• Select any newly released movie or the upcoming movie
product for prediction.
International Journal of Scientific & Engineering Research, Volume 4, Issue 9, September-2013 277
ISSN 2229-5518
A Model for Predicting Movie’s Performance using Online Rating and Revenue
Ms.Mary Margarat Valentine, Ms. Veena Kulkarni, Dr.R.R.Sedamkar
Abstract— Blog reviews,discussion forums, different type of social sites have created a new type of marketing and communication that connects the gap between simple word-of-mouth and a viral form of opinions which can move virtual mountains for a business. In the Movie Domain, a single movie can have the variation between millions of rupees of profits or losses for a studio in a given year. It’s not surprising, therefore, that movie studios are intensely involved in predicting the performance of the movies
This paper work proposes auto regression method and adaptive networks of fuzzy inference system model for the prediction of movie performance. ARSA model is implemented using two inputs and one output. Two Inputs are online sentiment ratings and box office revenue and the output is category of the movie. Proposed ANFIS System uses Fuzzy logic design: input, Fuzzificcation, inference engine, defuzzification, and output. There are many sales prediction methods but the use of history data will be most efficient way to predict the quality future. Both the regression method and Fuzzy rules are formulated and applied on 145 Bollywood movies which are released in the year of 2010 to 2013. The prediction result is calculated on the basis of auto regression and ANFIS model. Both the ARSA and ANFIS model’s output is compared with actual output .The prediction accuracy are measured for both the models using forecast accuracy methods MAPE and MSE.
Index Terms— Adaptive Networks, Artificial Intelligence, Blogs, Fuzzy Inference System, Prediction, Regression, Sentiment Analysis
—————————— ——————————
NLINE reviews are crucial to any business and becoming more imperative every day to manage reputation. Re- viewing plays the major role in the face of online market-
ing since the Internet became a household convenience which allows all businesses to have lively, positive participation from users and gives customers to create a relationship with those businesses.
Sentiment mining techniques can help researchers to study sentiments incorporated in reviews on the Internet by identify- ing and analyzing the texts containing feelings and opinions [2]. Those online reviews provide a wealth of information on the products and services, and if the information is properly utilized, can present vendor highly valuable network intelli- gence and business intelligence to make possible the im- provement of their business. As a result, online review mining has newly received a great deal of consideration. Since what the people thinks of a product can no doubt control how well it sells, understanding the opinions and sentiments expressed in the relevant online reviews is of high importance [4]. In this paper, actionable knowledge is created by building up models and algorithms that can utilize mined reviews from blogs. Such models and algorithms can be used to effectively predict the performance of products [5]. Previous research was con- ducted on the predictive power of reviews which considered the huge volume of reviews or link structures to predict the trend of product performance rather than the quality reviews to consider the effect of the sentiments present in the blogs [1], [3]. It has been reported that although there seems to exist strong correlation between the volume of reviews and sales spikes, using the volume or the link structures alone do not provide satisfactory prediction performance[1],[3]. Indeed, the sentiments expressed in the online reviews are more powerful than volumes of reviews.
Prediction of product performance is an extremely domain-
driven task, for which a deep understanding of a variety of aspects involved are important. In this paper, the movie do- main is taken as a case study, in which the different issues like modeling reviews, producing performance predictions, and obtaining an actionable knowledge. As the result, three differ- ent factors are identified which play a vital role in predicting the box office revenues in the movie domain, namely, user’s sentiments, past sales performance, and quality of the review. A framework is propsed for sales prediction with all those factors included. First factor is modeling sentiments in re- views, using text mining methods. Simply classifying reviews as positive or negative does not provide a comprehensive un- derstanding of the sentiments reflected in reviews [4]. S-PLSA focuses on sentiments rather than volume of reviews or topics. Therefore, instead of considering volume of reviews primarily focused only on the reviews that are sentiment related [7]. The second factor which is considered in this paper is the past sale performance of the same product, or in the movie domain, past box office performance of the same movie. Based on S- PLSA information, ARSA model is presented for predicting movie sales performance by considering the input factors sen- timent ratings and box office revenue. No standard methods exist for converting human knowledge or experience into rulebase and a fuzzy inference system [6]. Fuzzy Inference System is implemented in the framework of adaptive net- works with the help of Review mining and sentiment analysis along with box office revenue.
Movie domain is considered as an input, because information related to the movie and revenue information, are easily avail- able. The movie information which is used for conducting ex- periments includes two factors.
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 9, September-2013 278
ISSN 2229-5518
1. The first factor is a set of blog reviews on movies which are of interest, collected from the Web.
2. Second factor contains the corresponding revenue data for these movies.
From the recent studies regarding writing the reviews, online opinions, online comments, discussion forums, the most stakes is taken by film industry which includes videos, songs, movies, television programs etc. So it is very simple to get the clear review about various movies after or before its release. If the prediction is focused on electronic goods, then it is re- quired to consider different companies/brands, but here for movie domain it is possible to get exact amount of the box office revenue information. So it will help in predicting sales with the help of earlier data. The movie review data set is ob- tained from different websites. The publicly accessible website for movie reviews is IMDB Website.
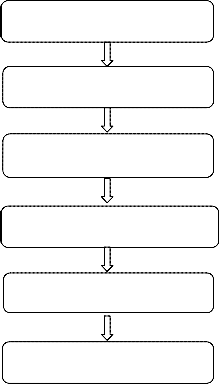
Flow for the proposed system is as shown in the Figure 1, i.e.
• Select any newly released movie or the upcoming movie
product for prediction.
Select any movie for prediction
Extracts reviews from blogs using sentiment analyzer
• The second input will be the box office revenue of the mov- ie in rupees. It will be taken from the websites, according to the week wise collection after the release of the movie.
• Both the inputs are given to ARSA and ANFIS model for sales prediction.
• The output for the pair of above input will be the final cat- egory of the movie, defined in different categories of the movie starting from Disaster to All Time Blockbuster.
With the rapid growth of posting comments and reviewsrelat- ed to the product, review mining has involved a great deal of consideration. Prior studies in this area were mainly focused on deriving the sentiment reviews [2].
The movie review data set was obtained from the publicly accessible IMDB Website. Specifically, collected the reviews for movies released in the bollywood. Snapshot [17] of English Vinglish movie review is shown the Figure 2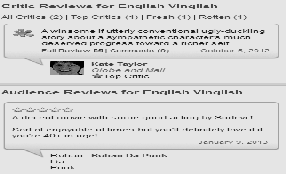
Figure 2. Snap Shot of a Movie Review
Box office revenue from websites
Train the ARSA & ANFIS Model
Measure Prediction accuracy
Compare the Results
Figure 1. Block Diagram for proposed System
• Extract the reviews from different blogs for sentiment analysis.
• For data analysis, bollywood movies are considerd and its revenue and rating are collected before and after release.
• The first input will be the rating of any movie after senti- ment analysis [12].
Many existing models and algorithms for sentiment mining are developed for the binary classification problem, i.e., to classify the sentiment of a review as positive or negative. However, sentiments are often multi-faceted, and can differ from one another in a variety of ways, including polarity, ori- entation, graduation, etc. Therefore, for applications it is nec- essary to understand the opinions accurately. Here extraction of ratings starts with modeling sentiments in online reviews, which presents unique challenges that is not possible to be easily addressed by conventional text mining methods by classifying reviews as positive or negative, as most current sentiment mining approaches are designed for, does not pro- vide a comprehensive understanding of the sentiments reflect- ed in blog reviews [7].To organize the model of a variety of natures of complicated sentiments, sentiments are analyzed which is embedded in reviews as a result of the combined role of a number of hidden factors. To evaluate hidden factors which are present in reviews posted by customers, a new ap- proach is used to review mining based on Probabilistic Latent Semantic Analysis (PLSA), which is called as Sentiment PLSA. It would be too simplistic to just classify the sentiments ex- pressed in a review as either positive or negative. Moreover, mining opinions and sentiments present unique challenges that cannot be addressed easily with traditional text mining
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 9, September-2013 279
ISSN 2229-5518
algorithms, due to the fact that opinions and sentiments, which are usually written in natural languages, are often ex- pressed in subtle and complex ways. All these concerns call for a model that can extract the sentiments in a more accurate manner. To this end, Liu et al. [3] [9] propose the S-PLSA model, in which a review can be considered as being generat- ed under the influence of a number of hidden sentiment fac- tors [8]. Inspired the PLSA model [4], [5] the use of hidden factors in S-PLSA provides the model the ability to accommo- date the intricate nature of sentiments, with each hidden factor focusing on one specific aspect [10].
Box office revenue is taken as the second input in this pa- per. Along with the sentiment rating, box office revenue site collected from boxofficeindia.com and koimoi.com websites are used for predicting movie performance. A product can attract a lot of attention (thus a large number of blog mentions) due to various reasons, such as aggres- sive marketing, unique features, or being controversial. This may boost the product’s performance for a short peri- od of time. But as time goes by, it is the quality of the product and how people feel about it that dominates. For that reason instead of taking the first day or first week box office collection, average collection is considered.
For this Existing regression model, the author focused on extracting sentiment information from the public reviews incorporated in the online blogs. From the above cited work, reviews are used for predicting product sales per- formance. Based on study of the compound nature of sen- timents in the reviews, they proposed S-PLSA, in which a entries in the blog is analyzed as a document created by a number of unknown sentiment factors. As a result of train- ing the model, sentiment’s summary is obtained from the blogs. That sentiment’s summary which is retrieved from the PLSA method is given as the input to the ARSA model, for prediction. Wide ranges of testing were conducted on a movie data set. Then Comparison is done by including sen- timents and in the absence of sentiments.
In Summary,
• First, Input and Output factors are decided for predic-
tion using ARSA model.Here in this paper, Ratings of
the movie and Box office revenue are the input factors
of the movie and output factor is the Category of the
movie.
• Ratings can be collected either from S-PLSA model or
IMDB website.
• Box office revenue generation is easily available on the
internet and revenue information is collected from
those websites.
• Training the ARSA model based on the Input factors
and output category is calculated.
• Now the result is used to analayzed to calculate predic-
tion accuracy and the error rate.
• For comparison, same procedure is followed using sen-
timent information and the absence of sentiment in-
formation.
The architecture and learning procedure underlying ANFIS is propsed, which is fuzzy inference system, implemented in the frame work of adaptive networks. The proposed ANFIS can construct an Input-output mapping based on human knowledge. Basic aspect of this model is that standard tech- niques are not existed for converting human knowledge or experience into the rule base and database of a fuzzy inference systemand there is a need for efficient methods for tuning the membership functions to reduce the output error measure or increase the performance index. In this perception, the objec- tive of this paper is to propose a new architecture design known as Adaptive Network based Fuzzy Inference System (ANFIS), which is used as a source for the construction of a set of fuzzy if-then rules with proper membership functions to create the set of input-output pairs. Sugeno model is shown in the Figure 3.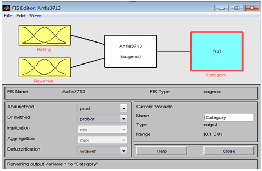
Figure 3. Two Input-Output Sugeno Model
The movie data which is proposed to conduct experiments consists of two components. The first component is a set of blog documents on movies which are of interest, collected from the Web, and the second component contains the cor- responding daily box office revenue data for these movies. Predicting sales performance is done with the help of dif- ferent factor like, past box office performance, box office collection and main important factor is online reviews which are present on different movie websites. After col- lecting the reviews/comments from different web sites/blogs/discussion forums [16], [17], [18], [19], it will be analyzed by the sentiment analyzer tool [19] so that proper rating is retrieved by considering the sentiment factor pre- sent in the online reviews. Here we will obtain the overall probabilistic sentiment rating of the movie based on the comments/reviews through the analyzers then and the box-office revenue will be the inputs for the proposed sys- tem. Once we obtain the overall ratings of the movies, and the box-office collection then these two components will act as the input for the proposed learning model and the pre- dicted output will be the categorization of the movie in the predefined linguistic type. Table 1 show the input and out- put factor for the prediction. Ratings and Revenue is consid-
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 9, September-2013 280
ISSN 2229-5518
ered as an input and output will describe the category of the movie.
TABLE 1
INPUT-OUTPUT FACTORS FOR PREDICTION
RATING | REVENUE | CATEGORY |
Poor | Small | Disaster |
Mediocre | Average | Flop |
Average | Medium | Below average |
Decent | Good | Average |
Good | Very Good | Hit |
Very Good | Better | Super hit |
Excellent | Best | Block buster |
Superb | Excellent | All time block buster |
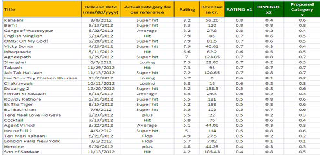
Figure 4. Snapshot of Input - Output data taken for the proposed system
Based on the Input – output factors shown in the table 1, Input and output data are collected for the bollywood movies from online to implement the proposed prediction model.Snapshot of input-output data taken for impementation is shown in the Figure 4.
Adaptive Neuro fuzzy inference system (ANFIS) is a kind of neural network that is based on Takagi–Sugeno fuzzy infer- ence system [6]. Ever since it integrates commonly neural net- works and fuzzy logic principles, it has feasible to capture the benefits of together in a single framework. Its inference system corresponds to a set of fuzzy IF–THEN rules that have learn- ing capability to approximate nonlinear functions. [13] Hence, ANFIS is considered to be universal approximator. ANFIS can construct an input–output mapping based on both human knowledge in the form of fuzzy if-then rules with appropriate membership functions and stipulated input–output data pairs. The rule based system for the current prediction model is shown in the Figure 5.
Figure 5. Anfis Model Architecture – Rule based System
It applies a neural network in determination of the shape of membership functions and rule extraction. ANFIS architecture uses a hybrid learning procedure in the framework of adap- tive networks. This method plays a particularly important role in the induction of rules from observations within fuzzy logic. The convention of artificial intelligence has been applied broadly in a large amount of the fields of computation studies. Main feature of this concept is the ability of self learning and self-predicting some desired outputs. The learning may be done with a supervised or an unsupervised way. Neural Net- work study and Fuzzy Logic are the basic areas of artificial intelligence concept. Adaptive Neuro-Fuzzy study combines these two methods and uses the advantages of both methods.
The output of the ANFIS is calculated by employing the con- sequent parameters found in the forward pass. The output error is used to adapt the premise parameters by means of a standard back propagation algorithm. Box office revenue will be collected from the IMDB website [16] and different blog entries to find the probability of the sentiments.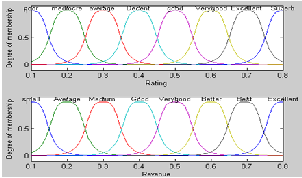
Figure 6. Memebership Functions for Rating and Revenue
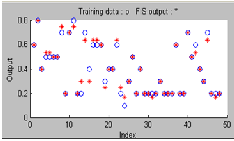
Figure 7. Training Error
The two input memebership functions of the proposed model and training error is shown in the Figure 6 and Figure 7 re- specdtively.On the basis of these two inputs, prediction of upcoming movie will be done through ARSA model. The mean absolute percentage errors (MAPE) and Mean Squared Error (MSE) will be used to measure the prediction accuracy.
which can be represented as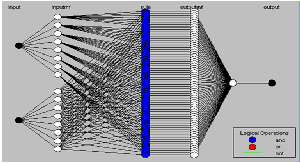
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 9, September-2013 281
ISSN 2229-5518
1
![]()
MAPE =
n
((Y
- F ) / Y ) *100
∑ t t t
t =1
In this paper, the model of predicting sales performance of a
movie is implemented using sentiment information mined
1
![]()
MSE =
(Y - F ) 2
from reviews and box office revenue. This model is explored
N ∑ t t
For the above learning model many possible training samples can be taken from the movies which are released from 2010 -
2013.
The extensive use of online reviews and comments as a way of conveying opinions and views has provided a distinctive op- portunity to identify with the user’s opinions and obtain busi- ness intelligence. In this paper, the predictive power of com- ments and sentiments incorporated in the reviews are in- vesttigated using the movie domain as a case study, and im- plemented the problem of predicting sales performance using sentiment information mined from reviews. As mentioned in this paper, we are predicting the performance of a particular movie by considering two important input factors like, senti- ment information incorporated in online reviews and box of- fice revenue of that particular movie and from different web- sites.
as a domain-driven task, and managed to produce human
intelligence (identifying imperative characteristics of online
reviews related to movie), domain intelligence (the knowledge
of movie and box office revenues), and network intelligence
(online reviews posted by public users). The result of the pro-
posed model leads to an actionable knowledge that can readi-
ly used by decision makers to decide the awards for the mov- ies and can make the critical business decisions better and it yields to significant competitive advantages in the entertain- ment industry.
It is worth noting that, only two input factors are used for prediction in this paper. For future work, this present system can be enhanced by considering few more inputs like budget of the movie (promotional budget & production budget), CBFC rating, movie genre, targeted audience of the movie to improve the accuracy and quality of the prediction. It would also be interesting to enhance the systemto keep a track and monitor the current trends and changes in sentiments posted in the blogs.
TABLE 2
MEASUREMENT OF PREDICTION ACCURACY USING MAPE & MSE
M ethod | ARSA | ANFI S |
MAPE | 0.2747 | 0.0160 |
MSE | 3.8548e-005 | 3.5025e-005 |
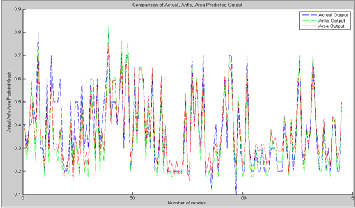
Figure 8. Comparison of Predicted Vs. Actual output
Figure. 8. Shows the precited output of the movies which is released in the bollywood and the comparison of the proposed oupt, ARSA output and ANFIS output is also shown. From the Table 2, it is clearly shown that Anfis is giving the best predic- tion performance when compared to ARSA error accuracy. From the prediction accuracy, it is easy to state that propsed model can work well as a very good prediction system for deciding product performances for future mov- ies.
[1] D. Gruhl, R. Guha, R. Kumar, J. Novak, and A. Tomkins, “The Predictive Power of Online Chatter,” Proc. 11th ACM SIGKDD Int’lConf. Knowledge Dis- covery in Data Mining (KDD), pp. 78-87, 2005.
[2] Rubicon Consulting, “Online Communities and Their Impact on Business: Ignore at Your Peril,” 25 Mar. 2009; http://rubiconconsulting.com/downloads/whitepapers/Rubiconwebomm unity
[3] D. Gruhl , R. Guha, D. Li ben-Nowel l, and A. Tomki ns, “ Informati on Di ffu-
si on through Bl ogspace,” Proc. 13th Int’l Conf. World Wide Web (WWW), pp.
491-501, 2004
[4] Xiaohui Yu, Yang L iu, “ M ining Onli ne Revi ews for Predi cti ng Sal es Per- formance: A Case Study i n the M ovie Domai n” , IEEE Transacti ons on Knowl edge and Data Engineeri ng, Vol . 24, No. 4, APRIL
[5] Y. Liu, X. Huang, A. An, and X. Yu, ―ARSA: A Sen-ti ment-Aware M odel for Predi cti ng Sales Performance Us-i ng Bl ogs,‖ Proc. 30th Ann. Int‘l ACM SIGIR Conf. Re-search and Development in Information Retrieval (SIGIR), pp. 607-
614, 2007
[6] Jyh-Shi ng roger Jang, “ ANFI S : Adaptive-Network-Based fuzzy Infer- ence system”, IEEE Transacti ons onSytems, Man and cyberneti cs, pp.No
665-685, VOL 23, No.3,May/June 1993
[7] T. Hofmann, “ Probabi li sti c Latent Semantic Anal ysi s,” Proc. Uncertai nty i n
Arti fi cial Intelli gence (UAI ), 1999.
[8] Thomas Hofmann and Jan Puzi cha. Latent class model s for collaborati ve fi lteri ng. I n IJCAI, pages 688–693, 1999.
[9] J. Liu, Y. Cao, C.-Y . Li n, Y. Huang, and M. Zhou,“ Low-Quali ty Product Revi ew Detecti on in Opi ni on Summari zati on,” Proc. Empiri cal M ethods i n Natural Language Processi ng and Computati onal Natural Language L earn- ing (EMNL P), pp. 334-342, 2007.
[10] C. Elkan, M ethod and System for Sel ecting Documentsby M easuring Doc- ument Quality. US patent 7,200,606, Washi ngton, D.C.: Patent and Trade- mark Offi ce, Apr.2007.
[11] Li Zhuang “ M ovie Revi ew Mi ning and Summari zati on” ,Mi crosoft Re-
IJSER © 2013 http://www.ijser.org
International Journal of Scientific & Engineering Research, Volume 4, Issue 9, September-2013 282
ISSN 2229-5518
search Asia Department of Computer Sci ence and Technol ogy, Tsi nghua
University Beiji ng
[12] A. Ghose and P.G. I peiroti s, “ Desi gni ng Novel Revi ewRanki ng Systems: Predi cting the Useful ness and Impact of Revi ews,” Proc. inth Int’ l Conf. Electroni cCommerce (ICEC), pp. 303-310, 2007.
[13] P.D. Turney, “ Thumbs Up or Thumbs Down?: Semanti c Orientation Ap- pli ed to Unsupervi sed Classi fi cati on of Revi ews,” Proc. 40th Ann. M eeting on Assoc. forComputati onal L ingui sti cs (ACL), pp. 417-424, 2001.
[14] J. Kamps and M. Marx, “ Words wi th Attitude,” Proc.First Int’ l Conf. Global
WordNet, pp. 332-341, 2002.
[15] Nedjah, Nadia, ed. Studies i n Fuzzi ness and Soft Computing. Germany: Springer Verlag. pp. 53–83.ISBN 3-540-25322-X.
[16] B. L iu, M . Hu, and J. Cheng, “ Opi ni on Observer: Anal yzi ng and Comparing
Opi ni ons on the Web,” Proc. 14th I nt’ l Conf. World Wi de Web (WWW), pp. 342-351, 2005.
[17] http://www.rottentomatoes.com/m/engli sh_vi ngli sh/
[18] http://www.mouthshut.com/Hi ndi -Movi es/3-I di otsreviews-925106887 [19] http://www.i mdb.com/titl e/tt1187043/revi ews
[20] http://www.cs.bham.ac.uk/~axk/Assi gn1.doc
[21] http://senti ment.brandli sten.com/anal yse
[22] http://social mediatoday.com/sector45/1433331/why-onli ne-revi ews-matter
[23] http://theonli nedepartment.com/8-reasons-why-online-revi ews-are- important-to-your-busi ness/
[24] http://knowl edge.brandi fy.com/why-onli ne-revi ews-are-i mportant-for-your- business/
• Mrs.Veena Kulkarni is currently working as a Assistant Professor in Thakur- College of Engineering & Technology, Mumbai
• Dr.R.R.Sedamakr is working as a Professor, Dean in academics, HOD-CMPN
in ThakurCollege of Engineering & Technology, Mumbai
IJSER © 2013 http://www.ijser.org