International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2029
ISSN 2229-5518
Dynamic Algorithm Selection for Data Mining
Classification
Suhas Gore, Prof. Nitin Pise
Abstract— Recommending appropriate classification algorithm for given new dataset is very important and useful task but also is full of challenges. According to NO-FREE-LUNCH theorem, there is no best classifier for different classification problems. It is difficult to predict which learning algorithm will work best for what type of data and domain. In this paper, a method of recommending classification algorithms is proposed. Meta learning tries to address the problem of algorithms selection by recommending promising classifiers based on meta- feature. Dynamic Algorithm Selection (DAS) with knowledge base, focus on the problem of algorithm selection, based on data characteristic. Algorithm selection will be better by using DAS in knowledge discovery process. In this paper we discuss the DAS architecture with knowledge base and Recommendation parameter measure. We present the architecture of DAS approach and Analysis of K-similar dataset produced by knowledge base.
Index Terms—Supervised Learning, Dynamic Algorithm Selection, Classification, Data Characteristic, Ensemble Learning,NO-Free-Lunch theorem, Knowledge Base,KNN.
1 INTRODUCTION
—————————— ——————————
UR main approach is to develop an application that rec- ommends most suitable algorithm based on the accuracy measure. Various data analysis, aspects and real time
In data mining, concept of similarity and distance is crucial. We consider the problem of defining the distance between two
different dataset by comparing statistics computed from the
IJSER
application suffer from this algorithm selection problem. Ma-
chine learning can have strong impact of algorithm selection
problem.
Data Mining [21] is a process that extracts patterns from the
large datasets. There are major research areas in Data Mining
including association mining, clustering, classification, web
mining, text mining, etc. Classification is one of the techniques
in Data Mining that solves various problems like algorithm
selection, model comparison, division of training and testing data, preprocessing. It is 2 step processes
Build classification model using training data. Every object of the data must be pre-classified. The model generated in the preceding step is tested by assigning class labels to data ob- jects in a test dataset.
The test data is different from the training data. Every element of test data is also pre-classified in advance. The accuracy of the classification model is determined by comparing true class labels in the testing set with those assigned by the model.
Meta-learning [3] is to learn about training classifiers them- selves, i.e. to predict the accuracy of algorithm on given da- taset. This prediction is based on extracting meta-features; these are the feature that describes the dataset itself. These meta-features are used to train a meta-learning model on training data. Afterwards this training strategy is applied on meta-features of new dataset. The result is the classifier with high accuracy and performance. In last two decades, different approaches have been presented in the field of meta-learning.
————————————————
• Suhas Gore is currently pursuing masters degree program in Computer engineering in Pune University, India. E-mail:goresuhass@gmail.com
• Prof. Nitin Pise is currently pursuingPhD in Pune Universi- ty,IndiaEmail: nnpise@yahoo.com
dataset. For distance calculation, we use Euclidean distance
and Manhattan distance. Here we used 38 dataset from vari-
ous domain and 9 algorithms of different class namely: IBK,
SMO, Random Forest, Logit Boost, Naïve Bays, J48, Adaboost,
PART, and Bagging.
Research Objective:
The objective of this work is to present a comprehensive em- pirical evaluation of algorithm selection technique in the con- text of supervised learning from diverse data. The main idea to recommend to the user an algorithm or set of algorithms based on the most similar dataset that are found in the knowledge base. Classification measure and basic architecture of our Dynamic algorithm selection (DAS) system is described in section 2 & 3 respectively.
2 RELATED WORK
There are several theoretical and practical reasons why we may refer an adaptive learning system. A survey on ensemble learning gives several advantages of adaptive learning. Fol- lowing are some papers which describes some novel approach of algorithm selection.
Ensemble based [8] system may be more beneficial than their single classifier counterparts, different algorithms for generat- ing ensemble components and various procedures through which the individual classifier can be combine. CBR [2] ap- proach contains several advantages for algorithm selection, the user gets a recommendation of algorithms suitable or da- taset as well as it gives an explanation for recommendation. CBR approach contains CASE that represents the knowledge about the execution of a special algorithm on a specific da- taset. There are different classification measures, different ap- proaches of algorithm selection. This is based on working of
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2030
ISSN 2229-5518
Meta learning methods: Acquisition Mode and Advisory Mode. A recommendation method for classifier selection is presented in [3]; it is based on data set characteristic with an aim to assist people in algorithm selection process among a large number of candidates for a new classifier problem. In this method, the Data set feature is first extracted, the nearest neighbor of new dataset is then recognized and their applica- ble classifiers are identified.
Rule base classifier election approach is proposed, based on the prior knowledge of problem characteristic and the Exper- iments. The main aim is to assist in the algorithm selection of an appropriate classification algorithm without the need of trail-and-error testing on a vast array of available algorithms knowledge Base.
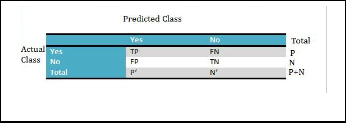
Fig. 1. Confusion Metrix
TABLE 1
where a large proportion of the scores are towards the ex- tremes are said to be platykurtic.
Kappa-statistics: It is a statistical measure of inter-rater agree- ment or inter-annotator agreement for qualitative (categorical) items.
Entropy: Entropy is measure used in Decision tree algorithm for attribute selection. On the basis of selected attribute, classi- fication is done for binary data.
Signal to noise ratio: Signal-to-noise ratio is defined as the power ratio between a signal (meaningful information) and the background noise (unwanted signal):
2.2 Data Characteristics
The data characteristic tool DCT[2] computes various meta data about a given data set. Subsequently, we characterize the relevant data characteristic. The data characteristic can be sep- arated into three different parts:
1. Simple measurement or general data characteristics
2. Measurements of discriminant analysis and other
measurement which can only be computed on numer-
ical attribute (DC_numeric).
3. Information theoretical measurement and other
measurement which can only be computed on sym- bolic attribute.(DC_symbolic)

CLASSIFICAITION MJEASURES SER
Measure Formula
Accuracy, Recognition Rate (TP+TN)/(P+N)
The first part contains measurements which can be calculated
for the whole dataset. The other group can only be computed
for a subset of attribute in the dataset. The measurement of
Error Rate, Misclassification
Rate
(FP+FN)/(P+N)
discriminant analysis and calculated only for numerical at-
tribute whereas the information theoretical measurement are
calculated for symbolic ones. All these measurements are cal-
Sensitivity, True Positive Rate TP/P
culated by our data characteristic tool (DCT)
Specificity, True Negative
Rate
TN/N
2.2.1 Simple Measurement or General Data Characteristic
Precision TP/(TP+FP)
2.1 Classification Measure
Confusion Matrix (As shown in fig 1) is useful tool for analyz- ing how well your classifier can recognize tuple of different class i.e. it indicates how accurately classification is per- formed. Here TP: True Positive, FN: False Negative, FP: False Positive, TN: True Negative [21].
Accuracy: It is the degree of closeness of measurements of a quantity to that quantity's actual (true) value.
Precision: Precision is used to retrieved fraction of instances those are relevant
Recall: Recall is used to retrieve fraction of relevant instances that are retrieved. Recall is the fraction of the documents that are relevant to the query that are successfully retrieved.
Skewness: It refers to whether the distribution is symmetrical with respect to its dispersion from the mean.for univariate data.
Kurtosis: It refers to the weight of the tails of a distribution,
IJSER © 2013
In algorithm selection problem the DCT tool determines the following general characteristic:
• NrRecords: number of records(n)
• NrAttr : number of attribute(m)
• NrBin: Number of binary attribute(nb)
• Sym: ratio of symbolic attribute (msym/m)
• NrClass: number of class(q)
• defError: default error rate defError=1-Accdef, (Accdef) probability of largest class or default accuracy.
• StdDev: standard deviation of the class distribu-
tion(σclass)
• rdefInst : Relative probability of defective rec- ords
rdefInst= ndeftuple/n
ndeftuple : number of record with missing
values
• rmissVal : relative probability of missing values:
rmissVal=hmissVal/(n*m)
hmissVal: number of missing values.
http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2031
ISSN 2229-5518
Beside the normal simple measurement system selected rela- tive measurements like the two last measurement. Such a ratio measurement contains more information and is more inter- pretable.
2.2.2 Discriminant Measurement:
Statistical DCT computes a discriminant analysis leading to the following measurement:
• Fract : Describes the relative importance of the largest eigen value as an indication for the im- portance of the 1st discriminant function.
• Cancor: Canonical correlation, which is an indica- tor for the degree of correlation between the most significant discriminant function and the class distribution. There is a strong correlation be- tween the class and the 1st discriminant function if this measurement is close to unity.
• DiscFct : Number of discriminant function.
• Wlambda : Wilks lambda or U-statics, describes the significance of the r discriminant function.
• Standard Deviation Ratio
• Mean Absolute Correlation attribute
• Skewness of attribute
• Kurtosis of attribute
classifier will work best for a given dataset, there are two op- tions. The first is to put all the trust in an expert‘s opinion based on knowledge and experience. The second is to run through every possible classifier that could work on the da- taset, identifying rationally the one which performs best. The latter option, while being the most thorough, would take time and require a significant amount of resources, especially with larger datasets, and as such is impractical. If the expert con- sistently chooses an ineffective classifier, the most effective classification rules will never be learned, and resources will be wasted. Neither methods, provides an effective solution and as a result it would be extremely helpful to both users and experts, if it were known explicitly which classifier, of the multitude available, is most effective for a particular type of the dataset.
1. Trial and Error Approach: Available Algorithms are applied for each dataset, Gives accurate recommenda- tion of algorithm but too costly, If m algorithm are ap- plied for n dataset then complexity is O(mn).
2. Random Selection: Randomly Selection of Classifier, Cost effective but Less Accuracy.
3. Expert advice: For each new dataset an expert advice is taken which is not always easy to acquire.
4. Case Base Reasoning: Classification is recommended based on previous case, i.e. for a dataset, some algo-
IJSErithms arRe tested on the basis of applicability test and
2.2.3 Information Theoretical Measurement:
Besides continuous (numerical) attribute, it is likely that sym- bolical attributes are used for describing a data space. There- fore, measures are needed to cover these (symbolic) dimen- sions as well. Again, the goal is primarily to investigate and deploy measures that are useful for the algorithm selection process. All these measurement are well known and based on the entropy of the attribute. Entropy measures have the com- mon property that they deliver information on the information content of attribute.
• Class entropy (ClassEntr)
• Join entropy (JoinEntr)
• Average mutual information (AttrEntr)
• Average Mutual information(MutInf)
• Relevance-Measure(EqNrArrt)
• Signal Noise Ratio(NoiseRatio)
Additionally, we also use a measurement of range of oc- curance defined by
SpanSym=SymMax-SymMin
AvgSym which is the average number of symbolic values, such measurement is indicators of the complexity and the size of the hypothesis space for the problem.
3 DAS ARCHITEURE
3.1. Approaches for algorithm selection
There are different approaches to solve issue of algorithm se- lection. For different datasets, different classifiers are applied on each of them. Based on some parameter such as accuracy performance of each classifier can be analyzed so as to rec- ommend best classifier for given dataset In deciding which
for each new dataset an algorithm is recommended.
5. Heterogeneous meta decision tree(HDMT): HDMT [9]
is induced in one domain and used in any other do-
main. In general HDMT clearly performs worse than
MDT. But they are more generally applicable across different dataset.
6. Feature_vector [1] approach: This is also a part of pro- posed approach, multiple experiments are performed on this approach, and some data is lost while calculat-
ing average value of feature vector. This approach fo- cus on only data of dataset instead of structure of da- taset.
7. DAS Approach: This is proposed Framework, which is a part of adaptive learning. Performance of classifica- tion algorithms are evaluated on number of dataset
with Knowledge base using KNN (Lazy Learners).
3.2. Architecute
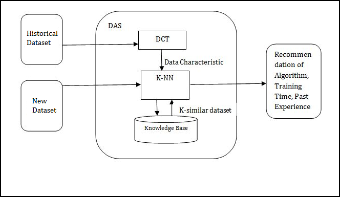
Architecture of DAS system is shown in figure 2, as out- lined in introduction, the problem of algorithm selection is based on these factors:
• New Dataset
• Historical Dataset
• K-NN
• DCT
• Knowledge Base
Dataset represents the training data as well as testing data, i.e. at the initial stage dataset are supplied to Data characteristic tool (DCT). DCT is a module used for the calculation of Data Characteristic such as accuracy, MIN, MAX, Standard Devia-
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2032
ISSN 2229-5518
tion etc, which will refer as META data. Furthermore knowledge bases contain the experience of known application as well, i.e. knowledge base represents knowledge about the execution of special algorithm on specific dataset. This knowledge includes training time, test time and error rate. Nearest neighbor classifier are based on learning by analogy, i.e. by comparing a given test tuple with training tuple that are similar to it. The training tuple are described by n attribute. Each tuple represents a point in an n-dimensional space. In this way, all the training tuples are stored in an n-dimensional pattern space. When given an unknown tuple, a K-nearest- neighbor (KNN) [21] classifier searches the pattern space for the k training tuple that are closest to the unknown tuple. These k training tuples are the k “nearest neighbor” of the un- known tuple.
ommendation method, verifying whether or not the method is potentially useful in practice, and allowing other researchers to confirm our results, we set up our experimental study as follows.
1. 38 data sets from the UCI repository [20] are used in the experiments. Knowledge base represents the number of in- stances, the number of attributes by which each instance is described (not including the class label), and the number of classes for each data set. In order to facilitate the calculation of the feature vectors, for data sets containing continuous values, we basically focus on information theoretic measures. As de- scribed in knowledge base, Number of attributes, instances, classed, symbolic, numeric and entropy are considered as Me- ta-feature.
2. 8 different types of classification algorithms are selected to classify data sets. They are probability-based Naive Bayes (NB); tree- based J48 and Random Forest, rule-based PART; lazy learning algorithm IB1; and the support vector algorithm Sequential Minimal Optimization (SMO) . Besides these single learning algorithms, we also employ the ensemble classifier algorithms. Bagging is applied with the three simple classifiers J48, PART and Naive Bayes as the base classifier, respectively. At the same time, Adaboost is also employed with the same three simple classifiers as the base classifier, respectively.
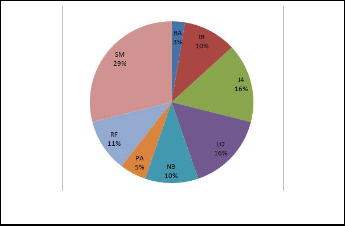
Fig. 2. ArchitecIture OF JDAS System SER
Flow:
A new approach is shown in fig. 2, first we have to calcu- late dataset characteristic for given dataset. A DCT (Data Characterization Tool) can be use to define dataset characteris- tic i.e. it computes various Meta data about given dataset. New dataset characteristic are provided to KNN (A lazy learner Algorithm) for analysis and then results are given to knowledge base. Knowledge base determines learning algo- rithm performance based on dataset characteristic. On the ba- sis of similarity between predefined dataset and new dataset an algorithm is recommended. Ranking based on results from knowledge base are provided so as to recommend a proper and suitable algorithm. Further results are used for prediction and decision making.
The general work flow is that the user specifies his require- ments and that the data characteristic for the given dataset is computed by DCT. These two groups of information define the problem description. Each case is defined by this problem description and a solution part, which specifies the applied algorithm as well as the experience gained from applying the algorithm. In our system we compute the most similar appli- cation problem description and offer the user also the results of the applied algorithm. Important is also to remark that problem description may be incomplete.
4 EXPERIMENTS AND ANALYSIS
For the purpose of evaluating the performance and effective- ness of our proposed classification algorithm selection rec-
Fig. 3. Chart of % of Classifier over 38 datasets.
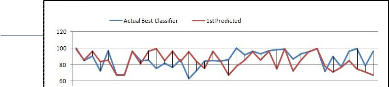
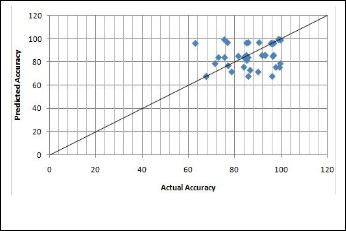
As shown in fig 3, it shows chart of percentage of accuracy of classifiers over 38 dataset. SMO is mostly best classifier occurs over 8 algorithms. Logit-Boost and J48 are also as best classifi- er over most of datasets, Most of these classifiers gives classifi- cation accuracy over 70%. Fig 4 represents best classifier for 38 dataset among these 8 classifiers, all accuracy are calculated through WEKA tool using 10-fold cross validation. Accuracy of all best classifiers is above 60%, so it indicates the algo- rithms chosen are average and over average. It describes the difference between actual best and predicted best, as shown in fig 5, there are very few dataset where difference need to be consider, for e.g. Dataset 38 having difference of about 28.As shown in number of objects on the line and below line indicat- ed predicted accuracy is equal or lesser than actual accuracy. Dataset 5,20,21,26,28,33,35,36,38 are having less prediction accuracy than actual accuracy. So remaining 29 are well rec- ommended. i.e. these gives 76% accurate results.
IJSER ©
http://www.ij
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 2033
ISSN 2229-5518
Data Analysis 53 (2009), “Taxonomy for characterizing ensemble methods in classification tasks: A review and annotated bibliog- raphy”2001
[5] Geoffrey I. Webb (author for correspondence), School of Computer Science and Software Engineering Monash University, Clayton, Vic- toria, 3800, Australia,” Multistrategy Ensemble Learning: Reducing Error by Combining Ensemble Learning Techniques” To appear in IEEE Transactions on Knowledge and Data Engineering.
[6] Nikolaj Tatti,” Distance between dataset based on summary statis- tic”, Journal of machine learning research 8(2007) 131-154
[7] Matthias Reif, M. Goldstein, A Dengel, “Automatic Classifier Selec- tion for Non-expert”,Pattern Analysis and application
[8] Robi Polikar, “Ensemble Based system in decision making ” IEEE
circuit and System Magazine 2006.
[9] B. Zenko,L Todorovski, S. Dzeroski, “Experiments with Heterogene- ous Meta Decision Tree”, IJS-DP 8638.
[10] Faliang Huang, Guoqing Xie and Ruliang Xiao Faculty of Software, Fujian Normal University, Fuzhou, China,” Research on Ensemble Learning”, 2009 International Conference on Artificial Intelligence and Computational Intelligence.
[11] Richard O. Duda, Peter E. Hart, David G. Stork,A book on ” Pattern
Classification” ,II nd edition.
[12] R. King, C. Feng, A. Suterland,”Stat-log: Comparison of classification algorithm on large real-world problem”.
[13] L.I. Kuncheva,” Combining Pattern Classifiers Methods and Algo- rithms”.New York, NY: Wiley Interscience, 2005.
[14] F. Roli, G. Giacinto, and G. Vernazza, “Methods for designing mul-
Fig. 5.Actual Best vs Predicted Best
5.CONCLUSION
According NFL, No single algorithm performs better for all type of dataset. There are different approaches to recommend algorithm from which Adaptive Learning (DAS) approach recommends approximate best classifier based on accuracy as performance measure with aim to assist non-experts in select- ing algorithm. Three different categories of meta-features, namely simple, statistical, information theoretic were used and comparatively evaluated. After generation of knowledge base, Ranking is provided based on accuracy in algorithm se- lection task
REFERENCES
[1] Q. Song, G,. Wang, C. Wang, “Automatic Recommendation of Classi- fication Algorithms Based on Dataset Characteristic”, Pattern Recog- nition 45(2012) 2672-2689
[2] Guido Lindner and Rudi Studer, “AST: Support for algorithm selec- tion with a CBR Approach”.
[3] Nikita Bhatt, Amit Thakkar, Amit Ganatra, “ A survey and current research challenges in meta learning Approaches based on dataset characterisstic”, International Journal of soft computing and Engi- neering, ISSN: 2231-2307, Volume-2, Issue-1, March-2012
[4] Lior Rokach, Department of Information System Engineering, Ben-
Gurion University of the Negev, Israel, Computational Statistics and
tiple classifier systems,” 2nd Int. Workshop on Multiple Classifier Systems,in Lecture Notes in Computer Science, J. Kittler and F. Roli, Eds., vol. 2096, pp. 78–87, 2001.
[15] Y. Lu, “Knowledge integration in a multiple classifier system,” Ap- plied Intelligence, vol. 6, no. 2, pp. 75–86, 1996.
[16] K. Tumer and J. Ghosh, “Analysis of decision boundaries in linearly combined neural classifiers,” Pattern Recognition, vol. 29, no. 2, pp.
341–348, 1996.
[17] L. Kuncheva and C. Whitaker, “Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy,” Ma- chine Learning, vol. 51, no. 2, pp. 181–207, 2003.
[18] R.O. Duda, P.E. Hart, and D. Stork, “Algorithm Independent Tech- niques,” in Pattern Classification, 2 ed New York: Wiley, pp. 453–
516,2001.
[19] U.Fayyad, K. Irani,”Multi-interval Discretization of Continuous- valued Attribute for Classification Learning”.Machine Learning1022-
1027
[20] C.J. Merz, and P.M. Murphy, Uci repository of machine learning database. Irvine, CA : University of California Department of infor- mation and Computer Science.
[21] J. Han, M. Kamber, “Data Mining Concepts and Techniques”, Mor- gan Kaufmannn Publishers, 2011.
[22] R. Valdovinos , J. Sánchez, Proceedings of the Fourth International
Conference on Machine Learning and Applications, 2005.
[23] Nikunj Chandrakant Oza, “Online Ensemble Learning a dissertation” submitted in partial satisfaction of the Requirements for the degree of Doctor of Philosophy, UNIVERSITY of CALIFORNIA, BERKELEY.
IJSER © 2013 http://www.ijser.org