International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1097
ISSN 2229-5518
Design of Square and Multiply and Accumulate(MAC) Unit by using Vedic Multiplication Techniques
C Ranjit Kumar G Rahul Ram N Chandu Reddy PigiliSuresh
Ranjitchennam06@gmail.com
This paper proposed the design of Square and Multiply and Accumulate(MAC) Unit using the techniques of Ancient Indian Vedic Mathematics that have been modified to improve performance. Digital signal processors (DSPs) are very important in various engineering disciplines. Faster additions and multiplications are of extreme importance in DSP for convolution, discrete Fourier transforms, digital filters,etc. As in all the arithmetic operations, it is the squaring which is most important in finding the transforms or the inverse transforms in signal processing.The speed of MAC depends greatly on the multiplier. Vedic Mathematics is the ancient system of mathematics which has a unique technique of calculations based on 16 Sutras. The work has proved the efficiency of Urdhva Triyagbhyam– Vedic method for multiplication which strikes a difference in the actual process of multiplication itself. It enables parallel generation of intermediate products, eliminates unwanted multiplication steps with zeros and scaled to higher bit levels using Karatsuba algorithm with the compatibility to different data types. Multiply-Accumulate is an extensible block using the Vedic multiplier module plays an important role in computing, especially digital signal processing. The coding is done in Verilog HDL and the FPGA synthesis is done using Xilinx Spartan library. The results show that design of MAC unit using Vedic multiplication is efficient in terms of area/speed compared to conventional Multiplication.
KEYWORDS: Vedic Mathematics, Vedic Square, Urdhva Triyakbhyam Sutra, Wallace tree, Karatsuba - Ofman algorithm.
1. Introduction
The demand for high speed processing has been increasing as a result of expanding computer and digital signal processing applications. Higher throughput arithmetic operations are important to achieve the desired performance in many real-time signal and image processing applications. The key arithmetic operations in such applications are multiplication and squaring. Since multiplication and squaring dominates the execution time of most DSP algorithms, so there is a need of high speed multiplier and a squaring of a number. Minimizing power consumption for digital systems involves optimization at all levels of the design. This optimization includes the technology used to implement the digital circuits, the circuit style and topology, the architecture for implementing the circuits and at the highest level the algorithms that are being implemented.
2. Vedic Mathematics
Vedic mathematics is part of four Vedas (books of wisdom). It is part of Sthapatya- Veda (book on civil engineering and architecture), which is an upa-veda (supplement) of Atharva Veda. It gives explanation of several mathematical terms including arithmetic, geometry (plane, co-ordinate), trigonometry, quadratic equations, factorization and even calculus.
His Holiness Jagadguru Shankaracharya Bharati Krishna Teerthaji Maharaja (1884- 1960) comprised all this work together and gave its mathematical explanation while discussing it for various applications. Vedic maths deals with several basic as well as complex mathematical operations. Especially, methods of basic arithmetic are extremely simple and powerful [2, 3].
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1098
ISSN 2229-5518
The word “Vedic” is derived from the word “Veda” which means the store-house of all knowledge. Vedic mathematics is mainly based on 16 Sutras (or aphorisms) dealing with various branches of mathematics like arithmetic, algebra, geometry etc. These Sutras along with their brief meanings are enlisted below alphabetically.
1) (Anurupye) Shunyamanyat – If one is in ratio, the other is zero.
2) Chalana-Kalanabyham – Differences and Similarities.
3) Ekadhikina Purvena – By one more than the previous One.
4) Ekanyunena Purvena – By one less than the previous one.
5) Gunakasamuchyah – The factors of the sum is equal to the sum of the factors.
6) Gunitasamuchyah – The product of the sum is equal to the sum of the product.
7) Nikhilam Navatashcaramam Dashatah – All from 9 and last from 10.
8) Paraavartya Yojayet – Transpose and adjust.
9) Puranapuranabyham – By the completion or noncompletion.
10) Sankalana- vyavakalanabhyam – By addition and by subtraction.
11) Shesanyankena Charamena – The remainders by the last digit.
12) Shunyam Saamyasamuccaye – When the sum is the same that sum is zero.
13) Sopaantyadvayamantyam – The ultimate and twice the penultimate.
14) Urdhva-tiryagbhyam – Vertically and crosswise.
15) Vyashtisamanstih – Part and Whole.
16) Yaavadunam – Whatever the extent of its deficiency.
These methods and ideas can be directly applied to trigonometry, plain and spherical geometry, conics, calculus (both differential and integral), and applied mathematics of various kinds. [ 1,4].
3. Design of Vedic Square
Urdhva – Triyagbhyam(Vertically and Crosswise):
Urdhva tiryakbhyam Sutra is a general multiplication formula applicable to all cases of multiplication. It literally means “Vertically and Crosswise
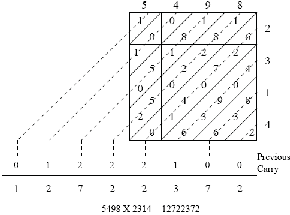
An alternative method of multiplication using Urdhva tiryakbhyam Sutra is shown in Fig. 1. The numbers to be multiplied are written on two consecutive sides of the square as shown in the figure. The square is divided into rows and columns where each row/column corresponds to one of the digit of either a multiplier or a multiplicand. These small boxes are partitioned into two halves by the crosswise lines. Each digit of the multiplier is then independently multiplied with every digit of the multiplicand and the two-digit product is written in the common box. All the digits lying on a crosswise dotted line are added to the previous carry. The least significant digit of the obtained number acts as the result digit and the rest as the carry for the next step. Carry for the first step (i.e., the dotted line on the extreme right side) is taken to be zero.
Figure.1. Alternative way of multiplication by Urdhva tiryakbhyam Sutra.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1099
ISSN 2229-5518
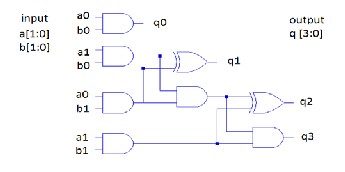
The design starts first with Multiplier design, that is 2x2 bit square multiplier as shown in Figure 2. Here, “Urdhva Tiryakbhyam Sutra” or “Vertically and Crosswise Algorithm”[4] for multiplication has been effectively used to develop digital multiplier architecture. This algorithm is quite different from the traditional method of multiplication, that is to add and shift the partial products.
Figure 2. Hardware Realization of 2x2 block square multiplier
To scale the multiplier further, Karatsuba – Ofman algorithm can be employed[6]. Karatsuba-Ofman algorithm is considered as one of the fastest ways to multiply long integers. It is based on the divide and conquer strategy[6]. A multiplication of 2n digit integer is reduced to two n digit multiplications, one (n+1) digit multiplication, two n digit subtractions, two left shift operations, two n digit additions and two 2n digit additions.
The algorithm can be explained as follows: Let X and Y are the binary representation of two long integers:
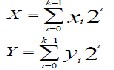
We wish to compute the product XY. Using the divide and conquer strategy, the operands X and Y can be decomposed into equal size parts XH and XL, YH and YL, where subscripts H and L represent high and low order bits of X and Y respectively.
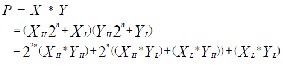
The product XY can be computed as follows:
For 32 bit vedic square, first the basic blocks, that are the 2x2 bit multipliers have been made and then, using these blocks, 4x4 block has been made by adding the partial products using carry save adders and then using this 4x4 block, 8x8 bit block, 16x16 bit block and then finally 32 x 32 bit Vedic Square as shown in Figure 3 has
been made.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1100
ISSN 2229-5518
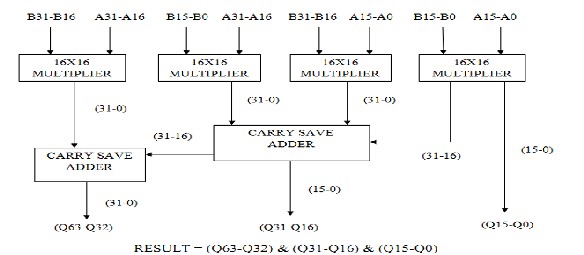
Figure 3: 32X32 Bits Vedic Square
The proposed Vedic Square implemented using two different coding techniques viz., conventional shift & add and
4. Implementation Of Vedic Square
Vedic technique for 8, 16, and 32 bit vedic squares. It is evident that there is a considerable increase in speed of the Vedic architecture. The simulation results for 8, 16, and 32 bit vedic squares are shown in the Figures 4.(a), (b), (c) respectively.
Simulation Results:
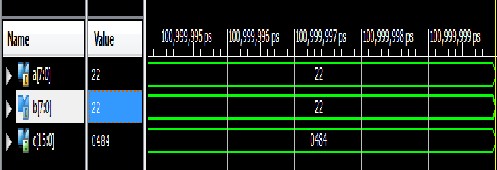
Fig. 4(a): 8 Bit Vedic Square
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1101
ISSN 2229-5518
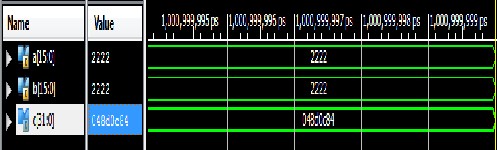
Fig. 4(b): 16 Bit Vedic Square
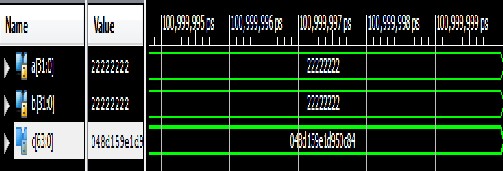
Fig. 4(c): 32 Bit Vedic Square
Synthesis Results:
Selected Device: 3s500efg320-5
Number of Slices: | 25 out of | 4656 | 0% |
Number of Slice Flip Flops: | 36 out of | 9312 | 0% |
Number of 4 input LUTs: | 48 out of | 9312 | 0% |
Number of IOs: | 9 | | |
Number of bonded IOBs: | 9 out of | 232 | 3% |
Number of GCLKs: | 1 out of | 24 | 4% |
Table 1.Comparison of Delays
Size | Algorithm | Delay in ns |
8 Bit | Wallace Tree Vedic Square | 15.718 15.418 |
16 Bit | Wallace Tree Vedic Square | 36.657 22.604 |
32 Bit | Wallace Tree Vedic Square | 62.834 31.526 |
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1102
ISSN 2229-5518
The worst case propagation delay in the Vedic Square case was found to be 31.526ns. To compare it with other implementations the design was synthesized on XILINX: SPARTAN: xc3s500e-5fg320[13]. Table 1 shows the synthesis result for various implementations. The result obtained from proposed Vedic Square is faster than Wallace Tree
5. Implementation Of Multiply and Accumulate(MAC)unit:
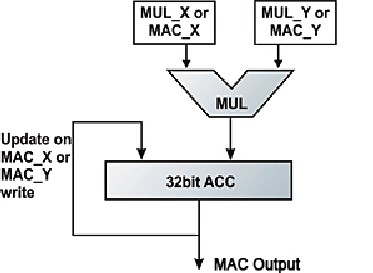
The MAC unit is built with Vedic multiplier. Hence the advantages of Vedic multiplier like increase in speed, decrease in delay, decrease in power consumption, decrease in area occupied will enhance the MAC unit also. Figure 5 shows the 32bit MAC unit. The DSP applications like Convolution (summation of multiplied terms), Correlation, Discrete Fourier Transform, Fast Fourier Transform etc employ the MAC unit, which assists in efficient computing in terms of speed, delay and complexity.
IJSER
Fig.5 : Multiply and Accumulate Unit
Performance Evaluation and Comparison:
The proposed MAC unit is implemented using two different coding techniques viz., Wallace tree and Vedic technique for 32 bit multiplier. It is evident that there is a considerable increase in speed of the Vedic architecture.
The simulation results for 32 bit multiply and accumulate unit is shown in the figure 6.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1103
ISSN 2229-5518
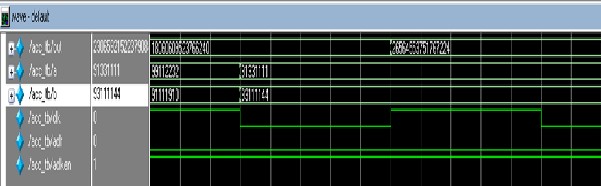
Fig 6: Simulation result of MAC Unit
TABLE 2
DELAY COMPARISON FOR DIFFERENT MAC UNITS
IJSER
The worst case propagation delay in the Optimized MAC unit using Vedic multiplier case was found to be
37.799ns. To compare it with other implementations the design was synthesized on XILINX: SPARTAN: xc3s500e-
5fg320[13]. Table 2 shows the synthesis result for various implementations. The result obtained from proposed
MAC unit using Vedic multiplier is faster than MAC unit using Wallace Tree.
6. CONCLUSION
The designs of 32x32 bits Vedic Square have been implemented on Spartan XC3S500-5-FG320. The design is based on Vedic method of multiplication [3]. The worst case propagation delay in the Vedic Square case is
31.526ns. It is therefore seen that the Vedic Square are much more faster than the Wallace Tree. This gives us method for hierarchical square design. So the design complexity gets reduced for inputs of large no of bits and modularity gets increased. MAC unit is presented based on Vedic method of multiplication[9]. This gives us method for hierarchical multiplier design. So the design complexity gets reduced for inputs of large no of bits and modularity gets increased.. The Multiply and Accumulate Unit designed with Vedic overlay high speed multiplier
algorithm exhibits improved efficiency in terms of speed and area.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 12, December-2013 1104
ISSN 2229-5518
REFERENCES
[1] 1964Booth, A.D., “A signed binary multiplication technique,” Quarterly Journal of Mechanics and Applied
Mathematics, vol. 4, pt. 2, pp. 236– 240, 1951.
[2] Wallace, C.S., “A suggestion for a fast multiplier,” IEEE Trans. Elec. Comput., vol. EC-13, no. 1, pp. 14–17, Feb.
[3] A.P. Nicholas, K.R Williams, J. Pickles, “Application of Urdhava Sutra”, Spiritual Study Group, Roorkee
(India),1984.
[4] Jagadguru Swami Sri Bharath, Krsna Tirathji, “Vedic Mathematics or Sixteen Simple Sutras From The Vedas”, Motilal Banarsidas, Varanasi(India),1986.
[5] Neil H.E Weste, David Harris, Ayan anerjee,”CMOS VLSI Design, A Circuits and Systems Perspective”,Third
Edition, Published by Person Education, PP-327-328]
[6] D. Zuras, On squaring and multiplying large integers, In Proceedings of International Symposium on Computer
Arithmetic, IEEE Computer Society Press, pp. 260-271, 1993.
[7] S.G. Dani, Vedic Maths’: facts and myths, One India One People, Vol 4/6,January 2001, pp. 20-21; (available on www.math.tifr.res.in/ dani).
[8] Thapliyal H. and Srinivas M.B. “High Speed Efficient N x N Bit Parallel Hierarchical Overlay Multiplier Architecture Based on Ancient Indian Vedic Mathematics”, Transactions on Engineering, Computing and Technology, 2004, Vol.2.
[9] “A Reduced-Bit Multiplication Algorithm For Digital Arithmetic” Harpreet Singh Dhilon And Abhijit Mitra, International Journal of Computational and Mathematical Sciences, Waset, Spring, 2008.
[10] Mrs. M. Ramalatha, Prof. D. Sridharan, “VLSI Based High Speed Karatsuba Multiplier for Cryptographic
Applications Using Vedic Mathematics”, IJSCI, 2007.
[11] “Lifting Scheme Discrete Wavelet Transform Using Vertical and Crosswise Multipliers” Anthony O’Brien and Richard Conway, ISSC, 2008,Galway, June 18-19.
[12] “A Reduced-Bit Multiplication Algorithm For Digital Arithmetic” Harpreet Singh Dhilon And Abhijit Mitra, International Journal of Computational and Mathematical Sciences, Waset, Spring.
[13] www.xilinx.com
Ranjit Kumar Chennamchetty(09121A1308) is completed his b tech in the stream of electronics and control engineering.
N Chandu Reddy (10121a1071)and Pigili(10121a1084) Suresh are pursing their final year b tech in the
stream of Electronics and Instrumentation Engineering. Rahul Ram(11121a1036) is pursing 3rd year B tech in the stream of electronics and instrumentation engineering . All are authors are from Sree Vidyanikethan Engineering College.
IJSER © 2013 http://www.ijser.org