large number of classes in which the transitionfrom one class to the next is practically continuous making it difficult to define hard class boundaries.
International Journal of Scientific & Engineering Research Volume 4, Issue 1, January-2013 1
ISSN 2229-5518
Emotions take part in a vital task in human being to human being dealings. From past few years there is great improvement in interaction between human and computers in all aspects. So there is the need in understanding the emotion of human face for the computer in several applications. This paper shows acquiring all kind of face expression of human face using neural network and Som. Feature extraction from the image is difficult task such as extraction the checks, eyes, eye brows, nose etc., from the human face so an effective thing is need to extract the feature. The back propagation is used to extract the feature from human face. The mapping of high dimensional space into small dimensional number by grouping all similar elements together is said to be SOM. Here we were using two level of clustering algorithm in Som. The two-level stage forceful SOM are producing prototypes are first level and second level stage we are applying clustering to well performed and very fine accurate compared with proposed clustering method and which reduces the error compared with existing one.
The emotion of the people may vary for different situation with different circumstance. The human sciences contain a collection of journalism on emotion which is bulky, but disjointed. Psychology and linguistics are two main approaches which are relevant to our approach, which is some information from human science. Communication and interaction are vital role in human to human communication and interaction study in perceiving facial emotions has enthralled the human computer interaction surroundings. There has been a growing interest in humanizing all feature of interaction between human being and computers especially in the spot of human emotion identification by watching facial lexis in recent years.
So here we proposing to recognizes all types of emotion of human being such as smile, loud laugh , irritating , disgust
, cheerful , fear , angry,joy ,neutral etc .,this can be made with the help of neural network and soc. The face detection and feature extraction is made by using neural network. In order to do the facial emotions. In order to establish the grouping of emotion, collection of face points from arrangements of face profile should be generated. Only with the help of face points the human face emotions are detected.
A successful face recognition attitude depends
heavily on the exacting alternative of the facial appearance used by the prototype classifier .The Back-Propagation is the finest known and broadlyworned learning algorithm in preparing multilayer perceptron (MLP). The MLP submit to the set of connections holding of a lay down of sensory units, source nodes that characterize the participationcover, one or more hidden layers of evaluation nodes, and an output layer of duplication nodes. The input signal distributesall the method through the set of connections in a further direction, from left to right and on a layer-by-layerbasis. Back
propagation is a multi-layer feed forward;administer learning network support on gradient decline learning rule. This BPNN make available with computationally efficient technique for varying the weights in feed forward network, with differentiable foundation function units, to learn a preparation set of input-output data. Being a gradient decline method it decrease the totality squared error of the productivitycalculate by the network. The seek is to prepare the net to complete a sense of balanceconnecting the capability to reactproperly to the participationoutlinethat are utilize for instruction and the capability to present good answer to the key in that are similar.
The SOM is used for clustering of data without knowing the input of the class memberships of the data. The som mainly detects the feature and also inherit the all the features in the input image, so they also can be called as SOFM,self organizing feature map. It provides a topology forming and maintains the map unit which is formed from high dimensional space.
Neurons is known as map units which creates the two dimensional lattice. The mapping is said as collecting the
high dimensional space onto the plane .the relation between the points are preserved by the mapping this maintain state in the form of relationship is the property of topology. Points that are close toeach one other in the key in space are mapped to close by map thing in the SOM. The SOM as a resulthand round as a gatherevaluatedinstrument of high- dimensional information. So there is generalizing capability in the Som. Generalize capability is that identifying the input in the network or pointing out the input which is present new in the system. A new input is incorporatedthrough the map unit, and this new input will be mapped in the network too.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue 1, January-2013 2
ISSN 2229-5518
The geometrical feature is used in the fields of regonization of human face .according to kanade feature extraction methods the regonization rate is about 45-75% which as the
20 people in the data base. Thegeometric feature is that collecting all the features from the image. By using the features of the image face can be recognized quickly. The extraction of feature in eyes, lips, nose, jaws as the feature from the normal human images.
3.2 Eigen faces
High-level identificationresponsibilities are
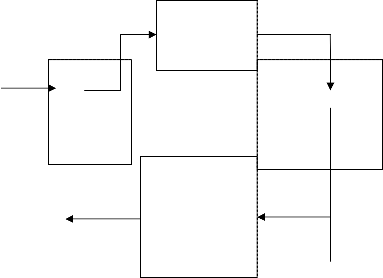
Input
large number of classes in which the transitionfrom one class to the next is practically continuous making it difficult to define hard class boundaries.
Pre processing
This stage is t o remove the noise
Classifier
characteristicallyreproduction with numerousphases of processing beginning images to surface to three-dimensional reproduction to matched representation. There are many reorganization model which is based on low level, two dimensional image processing.The principle components of original set of trained images are projected as face images in face regonization. The result of Eigen face is obtained by comparing by classification with known individuals. Obviously this is not factualat what time principal component ispractical to an absoluteface. A variety headpoint of reference, balancing, andillumination. Their images become visiblematchingor else with little difference in facial appearance, facial information, fake, etc. For illumination, direction, and balancedifference their organization attains
96%, 85% and 64% acceptablearrangementlikewise.
.
Template matching technique such as functions by the stagestraight correlation of image fragment. Templatematching is simplyefficientat what time the
Passing the
face image for system classification
Output
Indicates whether the input image present in the input or not
Classifies the output
for the corresponding input image
questionmetaphors have the same scale, orientation, and illumination asthe training images.
A large amount of the attendancejournalism on face detectionfrom side to side neural networks in attendancefalloutby means ofsimply a littlequantity of program. For illustration, the primary 50 majormechanism of the metaphors aretake out and concentrated to 5 magnitudesby means ofasedanassociative neural network. The consequentialillustrationis confidential using anaverage multi-layer perceptron. Good falloutisstatement but the record is quitestraightforward: the movies are physicallyassociated and there is no illuminationdifference, revolving, or oriented.
The both natural neural network and artificial neural network map are important part in information processing systems. Illustration of map in the nervous organization are the visual cortex of retinotopic maps, the auditory cortex of tonotopic maps, and maps beginning the skin on top of the somatosensoric cortex . The self- organizingmap, or SOM, introduced by Teuvo Kohonen isan unsubstantiated knowledge procedure which becomes skilled at theallotment of a deposit of exampleexclusive ofeverydivisionin sequence. A prototype is anticipated from aparticipationroom toa situation in the map - in sequence is implicit as the position of aset in motionjoin. The SOM is differentthe majority categorization or clustering procedure in that it make available a topological arrange of the lessons. Correspondence ininput prototypes is conserved in the productivity of the development. The topological conservation of the SOM procedure creates it especially useful in the classification of data which consist of a large amount of classes. In the localimage illustrationcategorization, for example, there may be a very
2D-DCT is computed for each face image and
discrete cosine transforms (DCT) coefficients used to form feature vectors. The second stage make use of a self-
organizing map (SOM) with an unproven learning method to categorizevectors interested incollections to distinguish if the subject in the key infigure is “present” or “not present” in the image database.Only depend on the classification result output say wheater the input image is present or not if the input is classified as present the corresponding image is present else the image is not present if the corresponding image is not in the set of input image.
Different and in wide variety of the application uses the
discrete cosine transform in varies fields. The most common thing for which we using the DCT is for data compression. The DCT has the property that, for a classic image, the majority of thevisually importantin sequence about the picture isdetermined in immediately a few coefficients. Take out DCTcoefficients can be second-hand as a kind of name that is functional foracknowledgment tasks, such as face identification. Face images contain high relationship and unneededin sequence which reason computational encumber in expressions ofhanding out speed and recollectionconsumption. The DCT alterimages from the spatial domain to the regularity domain. Sincejunior frequencies are further visually vital in an imagethan higher frequencies, the DCT discards high-frequencycoefficients and quantizes the residual coefficients. Thisreducein sequence volume by means of nogive up too a large amountof imagecharacteristic.
The som defined as all input space are mapped to form topological ordered set of nodes, normally in the form of
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue 1, January-2013 3
ISSN 2229-5518
S, which is used to obtain the location of s. the input vector is get updated with Som. The updated som are specified as
t = time for learning.
hci= neighborhood function
Normally hci (t) =h (|lc-li|, t) where lc, and li reprents the location of nodes in the output space of the SOM. lc is the
node which is closest weight vector to input sample s and li
ranges of overall nodes in the som output space.
lc-li 2
probabilities for input image through ,in an account 2D image with multi layer perception network as the input image, the translation or local deformation of the image with no invariance.The invariance is achieved by three ideas receptive field in local, shared and sub sampling with spatial. The number of parameter in this system help in the generalization by using shared weights. Convolutional set of connections have be presenteffectivelyuseful to qualityidentification.
AcharacteristicConvolutionalarrangement is shown in figure
4. The network consists of a set of layers each of which![]()
hci= α (t) exp |
2a2(t)
surrounds one or other planes. in the region of centered and
Where α (t) is a scalar valued learning rate and σ (t)
describes the width of the force. They are normallytogether monotonically fallingby means ofinstance. The make use of
the neighborhood reasonwealth that nodes which are topographically seal in the SOM arrangement are stimulated towards the input prototypethe length of with the winning node. This createsa flat effect which leads to a worldwidearranging of the map. Note that σ (t) be supposed to not be abridged too outlying as the map will lose its topographical arrange if neighboring nodes are not efficientthe length of with the closest node. The SOM can be careful a non-linear shelf of the probability density, p(x).
normalized of images come into at the input film. Everycomponent in a plane takes delivery of input from undersizedvicinity in the level surface of the preceding layer. The design of relatingelements to local receptive fields of imageyearbackside to the 1960s by means of the perceptron and Hubeland W iesel’s innovation of in the neighborhoodsusceptible, orientation-selective neurons in the cat’s illustrationorganization.The weights determiningthesociableargument for a smooth surface are necessary to be comparable at every onesituations in the levelplane.Eachlevel surfaceof the flat surface is measured as the characteristicdiagram which contain of undeviatingattribute detectorwith the significance of is convolved with a local window which is look atlarger than the flat surface in the preceding layer. Several planes are frequently used in everyfilm so that numerous features can
be detected. These layers are called Convolutional layers.
h hc3
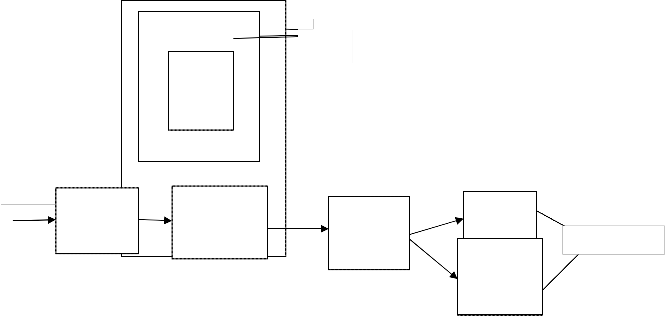
After detecting the feature of the image the space is considered as less important. So to overcome this we using
Image
The face reorganization problem from 2-Dimentional image is extremely well ill posed seems to be very difficult. There are so many models which set to the point of training image but it will not work to unseen images. In input image sometimes the traing images are not set or enough training Image create value of class
sampling
Feature
the additional thing in this paper to overcome the disadvantage this is back propagation gradient descent procedure. It is used to reduce the number of weight present in the neural network.
MLP
Som
extraction layer
classifier
Nearest neighborhood classifier
Classification
Our classification works as following steps
1) Consider the input image in the training place the window size which is fixed to an entire image set and local image steps are extracted in the each steps. The window is moved by 4 pixels.
2) A self organization map is with 3D and 5 nodes for each dimension, which is trained on the vectors
which is from previous stage. Thequantities of SOM are input vector with 25 dimensional into topological order value of 125.
3) The first step is repeated for all the images in the train set and testingsets. the local image sample are supplied to SOM at every step, Thesame
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue 1, January-2013 4
ISSN 2229-5518
window as in the first step is stepped over all of the images in thetraining and test sets, by the way creating the new training and test set in the output space created by the SOM.
4) A Convolutional neural system is qualified on the newly formed training location.
W e achieved a variety of research and in attendance the consequences here. excluding as soon as confirmed if not, all experimentation be carry out by means of 5 instruction metaphors and 5 examination metaphors for each human being meant for a full amount of 200 teaching metaphors and 200 experiment metaphors. Present be no not be separate connecting the teaching and assessment deposit. W e note down with the target of an arrangement which estimation the accurate respond would be correct single out of forty times, benevolent a fault speed of 97.5%. On behalf of the subsequent set of experimentation, we differ simply individual factor in every container. The fault bars exposed in the graphs stand for benefit or defect one standard deviation of the division of outcome from a numeral of replication. W e make a note of with the purpose of if possible we would like to have performed more simulations per reported result, however, we were limited in terms of computational capacity available to us. The constants used in all place of research exist as : amount of classes: 40, dimensionality decrease technique: SOM, magnitude in the SOM: 3, amount of nodes for each SOM dimension: 5, figure section extraction: imaginative concentration values, training metaphors for each class: 5. make a note of that the constants in every situate of testing may not present the greatestpromisingpresentation as the presentmost excellentperforming artsarrangement was simplyget hold of as a outcome of these testing. The consequencesspecifies that a Convolutionalset of connections can be additionalappropriate in the knowncircumstancesat what timeevaluatewith a regular multi-layer perceptron. This associateby means of the ordinaryfaith that the merging offormerinformation is attractive for MLP techniqueset of
connections the CN includefieldinformationon the subject of theconnection of the pixels and preferred invariance to a amount of conversion, scaling, and local deformation.
Above figure is output for all kind of emotion regonization
with accuracy of 85%.
W e got the accurate result for the dark and bright area with different kind of emotion.
Emotion /detection | Existing accuracy (%) | Proposed accuracy (%) |
Cheerful Joy full face Ejaculation Head down Bright image Dark image Kissing emotion | 54 56 59 61 62 66 62 | 80 82 85 86 82 88 87 |
W e containobtainable a quick, regular system for face identificationof all kind of emotion which is a grouping of a
restricted imagesectiondemonstration, a self-organizing map set of associations, and a Convolutional network for face identification.The self-organizing map supply a quantization of the image model into a topological mouthful of air spacewherever inputsthat are close by in the innovativegap are as wellto hand in the productivitygap, which conclusion in invariance toinsignificantchange in the image samples, and the Convolutional neural set of connectionsconstructobtainable for incomplete invarianceto alteration, rotary motion, scale, and deformation. Thetechnique is capable of rapid organization, require only fast, approximate normalization and preprocessing, and time after timeshow signs ofimprovedarrangementpresentation
than the eigenfaces approach on the database consider as the sum of images perperson in the training database is differentstarting 1 to 5. W ith 5 images for eachhuman being the proposed technique andeigenfaces product in 3.8% and
10.5% error correspondingly. The recognizers make available a measure of assurance inits constructing and
categorization error move toward zero when disallow as few as 10% of the examples. W e haveaccessibleopportunity for additionaldevelopment.There is no explicit three-dimensional demonstration in our system;on the other hand we have establish that the quantized localimage sample used as key intoward the Convolutional network stand for efficiently varying shading prototypes Higher level features are making from these construction blocks in consecutive layers of the Convolutional network. In evaluation by means of the eigenfaces approach, we think that the system offered at this
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research Volume 4, Issue 1, January-2013 5
ISSN 2229-5518
time is capable tostudy extra suitable features inarrange to present enhanced simplification. The organization is incompletely invariantto modify in the local image sample, balance, transformation and deformation by design.
16, NO. 1, APRIL 2007.
3) N.C. Yeo, K.H. Lee, Y.V. Venkatesh, S.H. Ong “Colour image segmentation using the self-organizing map and adaptive resonance theory” N.C. Yeo et al. / Image and Vision Computing 23 (2005).
4) M. Arfan Jaffar, Muhammad Ishtiaq, Ayyaz Hussain and
Anwar M. Mirza “Wavelet-Based Color Image
Computer Engineering and Applications IPCSIT vol.2 (2011).
5) Ivica Mari, Slobodan Ribari COMPARISON OF A BACK PROPAGATION AND A SELF ORGANIZING MAP NEURAL NETWORKS IN CLASSIFICATION OF TM IMAGES “International Archives of Photogrammetry and Remote Sensing. Vol. Supplement B7. Amsterdam 2000.
6) A.S.Raja and V. Joseph Raj“NEURAL NETWORK
7) Marco Vanetti, Ignazio Gallo, and Elisabetta Binaghi” Dense Two-Frame Stereo Correspondence by Self- Organizing Neural Network” 2005.
8) Jawad Nagi, Syed Khaleel Ahmed” A MATLAB based Face Recognition System using Image Processing and Neural Networks” 4th International Colloquium on Signal Processing and its Applications, March 7-9, 2008.
9) M. Hagenbuchner, A. Sperduti” A self-organizing map for adaptive processing of
10) Jorma Laaksonen, Associate Member, IEEE, Markus
Koskela, and Erkki Oja, Fellow, IEEE” PicSOM—Self- Organizing Image Retrieval with MPEG-7 Content Descriptors” IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 13, NO. 4, JULY 2002.
11) Dinesh Kumar “Dimensionality Reduction using SOM
MULTIMEDIA, VOL. 3, NO. 1, MAY 2008.
12) Mu-Chun Su and Hsiao-Te Chang “Fast Self- Organizing Feature Map Algorithm” IEEE
TRANSACTIONS ON NEURAL NETWORKS, VOL. 11, NO.
3, MAY 2000.
13) Dinesh Kumar, C.S. Rai, and Shakti Kumar “An
14) R.D.LAW RENCE G.S. ALMASI” A Scalable Parallel Algorithm for Self-Organizing Maps with Applications to Sparse Data Mining Problems” Data Mining and Knowledge Discovery (1999).
15) Steve Lawrence, C. Lee Giles, Ah Chung Tsoi2, Andrew
D. Back“A Scalable Parallel Algorithm for Self-
Technology 2007.
IJSER © 2013 http://www.ijser.org