth
![]()
IJSER © 2011 http://www.ijser.org